BW has built-in data-mining capability that lets you perform many types of customer analytics without having a full mySAP CRM implementation. Find out how BW's seven data-mining tools and their associated models can help you answer key questions about your customers.
Think of an aspect of your business where you feel cost could be minimized or revenue enhanced: the launch of a new product, more efficient and targeted marketing, understanding customer retention patterns over time, or pricing new or existing products. All present opportunities for data-mining analysis.
Data mining is useful to all industries. For example, improving the customer retention rate is a universal goal. Telecommunications companies call it “churn management;” banks call it “attrition management.” Weeding out bad or unprofitable customers is also a cross-industry challenge that can be addressed with data-mining tools. Data-mining tools are generally a set of specific algorithms that crunch large volumes of data to identify and present patterns in that data. They can, for example, help to answer these questions:
- Which customers should have their loan or credit card application rejected?
- Which customers should be offered different payment terms?
- Who should wait on hold the longest?
SAP has delivered a set of data-mining tools with BW since Release 2.1C, Support Pack 08. These tools are underused and almost unknown. What follows is an overview of the available BW data-mining tools followed by two real-world examples of how I put two of them—Decision Trees and Scoring—to use.
The BW Data-Mining Tools
These tools have been steadily improved, and the BW 3.2 content release now provides this solid set of business analysis tools and related Business Content. Table 1 provides more information on each tool:
- RFM (Recency, Frequency, and Monetary response rate measurement)
- CLTV (Customer Lifetime Value analysis)
Data-Mining Tool
|
Transaction Code
|
Overview
|
Reason to Use
|
| ABC Analysis |
RSDMWB |
A great simple starting point to categorize customers into A, B, or C dependent on a single key figure value. |
Every company should be able to identify its top 20 percent of customers in terms of revenue and margin. |
| Scoring |
RSDMWB |
More complex than ABC Analysis, but it attempts the same thing: score/categorize the customer. Here, though, the categorization can be based on multiple key figures or customer attributes (weighted scores) or linear and non-linear regression. |
Complex customer scoring requirements— e.g., associated with some sort of loyalty program. |
| Decision Trees |
RSDMWB |
Simple but powerful data-mining tool that is very popular, probably due to its ease of setup. |
When you want to see patterns in customer behavior (or non-behavior). |
| Clustering |
RSDMWB |
Groups or clusters similar customers together based on an assessment of “n” attributes and key figures linked to the customer. |
When you are not sure what you are looking for. |
| Association Analysis |
RSDMWB |
Similar to market basket analysis, this model is focused on products rather than customers. |
When you want to see which products sell well together for a certain group of customers (for example, when defining cross-selling rules at point-of-sale or for a telesales agent). |
| RFM |
RSAN_RFM |
RFM is a marketing database concept that considers a customer's likelihood to respond to a campaign to be highly correlated to recency of purchase, somewhat correlated to frequency of purchase, and amount of money spent. Customers can be allocated to RFM segments in SAP BW based on data about the customers' purchase history response to prior campaigns. |
When you want to filter a campaign target group based on the target audience's likelihood to respond (thereby improving the profit/ROI of the campaign). The BW transaction is tightly linked to operational CRM and the
campaign/channel optimization functionality of mySAP CRM 4.0. |
| CLTV |
RSAN_CLTV |
CLTV models analyze customers' contributions over time and predict their contributions in the future. The model needs only five pieces of information to run: customer ID, customer segment (age range/industry), date customer first transacted, month of each transaction, and (ideally) profitability of each transaction. |
Attempts to answer two questions:
1. How many customers do I retain from one
lifetime period to the next?
2. What is the average contribution
of the customer over time?
|
| Table 1 |
BW data-mining tools at a glance. BW provides wizard assistants for all but RFM and CLTV. |
These tools do not replace a full-scale SAS E-Mining implementation (BW does not deliver neural network technology, for example), but for many companies they offer a practical means to gather insight. The BW data-mining tools are independent of, but tightly integrated with, mySAP CRM 4.0. This combination allows you to take immediate action on the data-mining results without building a separate interface. You do not need mySAP CRM 4.0 to use these tools, however.
In addition, BW 3.2’s standard Business Content includes 10 data-mining models. A model is what you create using these tools. For example, you could have three Decision Tree models: one to evaluate response to a campaign, one to evaluate customer likelihood to purchase a certain product, and one to identify likelihood to default on payment. These models are fed by standard Business Content queries. Both the models and the queries can be activated by the standard BW Business Content install procedures. In addition, the data-mining transaction can now be accessed via a button within the Administrator Workbench.
You can address every data-mining opportunity mentioned earlier using one or more of the BW data-mining tools. To analyze customer churn, for example, you might use the Decision Trees and Clustering models (to identify a commonality in the attributes of those customers who leave, or conversely, remain loyal). You could follow with the ABC, Scoring, or CLTV models (to confirm that the customers who are likely to leave are valuable and worth saving).
For information on how to run and interpret these data-mining models, see the SAP online help documents or go to https://service.sap.com/crm-analytics.
Deciding which data-mining model makes sense for a given opportunity within your company requires experimentation. Start with a clear business benefit in mind before you begin a data-mining exercise. If this is your first venture into data mining, focus on one or two of the BW models (ABC, Scoring, and Decision Trees are the easiest) and apply them to as many business opportunities as you can think of.
All BW data-mining models are fed by data from InfoCubes/ODSs via a standard query. This does not mean that you can plug existing BW queries straight into a BW data-mining model, although these queries are a great start.
The hardest aspect of data mining is getting the data into the right format. For example, historical customer sales transactions for a car model do not necessarily provide a value for a data column like, “Did the customer purchase car model X?,” which is populated with a value of “yes” or “no.” In data-mining speak, this value is called the “predictive field,” and it is critical when running a Decision Trees model. BW offers Query Builder and restricted and calculated key figures to populate a predictive field.
Two practical use cases for data mining from my experience in the Asian auto industry follow. In principle, you can apply the same tools used in these examples to other scenarios in industries such as retail, consumer products, airlines, telecommunications, and financial services. Rather than focus on creating the actual data-mining model, I will focus on modifying a common BW query to the data-mining format. SAP’s online help and Model Creation wizard are adequate guides for building the model.
Practical Use Case 1: Customers Most Likely to Buy
Analysis opportunity: Identify the type of customer likely to buy a certain model car. This helps to better target future marketing programs and therefore improve campaign ROI. In addition, dealers could use this customer behavior information at point of sale to drive revenue.
BW data-mining model used: Decision Trees
Requirements: To understand which customers are likely to buy a Futura model car, I will use historical sales data. I will populate the query rows with as many customer attributes as I can find in the BW master data (they do not necessarily have to be navigable attributes). These attributes might include postcode, age range, income, profession, returns quantity, or number of complaints. Any or all of these attributes could end up being associated with the customer’s likelihood to purchase, and they need to be fed into the Decision Trees model during model creation. The strength of the link between an attribute value and the likelihood to purchase is determined by the Decision Trees algorithm itself during run-time.
Data-mining source BW query and model setup: I need to create a predictive field for the Decision Trees model to run. The best predictive fields are binary in nature (e.g., “Purchased car?” “Yes” or “No;” or “Responded to a campaign for Product X?” “Yes” or “No”). A predictive field may have more than two values in it, however.
This is the best way I have found to realize a result in a query display that conforms to data-mining input: To calculate a predictive field for this sort in the query, I must create two new key figures (Figure 1). First, I create a restricted key figure (e.g., “Show me only sales quantity for model Futura”), and then I create a calculated key figure using the Count Data function in the Formula Builder based on the restricted key figure. This calculated key figure then populates with a 1 if the restricted key figure is non-zero, or with a 0 if the restricted key figure is zero. This calculated key figure in the query can now be used as the predictive field. The fact that 1 represents “yes” or “did buy” and 0 represents “no” or “did not buy” can be defined at a later stage.
Note
A solution based on formulas or macros in Microsoft Excel (or using key figure display properties) is not useful as the BW data-mining model reads only the query result.
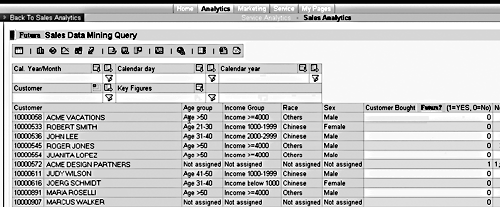
Figure 1
Query (viewed via a Web report) with a predictive field for the Decision Trees model analysis: Which type of customers will buy a certain model car?
Practical Use Case 2: Customer Loyalty
Analysis opportunity: I want to score all customers based on their prior sales and service transaction history as part of a customer loyalty and recognition program. The most valuable customers (high scorers) will be offered a loyalty card that grants them benefits at all service centers. Their subsequent loyalty will then be tracked as a measure of success for this initiative.
BW data-mining model used: Scoring with weighted score tables
Requirements: Customers get points depending on which model car they purchased over the last four years. The points depreciate by 20 percent every year. In addition, customers get one point for every dollar spent on service, except for insurance-related service, for which every customer gets 500 points for the year (because that is the out-of-pocket expense/premium the customer pays). Service points depreciate every year.
Data-mining source BW query and model setup: A lot of the intelligence to meet this requirement is handled in the BW query design rather than in the Scoring model. However, the flexibility of the Scoring model and its ability to write the score output to BW master data make it worthwhile for this requirement.
To determine sales points, a standard sales query with customer and car model code in the query rows (with a key figure of quantity purchased) serves as the input/source query. I then define a Scoring model that assigns a certain number of points to each model of car (Figure 2). To handle the requirement for depreciation of points, I create separate queries that filter the sales quantity per model—for example, “sales greater than 12 months old but less than 24 months old.” This filtered query then feeds a second data-mining model (copied from the first) with the same scores assigned per car model, but with a different weight of Scoring model field applied (0.8 rather than 1).
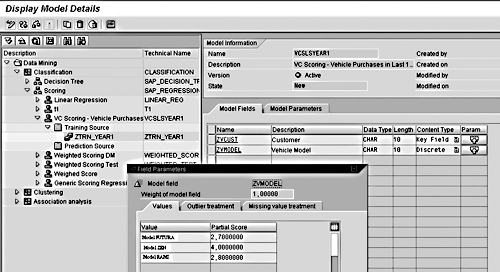
Figure 2
Weighted Score model based on customer sales history and a score given for each car model purchased. Note that the value in the Weight of model field is set to 1. To handle the depreciation of points, this field is set to 0.8 when it is fed by a sales query for customer sales greater than 12 but less than 24 months old.
The query to determine service points is more complex (Figure 3). The first key figure (KF1) is the total service dollar amount spent by the customer across all years excluding insurance (IN) jobs. This is for information only. Columns KF2 to KF5 are restricted key figures, breaking out the total dollars spent into each year (last 12 months, greater than 12 months but less than 24 months, and so on) excluding insurance jobs. The Cal. Year/Month filters use standard, system-filled variables with offsets.
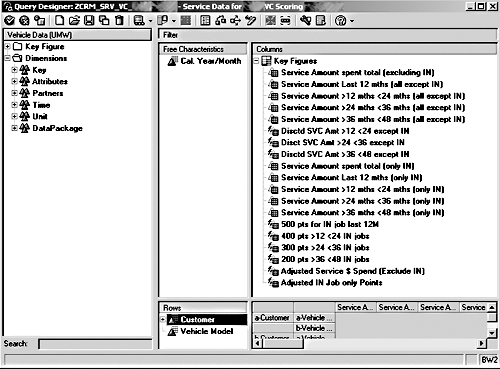
Figure 3
Restricted and calculated key figures for the points calculation based on service history
Columns KF6 to KF8 are calculated key figures that apply a discount factor to the older service dollar amounts in line with the requirement (20 percent reduction each year). The next key figure (KF9) is the total service dollar amount spent by the customer across all years just on insurance (IN) jobs. Again, this is for information only. Columns KF10 to KF13 are restricted key figures, breaking out the total insurance dollars spent into each year.
Columns KF14 to KF17 are calculated key figures, but this time I use the Count Data function in Formula Builder where any non-zero amount in KF10 to KF13 is registered as a 1. I then multiply all the 1’s in the last 12 months by 500, by 400 if they are older than a year, and so on. Finally, columns KF18 and KF19 are, respectively, the sum of service dollars spent excluding IN and discounts (KF2+KF6+KF7+KF8), and the sum of IN job values (KF14+KF15+KF16+KF17). The service Scoring model is then run on KF18 and KF19 where one point is given for each adjusted/discounted dollar spent.
I then run all models (one for each year of sales history—four in total—and one for the service history) and use them to update a “total score” attribute on the business partner master data in BW. (A standard upload program for the business partner master data is accessible via a button called BW Update within the data-mining model). This business partner master data list is then sorted, and invitations are sent to the high-scoring, most valuable customers.
The list itself is sent to an SAP CRM system for execution via the Campaigns functionality (using email, fax, letter, SMS send, tracking, and so on). This is another good example of the possibility of taking action in mySAP CRM based on analysis in BW.
Mark Heffernan
Mark Heffernan is a managing consultant in the CRM and BI Business Development division of SAP Asia. Mark is responsible for the implementation of mySAP CRM and BW across all industry sectors and countries in Asia, participating in key implementation projects such as Sony Playstation.com, Samsung Electronics, and Unilever. Before joining SAP, Mark worked in Andersen Consulting’s (now Accenture) SAP Core Group as a process and change management consultant in SAP implementation projects.
You may contact the author at editor@biexpertonline.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.




