See some examples of integration solutions based on SAP-provided replication tools that you can use to integrate SAP and non-SAP applications. The tools support a wide variety of data types (structured and unstructured) and formats (including data streams).
Key Concept
The new SAP HANA replication and consolidation capabilities can simplify the architecture of the solution and optimize the data transfer and transformation process. You can almost freely define processes and their execution using SAP HANA technology. The optimization often may require additional development effort by experienced architects and developers.
Let’s start with a presentation of some example data replication solutions using functionality presented in my previous article “Managing Data with SAP Data Replication and Transformation Tools.” They are SAP Landscape Transformation Replication Server (SAP LT Replication Server), SAP Data Services, and SAP Event Stream Processor (SAP ESP).
Then I present the data replication and integration capability provided by SAP HANA: SAP HANA smart data access, SAP HANA streaming analytics, and SAP HANA smart data integration.
I close with an example of how to use the new SAP HANA replication tools to integrate various data sources ? SAP business applications, unstructured data provided in files, streams delivered by smart devices, and Big Data storage solutions such as Hadoop.
Depending on your use case and complexity, you can consider which options are more valuable for your enterprise solutions. You need to consider the complexity of your enterprise landscape and the required replication and transformation functionality to choose the right replication tool. For example, you may use SAP HANA to support data replication and integration use cases in a simple landscape, but in a more complex landscape, you may use a centralized replication solution based on SAP replication tools.
I also present the aspects that you need to consider to avoid wrong or not properly working solutions that have performance or functional problems related to data consistency.
Use Cases for Data Replication and Transformation
Tools provided by SAP can be used for data replication and transformation in a complex enterprise landscape where the sources and target systems could be running in hybrid local, on-premise, and managed or public cloud data centers. Business-relevant data can be located in SAP and non-SAP business applications.
Often the enterprise architecture includes less invasive solutions. A new business application could be running side by side with the current core solution component?for example, the sidecar deployment solution. The existing SAP ERP Central Component (ECC) system could be extended by running new business applications on SAP HANA in parallel. That includes the so-called accelerator or analytic applications running on SAP HANA and native SAP HANA applications (applications developed using SAP HANA capability and technology and deployed directly in SAP HANA).
Another typical example in SAP BW powered by SAP HANA or SAP BW/4HANA is running a sidecar deployment allowing additional consolidation of SAP HANA capabilities and the SAP BW-provided reporting capability. SAP BW powered by SAP HANA and SAP BW/4HANA allow you to consolidate data in an online application programming (OLAP) environment supported natively in real time instead of batch-oriented data operational processing and reporting.
Figure 1 is an example of the replication and transformation architecture of SAP and non-SAP business solutions and the side-by-side running of a new business solution. Business data is created as an integration of source data using the SAP Landscape Transformation Replication Server (SAP LT Replication Server) and SAP Data Services solutions.
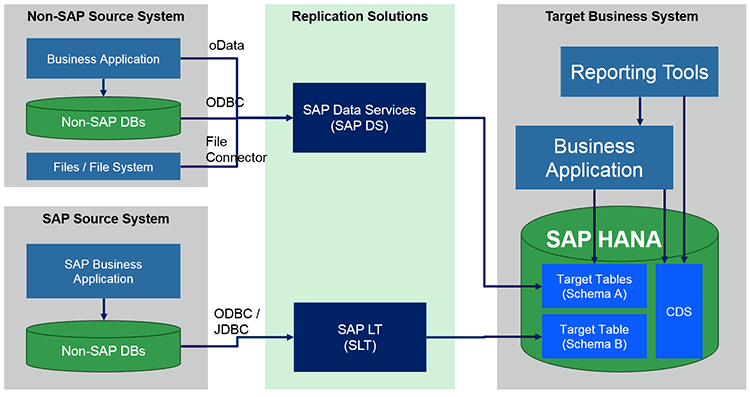
Figure 1
Replication architecture using SAP LT Replication Server and SAP Data Services
The SAP LT Replication Server is used to replicate business data into the side-by-side business application on SAP HANA on the database/table level. The real-time replication with less data conversion guarantees that the business data as defined in the SAP system is then used as the base or skeleton (as presented in this use-case) for the business functionality provided by the new business solution.
SAP Data Services is a batch-oriented solution mainly used to replicate data from a SAP and non-SAP business solution with extensive data transformation to the target business application. Therefore you may decide that the data needs to be converted to the required target SAP-aligned data format. In my presented use-case the SAP Data Services are used extend the base or skeleton business data replicated by SAP LT Replication Server and combine them to new business format that is used by the business application logic in target system.
To simplify the solution you can use tables as a source of the SAP Data Services-based replications, the business data provided by the external application programming interface (API), such as Open Data Protocol (OData), and unstructured data stored in files that are linked to the transactional and structured data in the business application. The business data provided by OData very often has more value because present the data from business level perspective. This means, the data provided in this level contains the information including the business logic and business-relevant customization.
The target tables of the data replication of the SAP LT Replication Server and SAP Data Services solutions can be separated, to avoid conflicts and inconsistence in the target business data persistence. For example, you may define the tables with the structure required by the target business solution using naming or schema separation to avoid accessing/writing at the same time from both replication tools and its processes: SAP LT Replication Server and SAP Data Services.
Figure 1 shows a schema separation as an example. The separation may help to achieve a consistent data replication independent of the replication type (real time, batch, or scheduled) and frequency. In my example, the data replicated from the SAP source system using SAP LT Replication Server is replicated faster and is available in the target solution when the data replicated from non-SAP system using scheduled SAP Data Services replication is running. If the combined data (from both source systems) is required for the target solution (target system), the business logic needs to implement a data consistency check. This means that the application’s implementation needs to check if the whole required business data that defines business transaction/object (complete data required to perform business functionality) is already available to avoid an inconsistent data view.
To simplify the solution, you can use Core Data Services (CDS), the SAP HANA-provided capability that you can use to implement the SAP HANA-level defined checks and views to the replicated business data. This means you can use CDS functionality to define business logic that allows you to expose the data stored in SAP HANA to the business application and the reporting tool. The data presented by the CDS views is in a consistent state and therefore can be used further for business operations.
However, the implementation of the data consistency in the application logic (code of business application) or CDS view can have a significant influence on the application’s performance. This is because the implemented logic is running all the time you access the data stored in the original tables. Therefore,
Figure 2 presents the example architecture that uses the staging area in the target system (see staging tables) to consolidate the data from various data sources replicated using different tools.
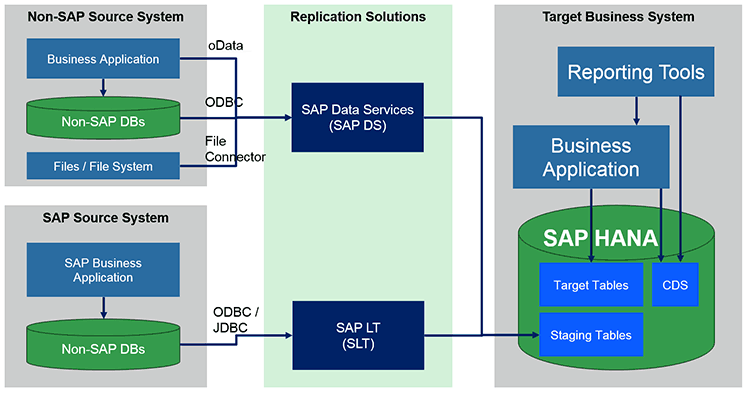
Figure 2
Example architecture using the staging area
The staging area consists of all already replicated data. You need to define the consolidation logic only once in the consolidation job that moves the complete consolidated data (from a transaction perspective of the final data format) from staging tables to final tables. After the data (e.g., data entry for one consolidated transaction) is checked and marked as complete, the consolidation process can move the data from staging tables to final tables. The data move avoids data duplication. This means the data is stored in the target system only once. If data is stored in staging tables, it is incomplete or erroneous, and if the data is stored in the final tables, it is transactional complete.
You should be aware that the whole solution is not a real-time solution and the data availability depends on the slowest data replication and transformation process that influences the particular transactional data view. The use of the staging tables could have an additional impact on the total replication time because of additional consolidation steps. However, this solution runs only once, and the final, ready-to-use business data can be directly consumed by the business application logic or provided via direct table access or via a CDS view to the reporting tools.
Looking now at new use cases and the modern enterprise solution, you may realize that business digitization requires data integration from a wide range of internal and external data sources ? for example, data provided by devices/things (the Internet of Things [IoT] use cases), social media, websites, and instant messaging systems.
Figure 3 presents an example of data replication and consolidation architecture that uses the SAP LT Replication Server tool to replicate the base data from the SAP business application (a process that is similar to the one I described in previous examples) and the SAP ESP tool to collect social media and streaming IoT data. Both data sources are then stored in the staging area that is used to consolidate the data.
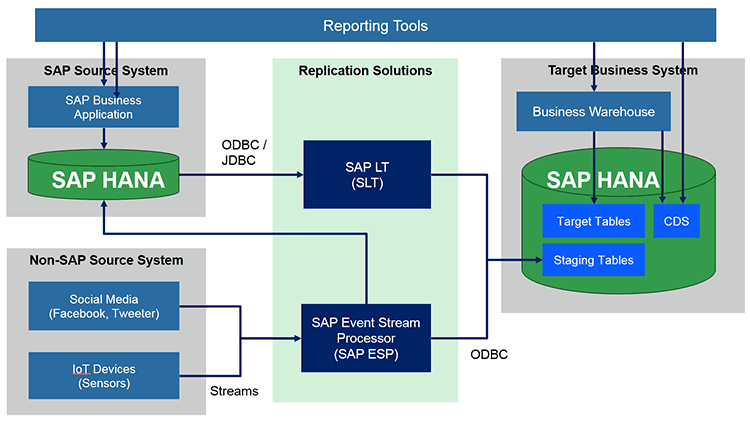
Figure 3
Replication architecture using SAP LT Replication Server and SAP ESP
In this case the staging area has additional value to the whole business solution because it can be easily used to transform and then consolidate data having completely different data formats. If the data is unstructured, for example, audio files, photos, and videos that don’t fit into traditional and modern databases such as SAP HANA, you can use a second storage/database in the staging area. For example, you can use SAP Vora with Hadoop (which is not presented in the Figure 3) to store this kind of unstructured data. You then can run the consolidation process across both storages/databases, extract the business-relevant data, and store it as final, ready-to-use data in the final tables.
This example can be combined into bigger and more complex solutions that use all the replication and transformation tools provided by SAP.
Scenarios Supported by SAP HANA Capability
SAP HANA is the SAP solution to store, maintain, and consolidate data from your enterprise solution. Therefore, the integration of the replication and transformation capability to SAP HANA can significantly simplify the enterprise architecture from a technology, business, integration, security, and licensing perspective.
Let’s start with a short presentation of the new capabilities provided by SAP HANA: SAP HANA smart data access, SAP HANA streaming analytics (formerly SAP HANA smart data streaming), and the consolidated SAP HANA smart data integration solutions.
SAP HANA Smart Data Access
SAP HANA smart data access is a remote data access functionality provided as of SAP HANA Support Package Stack 06. You can use it in SAP HANA SQL queries to access tables defined in SAP HANA as virtual tables and data that is stored in remote SAP or non-SAP databases (in so-called persistent tables).
You can use this functionality in SAP- and client-provided business applications to support new data integration and replication scenarios. For example, you can use this functionality in an integration scenario to access remote database data in SQL running in SAP HANA without permanently copying the data. This option is very useful if the access performance of the remote storage is not an issue (including network and data access in business process execution). If you realize performance problems, you can define replication logic in your business application running on SAP HANA. This smart functionality uses SAP HANA smart data access to access the remote data and copy it on demand to generate a local copy of the required data. In this case you build a business solution with an optimized logic regarding the required data access, its structure, and the size of the SAP HANA platform, which results in performance-optimized business functionality.
Additionally, you can use SAP HANA smart data access capability to access the data from various data sources, combine it using SAP HANA capabilities (e.g., use of Predictive Analysis Library [PAL] algorithms and business logic implemented in CDS) to build a data-optimized model that can be consumed by business application running on SAP HANA (e.g. SAP Business Suite on HANA and SAP S/4HANA) and directly by SAP and non-SAP business intelligence (BI) solutions (e.g., including SAP Lumira or Tableau).
SAP HANA smart data access can support the development and deployment of the next generation of analytical applications that require the ability to access and integrate data from multiple systems in real time regardless of data location. This means you have unlimited flexibility on the data sources and transformation capability, which can be used to fulfill the business requirement of the SAP, partner, and client-defined business functionality.
Figure 4 shows SAP HANA smart data access as a virtualization technique that is used in advanced business applications for solution-specific data replication and integration requirements.
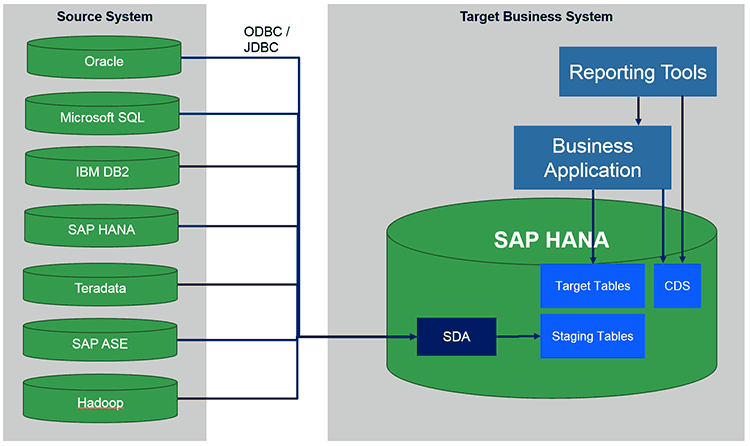
Figure 4
Overview of the architecture of the SAP HANA smart data access solutions
Here is a summary of the features of SAP HANA smart data access:
- You can locally use data that is defined and stored in other SAP and non-SAP sources or databases. SAP HANA smart data access uses a virtual table that points to remote tables in different data sources.
- The access to the remote data is in real time regardless of its location (you need to consider network latency).
- The access of data via SAP HANA smart data access typically does not affect the sizing of the SAP HANA database. This means that because the data is not stored in SAP HANA the sizing of permanent used data in SAP HANA is not changed. However, the dynamically loaded/accessed data could have an influence on the sizing of the temporary used data in SAP HANA. For standard solutions SAP suggests you define 50 percent of the total SAP HANA memory size as temporary memory–memory used to execute DB requests. Depending on the size of the dynamically loaded data using SAP HANA smart data access, you may consider adapting the standard configuration to the current solutions-based memory usage.
- Unlimited flexibility on the data sources and transformation capability. Users can define application/solution-specific data transformation logic using SAP HANA technology and functionality to replicate, integrate, and optimize access to business-relevant data.
SAP HANA Smart Data Integration
SAP HANA smart data integration was introduced in SAP HANA Support Package Stack 09. It is intended to simplify the data load and replication into the SAP HANA platform and the running on SAP HANA business applications/solutions. SAP HANA smart data integration provides an all-in-one package of data-loading tools containing the capability of SAP Data Services and SAP LT Replication Server.
It includes the SAP HANA smart data access solutions and therefore in new SAP HANA installations you often hear about SAP HANA smart data integration, even though SAP HANA smart data access is used. The inclusion of SAP HANA smart data integration reduces the complexity and provides a single user interface (UI) to support all the available functionality.
SAP HANA Streaming Analytics
The next new capability provided by SAP in SAP HANA Support Package Stack 09 is SAP HANA streaming analytics (SAP HANA smart data streaming). It is a high-speed event stream processor based on a scalable configuration of SAP HANA. It supports real-time processing of incoming information and is well integrated with the SAP HANA database and monitoring. You can integrate this functionality in your client-specific business logic. It gives you a perspective on the current state of information and dynamically provides support for potential problems and inconsistencies.
From a functional perspective SAP HANA streaming analytics covers SAP ESP and therefore can be used to support business scenarios integrating IoT streams, social media data sources, and other stream-based solutions. It is an optional component, which means that before you use it you need to check if it installed and configured. For more information go to this SAP help page:
https://help.sap.com/doc/a6e85810ac204660a019bff89b8181b0/2.0.01/en-US/index.html.
Figure 5 is an overview of the capability provided by SAP HANA Support Package Stack 09 that can be used in your environment to integrate data from different sources. SAP HANA supports the main capabilities provided by standalone tools. The in-memory processing and engines provided in SAP HANA accelerate the business solution execution that can (if properly designed) massively boost performance.
To simplify the solution setup, SAP provides ready-to-use connectivity agents. However, if something is not defined or provided in standard delivery, SAP HANA smart data integration enables you to build custom adapters with an open framework and a software development kit (SDK) to integrate any data sources.
Because this functionality is integrated into the SAP HANA system, you need to consider the use of the functionality in the sizing of the SAP HANA systems and the potential performance-related implications that can occur in the productive environment. This step is especially important in the production phases when you use the integrated solutions of SAP S/4HANA with embedded analytics. You can expect overlapping actions related with the extensive data loading and replication, daily operational activities in SAP S/4HANA (e.g., booking many documents), and execution of reports that could be resource consuming.
Use Cases for Data Replication and Transformation Using SAP HANA
The use of SAP HANA-provided data replication and integration functionality can significantly simplify the architecture and reduce the implementation time and costs of the use cases. Therefore, let’s look at an example of the architecture of the replication and integration solution using the SAP HANA smart data access, SAP HANA streaming analytics, and SAP HANA smart data integration (Figure 5).
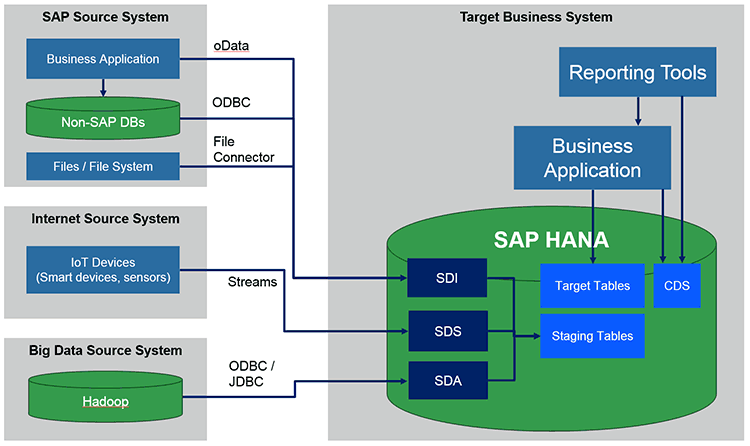
Figure 5
The replication and integration architecture using SAP HANA smart data access, SAP HANA streaming analytics, and SAP HANA smart data integration
The source systems in the example are the SAP business applications that run on a non-SAP database (e.g., ECC 6.0 running on Microsoft SQL server), the files containing unstructured business data (e.g., Microsoft Word documents that contain product descriptions and specifications), IoT devices (e.g., smart devices with sensors that provide data streams with the machine data and status), and Big Data solutions (e.g., Hadoop cluster). This setup could be a typical example of SAP business applications in which business data is extended by unstructured data in the file system and Hadoop. It uses the IoT infrastructure to add value to the reported real-time machine events, for example providing its state and information about its environment (such as temperature or pressure) that can be used together with business information to provide new business functionality (e.g., asset maintenance and automatic generation of a service request).
SAP HANA smart data integration is used to replicate the data from the SAP business solution to the staging area of the target business solution. The data could be accessed directly from the non-SAP database using the appropriate open database connectivity (ODBC) connector or from the application using the application API and OData. Finally, SAP HANA smart data integration can also use the file connector to access the unstructured data source such as files or Word documents and extend the data provided by the SAP system.
SAP HANA streaming analytics is used to connect and consume data provided by smart devices and its sensors that contains business-relevant information (e.g., machine status and environment-related information such as temperature or pressure). All the analyzed data is stored in the staging area, allowing you to create new business functionality. It connects the material data to support the status and material demand of the production line.
Very often the amount of data in modern applications requires the use and integration of big data solutions such as Hadoop. SAP HANA smart data access allows you access to the stored data and its direct consolidation in the SAP HANA-based business application.
Note
SAP offers SAP Vora as the integration tool between SAP HANA-based solutions and the Hadoop environment. It requires additional licenses. The use of SAP Vora can accelerate access to the Hadoop data, but is out of scope of this article.
After the data is stored in the staging tables, the consolidation process can check its consistency and then move it to the final table defined in the SAP HANA platform. The target tables are used directly by the business application and the reporting tools or via a CDS view.
The used replication technology and tools in SAP HANA should be considered in the sizing and resource planning of the solution. You can highly simplify the architecture using the embedded technologies (e.g., optimized engines for text mining and data compression) in the creation of a better integrated view to the business data, but you also need to check how the data model and the operational data are consumed by the end user.
I hope my examples of the data integration and replication capabilities provided by SAP HANA help you better evaluate potential integration topics. Table 1 presents a high-level overview of SAP tools and SAP HANA capabilities.
| Feature |
SAP LT Replication Server |
SAP Data Services |
SAP Replication Server |
SAP Event Stream Processor |
SAP HANA smart data access |
SAP HANA streaming analytics |
SAP HANA smart data integration |
| Real-time replication |
++
|
O (very restricted)
|
++
|
++ / + (depending on complexity)
|
++
|
+
|
++
|
| Batch/ scheduled data replication |
+
|
++
|
-
|
-
|
+
|
-
|
+
|
| Transformation |
+ (simple)
|
++
|
+ (simple)
|
+
|
O
|
+
|
+
|
| Streaming data |
-
|
-
|
-
|
++
|
-
|
++
|
+
|
| Replication from SAP systems |
++
|
++
|
O (license)
|
++
|
++
|
++
|
++
|
| Replication from non-SAP systems |
O (license)
|
O (license)
|
O (license)
|
++
|
++
|
++
|
++
|
Table 1 Summary of the features/use cases provided by SAP data replication tools, including SAP HANA-provided capability
In Table 1 I used the ++, +, O and – signs. These symbols have the following meanings:
++ Very strong support of this functionality
+ Support of this functionality
O Functionality supported with restrictions
- Functionality not supported
Depending on your use case and complexity you should consider which SAP replication and transformation tools and options are more valuable for your enterprise solutions. You also can consider the enterprise architecture and its guidelines to build enterprise-compliant landscape of integrated business solutions. You should, for example, check if the simple landscape can be supported by SAP HANA-supported replication and transformation capability, or if you need separate tools that are typically used in more complex integration enterprise landscapes. The use of separate and centralized replication functionality may have a significant benefit against the SAP HANA-based solutions if you plan to build and reuse replication functionality between different sources and target systems.

Robert Heidasch
Robert is the chief innovation and technology lead in the global Accenture Technology Platform, which is responsible for SAP Leonardo and the new digital technology defining business value and driving the digital transformation of complex enterprise solution for Accenture diamond and strategic clients. Before that he was responsible as innovation and solution lead for the design and architecture of new business applications developed jointly by Accenture and SAP based on the newest SAP and non-SAP technology. Robert is the Accenture certified Senior Digital Architect and Senior Technology Architect. He is coauthor and trainer of a couple of SAP technology-related trainings for the in-memory platform and architecture of new business applications (e.g., SAP HANA, SAP Cloud Platform, and SAP Leonardo applications for solution architects and technical architects, all of which were provided by Accenture in Europe, the US, and Asia). Robert has more than 23 years’ experience designing and developing IT systems. He published several technical and business articles about SOA, SAP NetWeaver and its integration with non-SAP systems (e.g. Microsoft, Oracle, etc.), and SAP HANA technology. He is also an inventor of 38 patents in the US in the area of in-memory technology, artificial intelligence and machine learning, security, semantics, and SOA. He is a frequent speaker in international business conferences and SAP Forum. He is a subject matter expert in customer projects worldwide and has extended experience in team leadership in Europe, the US, and India.
You may contact the author at
robert_heidasch@outlook.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.







