Knowing how BW handles metadata can make you a better BW developer. This article illustrates its importance by showing three ways of extracting source system metadata.
So far, no one has come up with a definition for metadata more elegant than “data about data.” It's a little more helpful to say that metadata can be broken down into two categories: descriptive (such as long text descriptions or categories) or functional (such as file permission codes or field-type codes used by a program generator).
Understanding how to use metadata and how it relates to BW will make you a better BW developer, whether you are on the technical or functional side. BW or any data warehouse exists to publish business data. Any supporting information from your BW system that you need to retrieve, prepare, or share is metadata. R/3 systems, and BW especially, actively manage a lot of metadata. When you print an InfoSource description, browse through your InfoObject definitions, or even review your Monitor to see last night's data loads, you are viewing metadata—the data about the data, the system-handling information that describes the business information loaded into your system.
If BW actively manages its own metadata, why do you need to worry about it? Why not just let the wizards of Walldorf do their work? Here are three reasons: access, control, and environment.
- Access. Often the information you need exists in the R/3 or BW system, but you don't know where to find it— for example, the R/3 source fields and rules of preparation for BW fields.
- Control. At some point during your projects, you will need to use BW data in a way for which SAP has not prepared. For instance, your auditors may require a report of your sensitive business information tied together with information that BW does not (or should not) contain.
- Environment. Some information outside of the BW and R/3 systems cannot be managed within SAP, but it is critical to your success. For example, the shop I work in maintains more than 20 instances of BW, APO, R/3, and other systems running under UNIX, all driven by a popular third-party scheduler system. The on-duty BW support role rotates, and the person on duty sleeps with a beeper under the pillow. The weeks I am on call, the most important piece of metadata in my entire system is an Excel spreadsheet that tells me the BW job schedules, related source system jobs, and relevant details. When the beeper blasts me out of bed, my manila folder of metadata helps me fix the problem and go back to sleep instead of going into work before dawn.
You can apply these techniques to other types of metadata as well. One of the most common types of metadata used within BW is a source system interface definition. This bridge between the BW and source systems maps the fields and record layout of a source system record being used by BW. Let's use this as an example of how you might use BW metadata at your own shop.
It's 4 p.m. and soccer practice is at 6:30 p.m. Your manager approaches your cube and says, “We've got to get some test data into the bookings InfoCube for an officer's briefing tomorrow at 9:30 a.m. The Basis team does not have the R/3 DataSource working, so we need some sample data. We've got an ABAPer standing by. Just give her the layout, field names, data types—the usual suspects— and she'll extract invoices from the legacy system.”
Sound farfetched? How about this? Same manager, same time: “By Friday I promised the integration team a Word document with all the InfoCube and InfoSource definitions. We need field names, attributes, and descriptions. Oh, and if you would give it to them in Microsoft Access, they would appreciate it.”
You need source-system metadata and the clock's ticking. What are you going to do? The three main methods for retrieving source system metadata are:
- Scroll through the transfer structure on the InfoSource screen
- Navigate the metadata repository
- Browse through the metadata with the data dictionary tools
For my examples, the third option—the data directory tools—represents your best chance to solve the problems and still get home for supper before soccer practice.
First, let me describe how the other two work so that you can better understand the differences among your options.
Go to the InfoSource
You can go to the InfoSource screen, open up the transfer structure, scroll 10 lines at a time through the descriptions, and copy the screenprints. Then you can retype the descriptions and send them in. This is the simplest approach to using BW's internally managed metadata.
For a quick look at metadata, this is often the best solution. Enter transaction code RSA12 and select your InfoSource—in my case, Paper Bookings Data. Right-click on it, and an Object overview, a list of all InfoObjects in this InfoSource, appears on the right (Figure 1).

Figure 1
Right-click on the InfoSource to view the Object overview
Tip!
The Object overview gives you a lot of useful information, but it is in alphabetical order, not field order. This is preferable for validating existence of fields, but it is not useful for a file layout.
If you double-click on the green InfoSource icon to the right of the InfoSource name, you see the InfoSource layout itself (Figure 2). This gives you the layout information you need, including field names and data types. You can then scroll down one screen at a time, take screenprints, and re-type the information later.

Figure 2
The InfoSource layout
You might not want to try this approach for the following reasons:
- You can't control the look and the layout.
- You must scroll to see your data in parts.
- You can't cut and paste into another application.
- You can only look at one structure at a time. What if the auditors want the layouts of your entire Phase I source inputs?
Use the Metadata Repository
Another approach is to view the metadata repository, a built-in BW feature. From the repository, you can index the entries if you have not already done so, then search for the transfer structure of the load record you are interested in. Next, either export it in HTML format and delete what you don't want, or navigate to the InfoCube list, take screenprints, then drill down into each InfoObject and take more screenprints. This is the most common way to retrieve BW metadata.
With the metadata repository, you can navigate through a nice view of your system objects that allows you to see their connections to other objects. You are limited to what you can see at one time, though. For example, you can see the transfer structure for the bookings InfoCube and its InfoObjects, but you cannot see the InfoObjects' properties without drilling down into each one (Figure 3).

Figure 3
Metadata repository screen showing InforObjects for the bookings
Browsing Using the Data Dictionary Tools
For the problems in my two examples, however, the third approach is your best option: Use the SAP data dictionary tools through the data dictionary browser, transaction code SE16, to open the table you want, download the data into Excel, then use it as is or integrate it with your documentation using Microsoft Word or Access. This is the most “self-directed” approach in that you have to find the tables, understand some of them, and know how to use extraction tools (the browser). It is also the most flexible approach, because you have more control over the data you extract and full control over how it is managed and presented outside of BW—just what you need to prepare the requested data in time for soccer practice. Let's look at this method more closely.
Execute transaction code SE16. In Table Name, enter RSTS to see the transfer structure. (Below.) Press the Enter key. In the TRANSTRU field, select from a list of transfer structures. Pick the Bookings InfoSource as seen on the InfoSource Screen and use asterisks as wild cards. In my example, this yields PBKD0001_RV.
Now, press the back-arrow key to return to the initial SE16 screen. This time, enter the transfer structure field table name RSTSFIELD.
You should see some common data browser parameters and selection fields (Figure 4). The selection fields are different for each table you view, and can be customized. If you wish to download only a subset of data by using a field as a filter, you have an option under the Settings menu option to add the field to your screen. You'll want to set a few parameters before you download your data. Click on Number of entries to see that this table has 50 rows. This table is small, but for a very large table, enter a larger value for Maximum no. of hits. Since this table has many columns to see, increase the field Width of output list to 500. Now, press the Enter key to see the layout of the transfer structure for the bookings InfoCube (Figure 5).
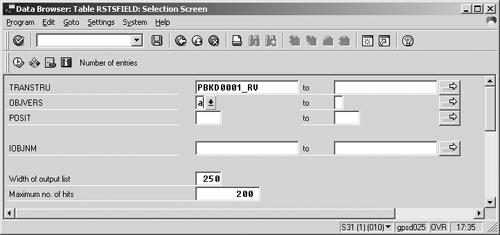
Figure 4
Selectrion screen for table RSTSFIELD
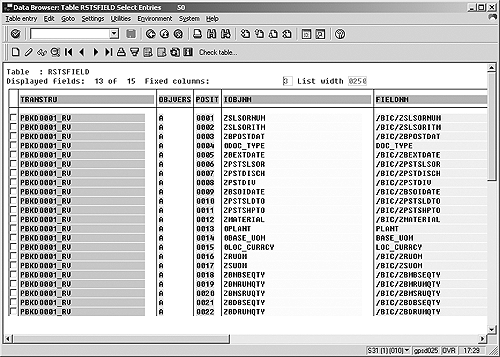
Figure 5
Transfer structure layout for the bookings InfoCuve
You have all the table rows and columns available. How do you get them where you want them in Excel format? From the menu at the top of the screen in Figure 5, select System> List>Save>Local file. This gives you format choices for your downloaded file: Unconverted, Spreadsheet, Rich text format, HTML format. Select Spreadsheet as the best choice for a quick Excel download. A download dialog box then allows you to place and name your file. Give it a name, navigate to a download directory, append the suffix .dat, click on Transfer, and you're done.
Tip!
SE16 has several helpful features. Check Settings for the key features behind this menu option.
File>OpenFigure 6Delimited4Next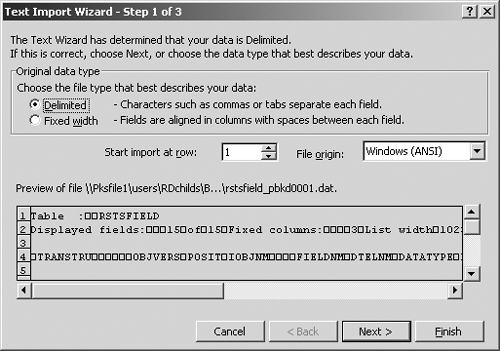
Figure 6
The Text Import Wizard
On the dialog box Text Import Wizard 2, leave the Tab delimiter option checked and click on Next. On the dialog box Text Import Wizard 3, click on Finish.
At this point, the spreadsheet appears with your headers in the first row. Delete the columns you don't want, including any blank columns that are a side effect of the SE16 browser. Finally, save the Excel file, being sure to change the type and suffix back to an .xls file.
You now have an Excel file with the field positions, names, data type, length, and number of decimals (Figure 7). From this point, you can easily import to any Microsoft Office or data dictionary application.

Figure 7
The complete Excel file
A parallel download technique exists that is useful for direct import into Access. Save the downloaded file as type Unconverted with a .txt suffix. Import the file into Access as fixed width, label each individual field, and save the import specification. This technique takes a little longer, but is better under these circumstances:
- If you have more than 65,000 rows, which Excel cannot handle
- When you import repeatedly and can use the import template over and over
- When you need to tightly control the field format—for example, importing numbers as text. Excel eliminates leading zeroes, but Access can control this.
To use the Access File Import Wizard, use the menu path File>Get External Data>Import. You will find good instructions if you search the Access help file for “Import Data.”
Using the data dictionary approach, you went inside BW to get just the information you need with the SE16 dictionary browser. You found the metadata tables you needed, checked their contents, and loaded just what you wanted into Excel or Access, making the data much more accessible. The many other uses for this technique include:
- Import all of your InfoObjects, InfoSources, cross-reference information, and so on into an Access database that you can use for your personal customized metadata repository.
- Conduct research. No matter how well BW works or how good the tools are, sometimes you've just got to see what's inside that table to believe it. Sometimes you need to answer a functional question. For example, I was recently asked to find out which of the 3,000 customer numbers in distribution channel 02 did not have a corresponding customer number among the 76,000 customers within division 03.
- Maintain sample data for your InfoCubes by using Excel, create field headers from the field names, and save them as a tab-delimited file. Now you have a spreadsheet where you can mock up data without having to extract it from R/3. You can use this data for early project prototyping, regression testing, or training with precise control over the contents and size of the files.
- Extract R/3 data. For example, our company uses custom inventory tables that we join with the VBRK invoice header and VBRP invoice line-item data in a view. When parallel testing for upgrades and new releases, we download and publish the R/3 data and send it to the various teams working with the data. I have worked at companies where the “metadata master” would begin his project by loading his own personal repository of system data for research and publication.
- Use it for project control data. For example, if you extract a list of InfoSources and InfoCubes and add one column to the end of the row for “status,” you have a great beginning for your status report.
Doug Childs
Doug Childs is a principal consultant at Enterprise Data Group. Originally a mainframe consultant, trainer, and data warehousing analyst, Doug has been working with BW since the initial 1.2B release.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.





