SAP HANA is a pivotal platform that can completely transform an enterprise, but without quality data SAP HANA only yields fast trash. Traditionally, tools such as SAP Data Services have been used to confront this problem. Now, SAP HANA holds capabilities to transform and cleanse data in real time from many sources. See how these technologies confront real-time challenges.
Key Concept
SAP HANA has many features to both manage data and improve data quality. These new options offer real-time transformational possibilities that were unthinkable until recently. They allow users to transform data in real time with Smart Data Integration (SDI) or conform and cleanse data with Smart Data Quality (SDQ). SDI is the next generation information management platform to transform data in SAP HANA. SDQ adds data quality capabilities to round out this next generation SAP HANA-based information management platform with capabilities in batch or real-time deployments.
Concepts such as business intelligence and analytics have been used on many different platforms over the years. However, with SAP HANA many more options exist for gathering measures and key performance indicators in real time from data as it is created in the SAP Business Suite or other systems. SAP HANA is an analytics platform for housing data from many disparate sources as the development stack for data warehousing. Since SAP HANA’s inception this has been accomplished with extracting, transforming, and loading (ETL) data into SAP HANA from multiple sources.
ETL is not a new concept, and in the SAP world, these types of operations and development have used technologies such as SAP Data Services to perform these functions. SAP Data Services is like many of its rivals in that it is mostly batch based. Traditional ETL in this paradigm has the challenges of introducing latency to the data in the data warehouse. Data must be gathered, extracted, and transformed in batches from multiple sources that are scheduled to process changed data to the targets. This schedule can happen once a day or in micro batches that may be once an hour or every 15 minutes, but at best, it will only be near real time.
There are many benefits that SAP Data Services introduces, even in an SAP HANA-powered solution. Properly transformed and modeled data can reliably perform in optimal engines such as SAP HANA’s online analytical processing (OLAP) engine, which is the most efficient there is in SAP HANA. This is not always the case with calculation view-driven replicated solutions from SAP ERP. These solutions provision data in SAP HANA in transactional tables. The benefit of the calculation-driven solutions is the fact that they are real time, but they may not process efficiently or scale well in SAP HANA as they operate in less efficient engines.
So, you have a real-time need, but not a way to get there in an efficient or fully transformed manner. Enter SAP HANA yet again with another transformative technology that reshapes these possibilities: SAP Enterprise Information Management (SAP HANA EIM). SAP HANA EIM comprises two technologies: Smart Data Integration (SDI) and Smart Data Quality (SDQ). I explore SDI in detail in this article.
SDI
SDI allows a developer to combine functionality to fully transform data that would normally be limited to SAP Data Services and perform those transformations in real time as records are created in a source system. A practical application of this technology could be to transform an account master data table into a structure that better lends itself toward reporting.
Figure 1 is an SDI flowgraph that performs operations to accomplish these transformations.

Figure 1
A flowgraph built to transform account master data
This example shows a source table called DIM_ACCOUNT. This could just as easily be an SAP account table or a table from another source system. The data does not really matter as the concept is the same, but for this example, I have account data structured in such a way that it is not easy to identify asset data. Using the flowgraph constructed in
Figure 1 makes asset data more identifiable and enables greater reporting capabilities when this account data is used in reporting as a dimension.
To accomplish this you create the flowgraph file, which is just another type of file in SAP HANA development, by navigating to the development perspective in SAP HANA studio and selecting a package. Then, you need to produce a pop-up menu on that package by right-clicking the package and selecting New. The example package shown in
Figure 2 is the package titled donloden.

Figure 2
Select Other… for the type of new development object to create a flowgraph
Right-click the donloden package and select New from the pop-up menu. Then click Other… After you select Other… a new window appears in which you can browse for the type of object you wish to create. To do this, the easiest thing to do is to start typing flow, and the system searches SAP HANA to produce the selection called Flowgraph Model (
Figure 3).

Figure 3
Create a new flowgraph
By clicking the Next button you create the basic flowgraph model that is the starting point of the one that is shown in
Figure 1. You then step through many of the tools in the tool palette to create the flowgraph to transform the data. The first step is to select the source of the account data that you will be transforming in this example. This is shown by picking the Data Source tool under the General section from the tool palette on the right side of the screen, as shown in
Figure 4.
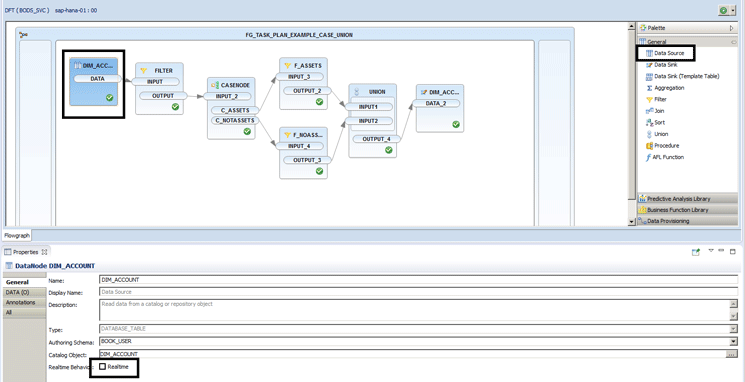
Figure 4
Select your data source for the flowgraph
You now have data from which to read. If you want to make the reads in real time as the data is occurring natively in the source table, then you should check the Realtime check box in
Figure 4. Now, as data is created in the source system, it flows into the flowgraph to be transformed on the way into SAP HANA. In
Figure 5 you can see the Filter node where you can filter the incoming data.

Figure 5
Filter the data in the flowgraph if neccesary from the data source
You do this by selecting the Filter node under the General section, but this is just shown as an example. In my use case filtering is not really necessary as this is a real-time example in which you want to take all the source data into SAP HANA. For an example in which you only wanted to limit real-time data streaming to accounts from North America, this is where you would do the limitation.
After this point SDI start to look a bit like SAP Data Services as the next step in the transformation is to use the Case Node functionality as shown in
Figure 6.

Figure 6
Case Node in the flowgraph model
Select the Case Node from the Data Provisioning section in the tool palette on the right side of the screen. After review, even the options for the Case Node look much like SAP Data Services. There are two output paths that compare a source field called ACCOUNTTYPE. The Case Node is looking for whether incoming data has been classified as an asset or not. The Case Node performs this by evaluating the contents of the ACCOUNTTYPE field to search for the text value of assets or not equal to assets. The output of the Case Node splits the record set into two paths based on this evaluation. If the classification of asset is found, then the data streams on the top path (F_ASSETS), and if not, then the data streams on the bottom path (F_NOASSETS). Then you can manipulate whatever transformation that is desired in the two record sets as shown in
Figure 7.

Figure 7
Transform the output datasets in the flowgraph model
These transformations could apply to any of the fields, and could really be any needed transformation that would make asset data more readily identified. For my purposes in this article the specific transformations are not as important as the concept of the possibilities. I now merge the data back together using the Union transform as shown in
Figure 8.
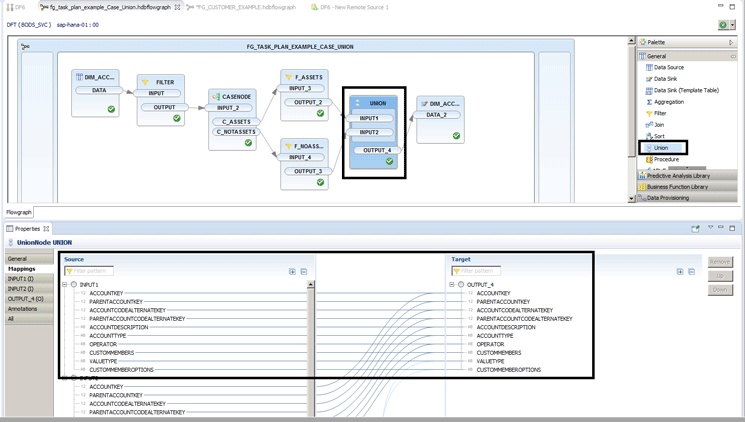
Figure 8
Union the transformed data back together
This functionality is just like a Union ALL in SQL, and it likewise demands that both record sets must be exactly the same to be merged (
Figure 9).

Figure 9
Data sink SAP HANA target table object
After the data is merged back together, select the data sink icon to load it into a target table. The table can be truncated during every run or invocation if desired by selecting the Truncate Table check box. I do not wish to do this as I want to preserve the real-time data in SAP HANA with all the transformations as they come across from the source. To accomplish this you only need to choose Upsert for the Writer Type: on the target.
This completes the development of the real-time enabled SDI flowgraph. As you can see it is a proper graphical development environment with many concepts that an ETL developer would find familiar. This is especially important as this new functionality is something that is becoming increasingly more important to mature SAP HANA users. It is important to remember that these capabilities exist to extend the development platform to perform tasks that set SAP HANA apart from other data warehousing tools. This is because this real-time transformation capability is unique to SAP HANA.

Don Loden
Don Loden is an information management and information governance professional with experience in multiple verticals. He is an SAP-certified application associate on SAP EIM products. He has more than 15 years of information technology experience in the following areas: ETL architecture, development, and tuning; logical and physical data modeling; and mentoring on data warehouse, data quality, information governance, and ETL concepts. Don speaks globally and mentors on information management, governance, and quality. He authored the book
SAP Information Steward: Monitoring Data in Real Time and is the co-author of two books:
Implementing SAP HANA, as well as
Creating SAP HANA Information Views. Don has also authored numerous articles for publications such as SAPinsider magazine, Tech Target, and Information Management magazine.
You may contact the author at
don.loden@protiviti.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.








