See how to apply the SAP HANA analytics and text analysis feature on raw data to solve critical problems. Learn how to use text analytics to gain insight into content-specific values, such as emotions, sentiments, and relevance.
Key Concept
SAP HANA provides a single platform to extract and analyze massive amounts of structured and unstructured data in real time from multiple sources, such as social media, blogs, online reviews, emails, and discussion forums. The analyzed information helps you to answer specific questions, increase revenue, and make accurate and timely decisions.
Today, both the source and volume of data collected have exploded. It is now easy to analyze the structured data (such as your sales numbers), but more difficult to listen to your customer. SAP HANA allows you to convert unstructured customer feedback in multiple languages from multiple sources into actionable insight. The insight helps to create and modify campaigns, understand current sentiments and trends, launch new products, and correct the pricing of products.
The insight even helps to create targeted contents to increase sales, change customer sentiments for critical problems, and gauge customer feelings. One example of text analysis is the use of sentiment analysis in elections to understand voters’ feelings.
Text analysis involves pattern recognition; tagging or annotation; information extraction; data mining techniques, including link and association analysis; and visualization. The goal is to turn text into data for analysis.
SAP HANA offers the flexibility to do text analysis and analytics on one platform. The massive data in SAP HANA is stored in a single database that saves time and cost and increases performance. In my example, I fetch twitter tweets and perform text analysis on them to understand customer sentiments. I also create visualizations of the data.
The steps to apply SAP HANA text analysis are as follows:
- Upload data to SAP HANA
- Perform text analysis configuration and create a custom dictionary in case the existing one does not suffice
- Create a full text index and model
- Create visualizations
Step 1. Upload Data to SAP HANA
In my example I have extracted Twitter data to an Excel file on my desktop using the Search API and uploaded the file into SAP HANA using Python Open Database Connectivity (PYODBC). It is the easiest way of connecting to SAP HANA via Open Database Connectivity (ODBC).
The SAP HANA Database Open Database Connectivity (HDBODBC) driver is a prerequisite for uploading data in SAP HANA using Python. Users can upload data by various data provisioning techniques such as SAP Landscape Transformation Replication Server (SLT) and SAP Data Services. Other techniques are already covered in the following articles:
The driver is installed with the SAP HANA client. You can check if the driver is present in your laptop ODBC data source administrator (Figure 1) by following menu path Start > Control Panel > System & Security > Administrative Tools > ODBC > System DSN.
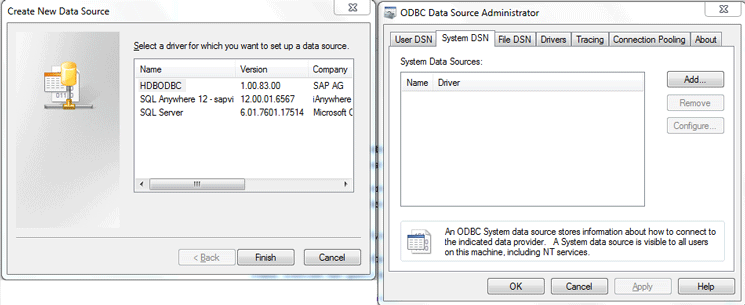
Figure 1
HDBODBC driver
Prior to the execution of the Python script, the column table “TEXT_ANALYSIS”, “PRODUCT” that holds the unstructured data should be present in SAP HANA. Execute the query (Figure 2) in the SQL console of the SAP HANA system to create the column table. The table is present in the schema TEXT_ANALYSIS table folder under Catalog in Systems (Figure 3).
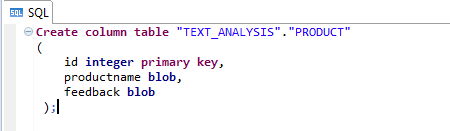
Figure 2
Create a table query
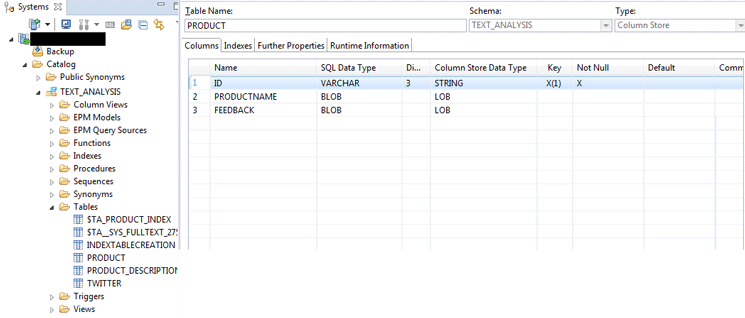
Figure 3
Product table
I have created the following Python script in Figure 4 that reads the local desktop file that has Twitter tweets. The script loads file data into the SAP HANA column table “TEXT_ANALYSIS”, “PRODUCT”.
Import pyodbc
“Create connection to Hana Database by providing system details
Conn = pyodbc.connect('Driver=(HDBODBC); SERVERNODE=lantgdcc44b2.pgtev.fdc.corp:30015;SERVERDB=N23;UID=SYSTEM1; PWD=Life123')
“Open the cursor
cur = conn.cursor()
“Enter the file path
file = open('C:data2.csv','r')
“Read the file content
content = file.read()
“Insert the file content in Hana table
cur.execute(“INSERT INTO TEXT_ANALYSIS.PRODUCT VALUES(7,7,?)", ('1’,content,content))
“Commit to save the content in Hana table
cur.execute("COMMIT")
“Close the file
file.close()
“Close the cursor
cur.close()
“Close the connection to Hana Database
conn. close()
Figure 4
Python script
Figure 5Figure 2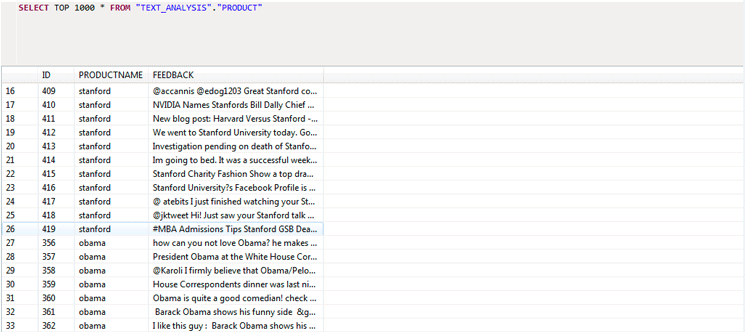
Figure 5
Uploaded data
The strategy I followed to get correct insight is to remove retweets from the Excel file and only upload the relevant tweets in SAP HANA. I did it to eliminate the sentiment bias of a single opinion.
Step 2. Text Analysis Configuration and Dictionary
The TEXT_ANALYSIS configuration file that is present in the package named sap (Figure 6) uses analyzer, dictionaries, and extraction rule sets to extract text analysis information.
Figure 6
Text analysis configuration
The file is stored in the SAP HANA repository in an XML format. It specifies the text analysis steps to be performed. The following analyzers are used in different types of text analysis configuration:
- The Format Conversion Analyzer specifies the option of format detection for uploaded unstructured data. The format changes according to the MIME type. For example, it checks if it is a tweet rather than a blog.
- The Structure Analyzer specifies automatic language detection. It automatically detects the language of the unstructured text and then extracts text analysis information in the TA_TYPE column. In my scenario the unstructured text is in English.
- The Linguistic Analyzer specifies the options of tokenization, stemming, and tagging:
a. Tokenization: The separation of input text into its elements. For example, the sentence “Iphone is a product of Apple” would be broken into six tokens.
b. Stemming: The identification of word stems or dictionary forms. For example, the words connection, connected, and connective are reduced to the stem connect.
c. Tagging: The labeling of the word’s part of speech. For example, paper is a noun.
- The Extraction Analyzer specifies the option for entity and relationship extraction. You specify the extraction rules and dictionary in the analyzer for sentiment analysis. This analyzer is only used in Extraction_* configurations.
a. Dictionary: You use this user-defined repository to create more user-defined entity types and names. You can also use it to store name variations. A developer can combine several dictionaries together in one configuration file. For example, if you want to replace the real-world entities such as United Kingdom, U.K., and UK by a single entity EuropeanCountry , then use the dictionary.
b. Extraction rule: You use this rule to identify a more complex entity type than the dictionary. You can create extraction rules to identify entities in an industry-specific language and establish an entity-to-entity relationship.
SAP has provided following text analysis configuration for extracting sentiment and text analysis information from unstructured data:
- Linganalysis_basic provides tokenization capability.
- Linganalysis_stems provides tokenization and stemming capability.
- Linganalysis_full provides tokenization, stemming, and tagging capability. For example, the sentence “I hate you” is stored in the full text index table (Figure 7). The TA_RULE is LXP for linganalysis_*.

Figure 7
Linganalysis_full
- Extraction_core extracts entities from unstructured text, such as people or organizations, including linganalysis_full capabilities.
- Extraction_core_voiceofcustomer provides sentiments and emotions, including extraction core capabilities. You can use this configuration to retrieve information on customer needs and perceptions. The TA_TOKEN is extracted according to configuration. The column TA_TYPE provides information on user sentiments (Figure 8). The TA_RULE for Extraction_* is Entity Extraction.

Figure 8
Extraction_core_voiceofcustomer
The text analysis configuration and dictionary are used for creating an index on which analytics can be performed. I have used Extraction_core_voiceofcustomer for my scenario as it provides sentiment analysis capabilities and also gives information on customer views.
Step 3. Create a Full Text Index and Model
You have to create a full text index on the column containing the unstructured data to use text analysis functions. The following data types are valid for text analysis: Text, Bintext, Nvarchar, Varchar, Nclob, Clob, and Blob. You can create an index two ways:
- Index during table creation
- Manual index on an existing table
You have to write the following parameters in SQL query while creating a full text index for text analysis:
TEXT ANALYSIS ON
CONFIGURATION '<NAME OF TEXT ANALYSIS CONFIGURATION>'
Index During Table Creation
The benefit of creating an index when you create a table is that it is created automatically with the table and you don’t have to execute a SQL query afterward to create a full text index. Execute the query in the SQL console shown in Figure 9 to create the index.

Figure 9
Index creation with a table
The option ASYNC automatically performs text analysis in the background and stores the results in an index table after an insert or update operation in the database table completes. If you do not specify a language in the index creation, then English is used by default.
Manual Index on an Existing Table
I have created a manual index for my scenario. Execute the query (Figure 10) in the SQL console of the SAP HANA system to create the index. The manual index approach is useful when tables already exist and the requirement is to use the table for text analysis.

Figure 10
Manual index
The index table is created with the name $TA_<index_name> in the same schema that contains the original table. When the index is created, all the pre-existing content in the table is processed and subsequent updates to the original table update the index table. The index is also dropped when you drop the original table on which the index is created.
The full text index is created after the execution of the query in Figures 9 or 10. The important columns in the table are:
- TA_TOKEN contains the elements of the input text.
- TA_RULE is required to distinguish between the linguistic analysis output and output from the entity extraction.
- TA_TYPE specifies the token on the basis of the configuration. For example, if the configuration is Extraction_* then it specifies SAP as the company. Otherwise, if configuration is Linganalysis_* then Noun is mentioned for SAP. This column also provides information on sentiments and emotions from unstructured data.
- TA_COUNTER counts all tokens across the document. For example, the sentence “I hate you” has a token for each word (Figure 11). The token generated varies with configuration.

Figure 11
TA_Counter
Figure 12 shows the full text index with the TA_TOKEN column that contains the elements of the input text.
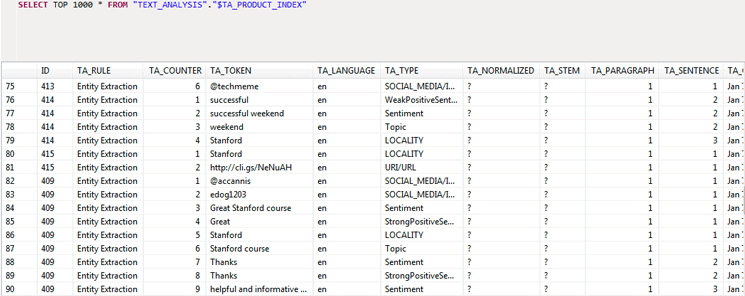
Figure 12
Text analysis index
Model
You can use the full text index table to do analysis and get insight. Post index creation I have created analytic and attribute views to analyze the Twitter feeds and create visualizations. One of the views is shown in Figure 13.

Figure 13
Analytic model
Step 4. Create Visualizations
The first step in creating a visualization is to analyze the type of the tweets users post on Twitter. I have created a tag cloud graph (Figure 14) based on the TA_TOKEN column in the full text index table to show that the tweets are mainly about user sentiments and views on different topics.

Figure 14
User sentiments
Later, I filtered the product description to Kindle and then analyzed the tweets on the column TA_TOKEN via the tag cloud graph (Figure 15).
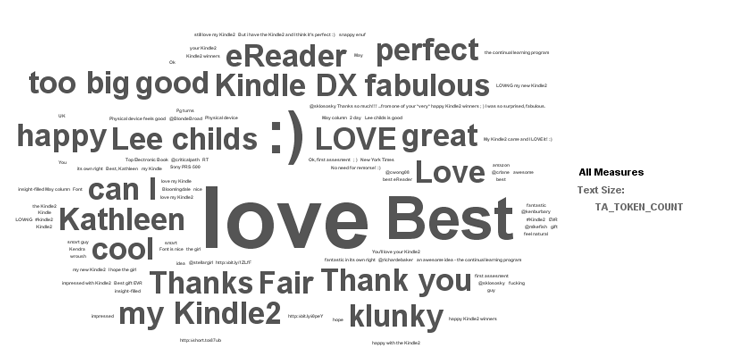
Figure 15
Analysis of tweets
You can do predictive analysis and geospatial analysis on the data to analyze the sentiments by region and to obtain insights.
Akash Kumar
Akash Kumar is an SAP technical consultant specializing in ABAP and HANA. He has 5+ years of experience in design and development of products with corporate organizations such as TCS, RBS, and SAP Labs. He is an active speaker and has organized multiple BarCamps in Delhi, India. He holds a bachelor of technology degree in computer science. He holds a certification in SAP HANA.
You may contact the author at akashkumar1987@gmail.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.






