Extracting the right data from your transaction system for analysis and decision making is important. You can standardize and correct data using SAP BusinessObjects Data Services. A real-time data migration example illustrates the concepts and walks you through the process. The scenario can help technical teams in any organization understand the data quality process for data migration. You can use this process in a non-SAP environment when data warehouses are built on top of relational database systems for reporting and analysis. You can also use it when the target is in an SAP system.
Key Concept
SAP BusinessObjects Data Services is an information management application for data integration, data quality, data profiling, and text analysis. It allows users to integrate, transform, improve, and deliver trusted data that supports critical business processes so that they can make sound decisions on time.
This article was originally published on BusinessObjects Expert
Data cleansing is an important aspect of SAP BusinessObjects because it allows companies to combine redundant records and streamline data for front-end users. SAP BusinessObjects Data Services is an extraction, transformation, and loading (ETL) tool that combines two facets of data migration (i.e., data quality and data integration) in a single user interface.
SAP provides SAP Best Practices for Data Migration, which is a set of preconfigured data migration jobs using BusinessObjects Data Services to migrate legacy data to another system. SAP Best Practices is available for two versions of BusinessObjects:
Note
This information is aimed at end users and developers who are interested in best practices regarding data cleansing.
This article is based on BusinessObjects Data Services 3.2. The process also holds good for BusinessObjects 4.0. Concepts are explained based on real-time data (i.e., transactional data used by any organization in its day-to-day activities), and how you get the data cleansed and ready to load.
Data migration using SAP Best Practices for Data Migration involves the following tasks:
- Ensure clean data in the staging database to be mapped to the source fields in the best practices job using data quality
- Configure best practices scenarios to the requirement and execute jobs to load the data to the target system
I focus on the data quality aspect of data migration in real-time scenarios. I use vendor master – basic data load as an example to explain the various steps involved in the data migration process using the best practices.
Note
Although the target used in this article is the vendor master tables in SAP, the target can be any table in non-SAP relational or data warehouse tables. All the transforms defined in the article work for both SAP- and non-SAP-based scenarios.
Source Data
Source data for migration is usually extracted from the legacy system in the form of delimited text documents or Microsoft Excel files in comma-separated values (CSV) format. Table 1 shows a sample vendor master data structure with data extracted from a legacy source system. I use this data as a reference throughout this article to explain various steps in the data quality process of data migration.

Table 1
Data extracted from a legacy system
Mapping Source and Target Data
SAP Best Practices has defined standard target data structures to maintain the source data.
Table 2 shows the data structure for vendor master basic data as defined in the best practices job, which in this case is data migration.

Table 2
An example of data structure
This is a standard structure as provided by SAP and designed considering the target SAP system’s database fields. For example, imagine that the vendor is YASH Technologies Pvt Ltd, and the Vendor Name Field in the SAP system is 17 characters long. You cannot store the full name in the first field, so you store the remaining part of the name (i.e., Pvt Ltd) in the vendor last name field, which is optional.
The fields preceded by an asterisk are mandatory. They are mapped to the target field in an SAP system and cannot be left blank. Business users add data to them. If the legacy data does not hold values for the mandatory fields, the best practice jobs fill in default values from the lookup tables defined in the repository. This is the case with the Vendor Account Number field in Table 3. If the source system has values for the mandatory fields, you need to ensure that they are mapped to the right target field. This mapping is the first step in the data quality process.
The next step is to map the legacy and target fields as shown in Table 3. This process includes defining business rules (e.g., providing default values based on the target system configuration).
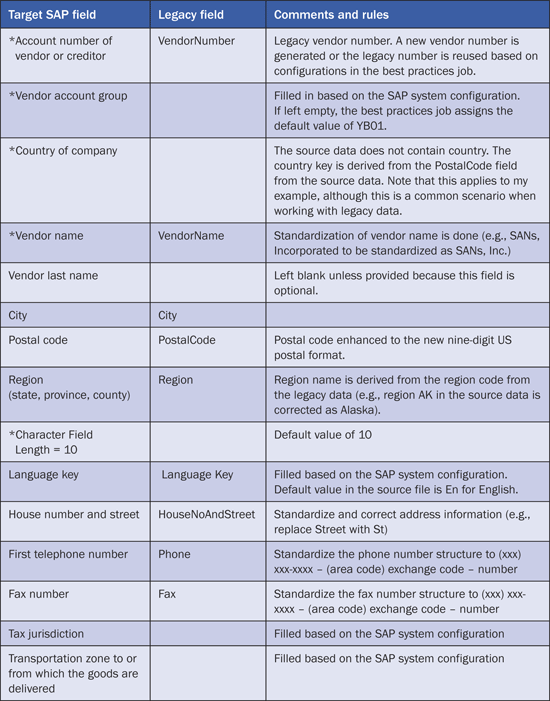
Table 3
Data source and target fields
A technical developer performs the following data quality activities to achieve the clean staging data:
- Address cleansing
- Data cleansing
- Match process
- De-duplication
Let’s look at each of these four activities in detail.
Address Cleansing
Address cleansing ensures that address fields (e.g., City, Region, Country, and Postal Code) are correct and standardized by using a Global Address Cleanse Transform. In Data Services, any data migration, loading activity, or enhancements are done using built-in processes called transforms. The transforms refer to the address directories that SAP provides to validate the values and correct them.
Note
Verify that you have the latest address directories in the server to ensure correct data. Address directories are updated regularly and can be downloaded from https://service.sap.com/support. For my scenario, the data is based only on US addresses. Therefore, I use the U.S. Global Address Cleanse transform.
Figure 1 shows the configuration of the U.S. Global Address Cleanse transform screen. The source fields on the left connect to the target fields on the right map. The tabs below the mapping area are used to configure the rules to achieve the cleansed address fields. You correct the source addresses to generate missing values, populate them, and format them before loading them to the target table.

Figure 1
Mapping U.S. address data in the U.S. Global Address Cleanse transform
You can see the source address in Figure 2 and the target address in Figure 3 after the addresses are corrected.

Figure 2
Addresses prior to the cleanse transform

Figure 3
Cleansed addresses
After you execute the Address Cleanse transform, you cleanse the region, postal code, and address fields and populate the country key (Figure 3). Place all the previously mentioned transforms in the right order of execution under a data services project. When you execute the project, Data Services runs the job. There is no transaction code involved as this is a BusinessObjects tool with a Windows-based GUI.
The following results are achieved by the address cleanse process in Figure 3:
- The REGION field is populated with values based on the codes from the source file (e.g., region code HI is replaced with Hawaii in the second row).
- The POSTCODE field is enhanced to the nine-digit US format (e.g., postal code 96819 is enhanced to 96819-1982 in the second row based on the locality and region).
- The COUNTRY field is populated with the country code based on the postal code.
- In the eighth row, the City field is corrected (e.g., Phenix has been corrected to Phoenix).
- The address 3131 N Nimitz Hwy #-105 has been corrected to 3131 N Nimitz Hwy Ste 105 in the third row.
- In the 10th row, the region name is populated to Oregon based on the postal code (notice that in the source data, the Region field is <Null> for the same).
This example demonstrates how BusinessObjects Data Services can cleanse the data even though the source data on the original Excel sheet was incomplete.
Data Cleansing
Data cleansing ensures that data is parsed, corrected, and enhanced to fit business needs. Data cleansing standardizes data, and during de-duplication of data, it helps eliminate duplicate records. Among the cleansing activities are the following:
- Condensation, which is the removal of spaces in the beginning and end of data from an address-cleansed file. This activity helps ensure that the data fits to a target field.
- De-punctuation, which removes punctuation from source files for more space, similar to condensation.
- Capitalization, which changes the case to uppercase in the source file. Rules are part of the transform and can be customized according to the users’ requirements.
- Standardization, which makes telephone and fax numbers uniform and puts them in a consistent structure.
Let’s discuss these activities further.
Condensation
You achieve condensation using a query transform. As shown in Figure 4, use ltrim() and rtrim() functions to truncate the spaces in the beginning and end of data.
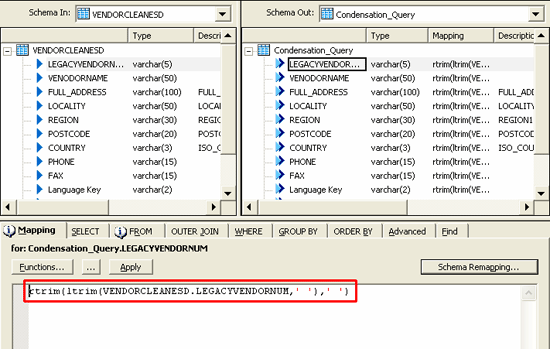
Figure 4
Condensation of data using ltrim() and rtrim()
De-punctuation and Capitalization
You perform de-punctuation and capitalization using the Data Cleanse Transform, which helps correct the data and identify duplicate records before load. For example, a Data Cleanse transform is usually done before using a Match transform because it helps identify duplicate records. Duplicate records are removed in a Match transform. Therefore, when the Data Cleanse transform is used, you do the cleansing on the right subset of data rather than on the full data set, reducing the execution time when the data is extensive. The required data cleansing rules are configured in the Options tab (Figure 5).

Figure 5
Configuring de-punctuation and capitalization rules
The results of the Data Cleanse activity include the following (Figure 6):
- Vendor names are fully capitalized
- Phone and fax numbers are standardized to the US format

Figure 6
Results of de-punctuation and capitalization activities
Match Process
Once the data is standardized, the next step is to identify the duplicate records and eliminate them. This step is done using the Firm Address Match transform (Figure 7). In my example, the matching is done based on the vendor name and the address.
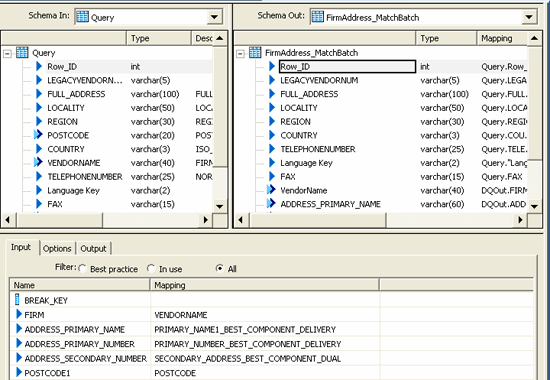
Figure 7
The Firm Address Match transform
Figure 8 shows there is one duplicate record. You can identify it using the Match transform.
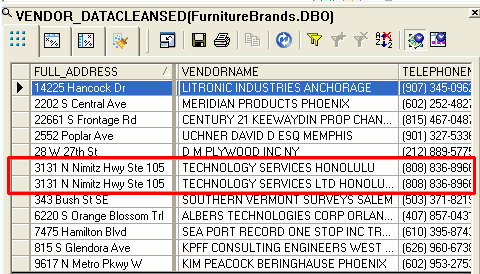
Figure 8
Data after address cleansing
After you execute the Match transform, you see the results in Figure 9. The system adds a new column called Firm_Address_Status in the result set. The values in this column are used to identify the duplicate record based on these values:
- Firm Match Status = U and P indicate unique records
- Firm Match Status = D indicates duplicate records
Figure 9 shows that the duplicate record is populated with a status of D.
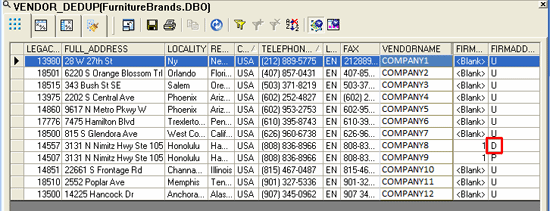
Figure 9
Result data after Match Transform
De-duplication
De-duplication is the final step in the data quality process. Once you identify the duplicate records using the Match transform, the next step is to analyze and remove the duplicates. This step is done using a Query transform and filtering the records based on the Firm_Address_Status column values as shown in Figure 10. Based on the values in Firm Match Status generated by Match transform, you can separate duplicate records from unique records.
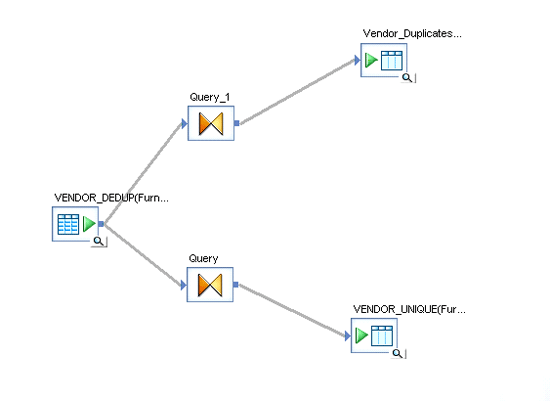
Figure 10
The de-duplication data flow
A developer adds filters in the WHERE tab of the Query transform as shown in Figure 11.
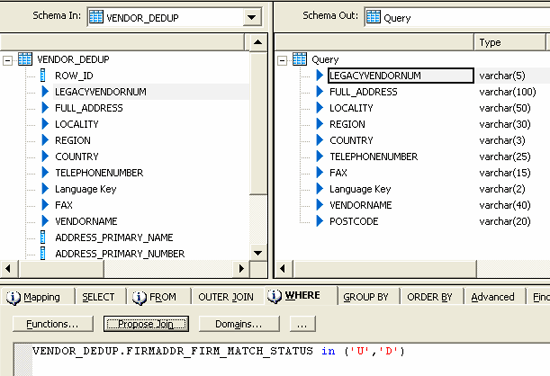
Figure 11
The Query transform
The system checks the values in the target tables (vendor_dedup table, which is used as a source here) for duplicates. As shown in Figure 12, the duplicate row is loaded into the vendor_duplicates table (right side), and the unique records are loaded into the vendor_unique table (left side).
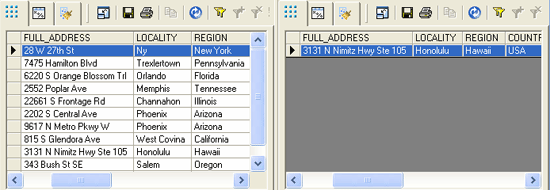
Figure 12
A duplicate row added on the right
Figure 13 shows the final set of data after the data quality job is executed.
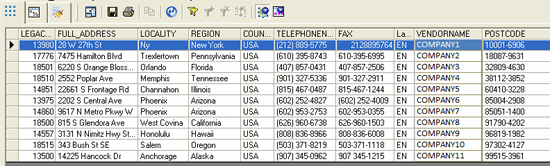
Figure 13
The cleansed data
The table shown in Figure 13 is used as the staging table. Clean data is now ready and can be loaded to the vendor tables in the target system. You use the BusinessObjects Data Services Best Practices Jobs after mapping the fields of the staging table as the source. Detailed documentation on the configuration and execution process can be found here: https://help.sap.com/bp_dmgv332/DMS_US/HTML/index.htm.
Jeswin Davidson Ebenezer
Jeswin Davidson Ebenezer is an SAP BusinessObjects consultant with YASH Technlogies. He has about nine years of experience working on BusinessObjects implementations on ETL and reporting.
You may contact the author at Jeswin.ebenezer@yash.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.




