Learn how to use the World Wide Web Consortium (W3C) standard XQuery language to create message mapping programs in SAP NetWeaver Process Integration (PI.) Identify scenarios in which XQuery can simplify complex mapping requirements.
Key Concept
Within the W3C, XQuery is positioned as an XML query language. This is to say that XQuery allows XML developers to query the contents of related XML documents in much the same way that SQL allows for querying data from relational databases. This analogy has become so pervasive that in some circles XQuery is known as the SQL for XML.
One of the great things about the SAP NetWeaver Process Integration (PI) platform is that it provides developers with a number of options for implementing XML transformation programs. For example, with Java-based mappings, the PI mapping engine places few restrictions on conforming mapping programs, allowing developers to implement the XML transformation logic however they like. The PI mapping engine doesn’t care how you generate the resultant XML so long as the XML is well-formed, and you don’t consume too many resources along the way.
Traditionally, Java-based mapping programs have been implemented using various application performance interfaces (APIs) provided with the Java API for XML Processing (JAXP). Indeed, if you look at the pre-delivered enterprise services repository (ESR) content provided by SAP, you’ll find that much of it is implemented using the standard document object model (DOM) API included with JAXP. This approach is straightforward enough, though it can be a bit tedious. This is particularly the case with complex source documents where the data has been flattened out in such a way that data is not organized in a hierarchical fashion. For these kinds of tasks, developers are often forced to unmarshal the data into intermediate data structures that lend themselves toward simplified querying, cross-referencing, and indexing.
In this article, I show you a much more elegant alternative for implementing complex transformation scenarios, like the one outlined above, by looking at how to integrate queries based on the W3C’s standard XQuery language into PI mapping programs. Though XQuery is not a panacea, it certainly has an important place in an XML developer’s toolkit.
What is XQuery?
Before I demonstrate how XQuery can be integrated into PI mapping programs, I want to take a few moments to look at what XQuery is and what you can do with it. Using XQuery you can:
- Search for information from XML documents based on various selection criteria.
- Join data from multiple XML documents into a single result set.
- Filter out unwanted data using highly selective criteria and logic.
- Sort, group, and aggregate XML data from multiple sources and documents.
- Transform and restructure XML data into different vocabularies.
Note
If you’re familiar with XSLT, then you might see some overlap between what XQuery brings to the table and what you already have with XSLT. This is not by accident, since both languages are declarative in nature, have their roots in XPath, and are presided over by the W3C. However, if you look more closely at the two languages, you can see that the similarities stop there. You can find an excellent compare-and-contrast piece highlighting the differences in these two languages online at
https://www.ibm.com/developerworks/xml/library/x-wxxm34/index.html.
Syntax-wise, XQuery has a very different flavor from XSLT and other XML-based transformation languages. Right off the bat, you can see that XQuery queries are written using a non XML-based syntax that combines XML template content with query logic and constructs that you are more accustomed to seeing in functional languages.
To see how this works, consider the XML document excerpt (Figure 1) which is a simple catalog of business partner elements. Nothing too fancy here, but you get the basic idea.

Figure 1
Catalog of business partner elements
Now, imagine the code from Figure 1 being tasked with compiling a list of business partners of the type Person. With XQuery, you can build a query (i.e. an .xquery file) using a syntax such as the one shown in Figure 2. This query selects the set of all business partners whose type is Person. The result list is then sorted in ascending order based on the name value contained in the <Name1> element.

Figure 2
Syntax for an XQuery Query Expression
As you can see in Figures 1 and 2 most of the heavy lifting is performed by the FLWOR (pronounced flower) expression contained within the curly brackets. Here, the FLWOR acronym refers to the for, let, where, order, and return keywords contained within the expression. With this baseline for building query expressions, you can branch out and implement more complex query logic by mixing in conditional logic (i.e. if...else statements), callable functions, and so forth. For example, if you need to refine the person query above to only pull business partners that have an external group assignment, you could enlist the aid of the standard starts-with() string processing function as shown in Figure 3. As more complex requirements emerge, you might need to implement nested queries (i.e. FLWOR expressions inside of a return clause) to weave various content pieces together. Sprinkle in some callable functions, and you have a fully-functional mapping program on your hands.

Figure 3
An Advanced Query
As you look at the list of features in the bulleted list above, you may have noticed that XQuery is designed to work with one or more source XML documents that are likely passed into the XQuery processor by reference. This is demonstrated in the XQuery processing model depicted in Figure 4. Here, you can see how multiple XML documents can be passed into an XQuery processor for processing. An XQuery file is also passed into the processing engine. As you might expect, the heavy lifting is carried out by the XQuery file. At runtime, the XQuery processor executes the queries contained in the source XQuery file to produce a resultant XML document. The resultant XML document can be as simple or complex as you want.
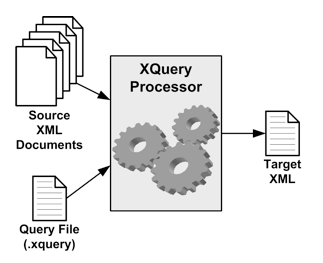
Figure 4
XQuery processing model
Digging too much deeper into XQuery foundation issues exceeds the scope of this article. For now, turn your attention towards the utility of XQuery as it relates to the development of PI mapping programs. If you’re interested in learning more about XQuery, I recommend that you pick up a copy of Priscilla Walmsley’s XQuery (O’Reilly Media, 2007).
What is XQuery Used For?
Now that you have a general sense for what XQuery is all about, you might be wondering how all this relates to the development of PI mapping programs. In other words, what does XQuery bring to the table that you don’t already have out of the box with the PI mapping toolkit?
To put the advantages of XQuery into perspective, take a look at the structure of a fairly common XML source document that you may encounter in the SAP space: BAPI-based IDoc messages. As you can see in Figure 5, these documents do not have the traditional hierarchical flow that most XML vocabularies have. Instead, the data is effectively flattened out into a series of sibling segments and elements whose positioning is not immediately obvious.

Figure 5
Traversing through a flattened IDoc message
To put the pieces back together on a PO document such as the one shown in Figure 5, you must execute queries that follow foreign key relationships from one segment type to another. When you think about it, this is precisely the type of problem that XQuery was designed to solve. So, while you might be able to achieve the same results using some of the standard mapping options, an XQuery-based solution will almost undoubtedly be more simplistic and easier to maintain.
Another potential usage scenario for XQuery would be the parsing of attachments based on the new Microsoft Office Open XML formats (e.g., .xslx files from Microsoft Excel). If you’ve ever unpacked one of these documents using a ZIP archive utility such as WinRAR, you can see that there are multiple XML files contained in different directories. Depending on the complexity of the files, XQuery could represent a highly effective solution for combining and transforming the content into a single XML schema.
In both of the example scenarios outlined above, you can begin to see a basic pattern: XQuery is generally well-suited for dealing with complex XML that doesn’t lend itself well to direct point-to-point type mappings. You can see that XQuery is a much more productive language than any of the usual suspects used to develop PI mapping programs. The major trade-off here is in performance. Because of its complexity, the XQuery processor engine generally consumes more resources than graphical mapping programs and other similar programs. If the messages are small enough, this is usually not too much of a concern, but it can become a major issue for large or high volume messages. As a result, I recommend that you only use XQuery in low volume scenarios when the complexity of the mapping calls for something more powerful.
Integrating XQuery with PI Mapping Programs
Development-wise, it’s actually pretty easy to assimilate XQuery-based queries into PI mapping programs. The basic process is as follows:
- First, you need to download an XQuery processor that can be included on the PI mapping engine’s class path. There are several alternatives here, but my default choice is the open source Saxon processor which you can download at https://saxon.sourceforge.net/#F9.4HE. Within the download archive, you can find the necessary JAR files to be loaded as imported archives in your PI ESR. I highly recommend loading the Saxon JAR files into a base-level SWCV so that other PI mapping components can inherit these libraries automatically.
- Next, proceed with the development of your XQuery query file as per usual. This process is greatly aided by having an XML processing tool such as Progressive Software’s Stylus Studio, but this is not a strict requirement. Indeed, in the source code download for the demo that follows, I’ve provided a complete project in Eclipse that allows you to test your transformations using Apache Ant.
- Finally, create a PI mapping class in Java and use the XQuery API for Java (XQJ) to delegate the mapping request to your custom XQuery file and marshal the results onto the target java.io.OutputStream instance provided by the PI mapping API.
To see how all this comes together, it’s helpful to take a look at some actual source code. In Figure 6, I have provided a shell mapping program which provides a template for integrating XQuery programs within a PI mapping program. You can find the complete source code listing/demo at https://www.bowdark.com/downloads/XQueryTest.zip.
At a high level, the code in Figure 6 works like this:
- First of all, I’ve included a static initializer block to pre-load and pre-compile the XQuery query so that everything’s ready to go once the mapping program is invoked at runtime. This is an important performance-tuning measure that significantly reduces the overhead of query processing at runtime.
- Within the initQuery() method, I’m using the XQJ API to pre-load the query. Here, you can see that the XQJ has a similar look-and-feel to the Java database connectivity (JDBC) API.
- At runtime, any mapping requests will be funneled through the transform() method as per usual. In order to maximize reuse, the heavy lifting is handed off to the runXQueryMapping() method which executes the XQuery file. Here, the source XML file from the PI mapping engine is fed in using the bindDocument() method of the javax.xml.XQuery.XQPreparedExpression interface.
- From here, you execute the query and then serialize the results onto the target java.io.OutputStream instance.

Figure 6
Create an XQuery-based PI mapping program in Java

James Wood
James Wood is the founder and principal consultant of Bowdark Consulting, Inc., an SAP NetWeaver consulting and training organization. With more than 10 years of experience as a software engineer, James specializes in custom development in the areas of ABAP Objects, Java/J2EE, SAP NetWeaver Process Integration, and SAP NetWeaver Portal. Before starting Bowdark Consulting, Inc. in 2006, James was an SAP NetWeaver consultant for SAP America, Inc., and IBM Corporation, where he was involved in multiple SAP implementations. He holds a master’s degree in software engineering from Texas Tech University. He is also the author of Object-Oriented Programming with ABAP Objects (SAP PRESS, 2009), ABAP Cookbook (SAP PRESS, 2010), and SAP NetWeaver Process Integration: A Developer’s Guide (Bowdark Press, 2011). James is also a contributor to Advancing Your ABAP Skills, an anthology that holds a collection of articles recently published in SAP Professional Journal and BI Expert.
You may contact the author at jwood@bowdark.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.





