Explore the connectivity to data stored in the Hadoop distributions (Cloudera and Hortonworks) through the discovery component of SAP Lumira 2.0.
Key Concept
A Big Data wave has prompted analytics tools to provide native connectivity to the better known Big Data distributions such as Hortonworks and Cloudera. Both Hortonworks and Cloudera provide Hadoop distributions to enable enterprises to be Big Data driven. Connectivity to other distributions of Hadoop can be achieved by implementing the appropriate Java Database Connectivity (JDBC) or Open Database Connectivity (ODBC) drivers. Modern analytic capabilities also enable self-service BI, which allows business users to work with data directly with minimal interaction with IT. SAP’s self-service BI tool, SAP Lumira, allows connectivity to traditional data sources as well as integration into Big Data sources to enable data exploration.
Thanks to Big Data technologies, unstructured data can now be stored, processed, and queried in a cohesive manner. While storing and processing data have been a primary focus for technology companies, querying and analysis of Big Data are now gaining momentum. Native connectivity to Big Data technologies is now a prerequisite for modern data analysis tools with features that offer advanced charting options.
The SAP Analytics suite offers native connectivity to two of the most popular distributions of Big Data (i.e., Hortonworks and Cloudera). SAP Lumira 2.0, part of the suite that enables self-service data exploration, also offers users direct connectivity to Hadoop Hive and Cloudera Impala. Business users can connect to the data, analyze it, and build stories on it. I provide a step-by-step guide on connecting to two of the popular Hadoop distributions, Cloudera and Hortonworks, by fetching a sample dataset to create transformations, build visualizations, and build a story on the data. For the purpose of demonstration, I use virtual machines provided by Cloudera and Hadoop.
The tools I use are:
- Cloudera QuickStart for CDH 5.10 Sandbox
- Hortonworks Data Platform (HDP®) 2.6.1 on Hortonworks Sandbox
- Virtual Box 5.1
- SAP Lumira 2.0, discovery component
If you are not familiar with the terminology involved in Big Data, go to the “Terminology” sidebar.
Terminology
Here are some significant terms and terminologies:
Big Data: The ability to capture and process data has been evolving with the emergence of better hardware and connectivity options. Big Data technology enables processing and analysis of enormous sets of data to reveal trends, patterns, and insights. Of the multiple technologies available, the distributions from Cloudera and Hortonworks are the most prevalent.
Cloudera is the oldest distributor of Apache Hadoop distributor with multiple proprietary tools for managing the underlying Hadoop Distributed File System (HDFS) and data. The prominent tools are Hue and Impala. Advantages include robust distribution of Hadoop, commercial software with proprietary tools, and an enterprise-grade support system.
Hue is a web-based application used for carrying out database-level operations on Hadoop data.
Impala is a data warehouse-based project used to store aggregated data from the Hadoop file system. Impala is used as an aggregator layer over the file-based Big Data storage.
Hive is a data warehouse project that works on top of the HDFS data and enables table-based operations using SQL.
Hortonworks: The Hortonworks distribution, though fairly new, has found wide acceptance across enterprises primarily due to its robustness and support for the windows platform. Advantages include a smoother learning curve, an open source license, and the Apache-only software, which makes it easier to integrate.
Ambari is the Hadoop management console for the Hortonworks distribution
SAP Lumira 2.0: SAP Lumira is a self-service data exploration tool from SAP that enables you to connect to multiple data sources and present data as visualizations and storyboards. Version 2.0 is a massive shift from the earlier versions and provides better connectivity, as well as data manipulation and visualization capabilities.
SAP Lumira 2.0, discovery component: The data discovery component of SAP Lumira 2.0 enables connectivity, data merging, and manipulation across multiple data sources.
Connecting SAP Lumira 2.0 Discovery to Cloudera
To enable SAP Lumira 2.0, discovery component to connect to the Cloudera distribution of Hadoop, follow these steps:
1. Click the Windows Start button, go to SAP Business Intelligence, and start the SAP Lumira 2.0, discovery component desktop client as shown in
Figure 1.

Figure 1
Start the discovery desktop
2. The default screen (
Figure 2) shows the connectivity options and the recent documents. This page is in line with the new tile-based display approach for all SAP tools.
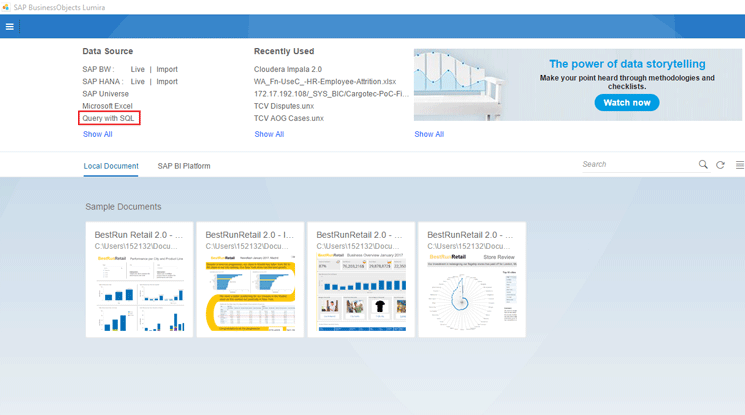
Figure 2
The Lumira 2.0, discovery component start screen
The top section shows all the data sources to which SAP Lumira can connect. Select the Query with SQL, option which takes you to
Figure 3. This section shows all the drivers available for connecting to the native data sources as shown in
Figure 3.
3. Select the appropriate Simba driver under Cloudera. In this case, the Cloudera Impala 1.0 – Simba JDBC Drivers option is selected in accordance with the Cloudera version. Click the Next button in
Figure 3 to display the log-in screen (
Figure 4).
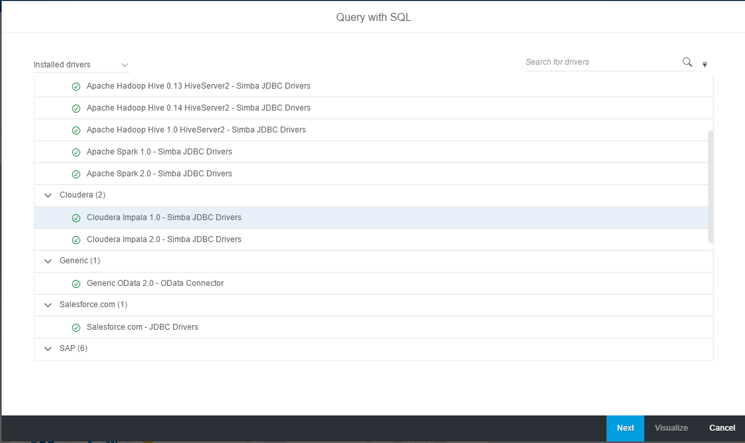
Figure 3
Select the Simba driver for Cloudera
4. In
Figure 4 enter data in the User name, Password, and Server (port) fields. The port for connecting to Cloudera is 21050. Click the Connect button to advance to the Cloudera Catalog view (
Figure 5).
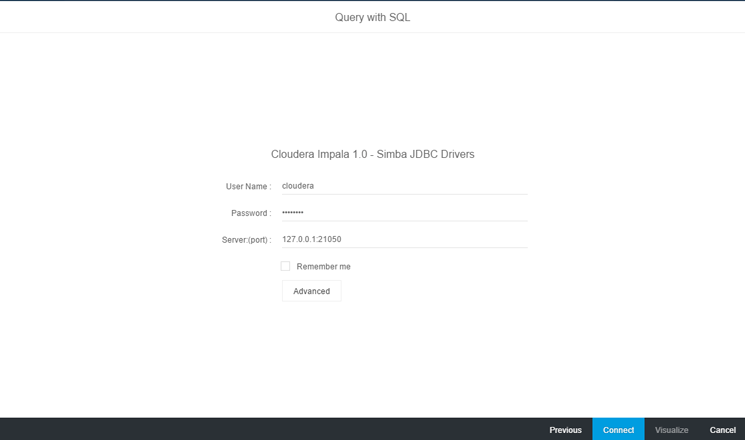
Figure 4
Connect to the Cloudera server
5.
Figure 5 shows the database instance (in this case default) under the CATALOG_VIEW under Cloudera.

Figure 5
The Impala database under the Cloudera CATALOG_VIEW
6. Select the appropriate table (t_population in this case). The query panel on the right generates the default query on the table, which selects all columns from the table (
Figure 6).

Figure 6
Select the t_population table
7. SAP Lumira allows you to rename the dataset and also to form a custom query in case all the columns are not needed for exploring the data. This option is especially useful when the dataset is large and can be cut down to specific columns for exploration in SAP Lumira.
In my example, I have included all the columns, which is also the default query formed by SAP Lumira. Since all the columns have been selected in the query panel in
Figure 7, I use * instead of specific column names from the table.

Figure 7
Select data from t_population and preview
Click the Preview button to view a sample of how the data looks as shown in
Figure 7. Previewing a dataset is a good practice since it allows you to weed out any discrepancies or errors before finalizing and visualizing the dataset.
8. Once you verify the data through the preview, click the Visualize button in
Figure 7. SAP Lumira then acquires the data shown in
Figure 8.

Figure 8
Data acquisition by SAP Lumira from the Impala table
9. SAP Lumira then acquires the dataset from Cloudera Impala based on the query specified and auto-creates dimensions and measures in the DesignView as shown in
Figure 9.
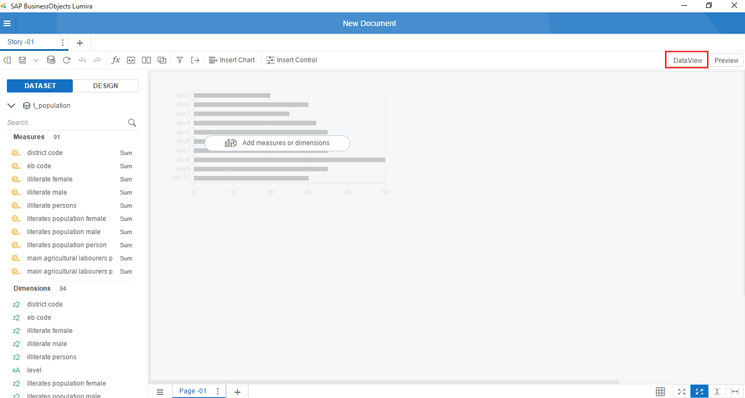
Figure 9
SAP Lumira 2.0, discovery component DesignView
10. Dimensions and measures can be created, modified, or deleted from the left panel as shown in
Figure 9. Data can be manipulated further by clicking the DataView tab shown in
Figure 9. The DataView details are shown in
Figure 10.

Figure 10
SAP Lumira 2.0, discovery component DataView
11. Drag a dimension from the Dimensions section and drop it onto the chart on the right. It can then be combined with a measure, again by dragging and dropping as shown in
Figure 11.

Figure 11
Drag and drop measures and dimensions onto the chart
12. In my example the district code dimension is selected along with the total population person measure. The data from Cloudera is now shown as a bar graph (
Figure 12).
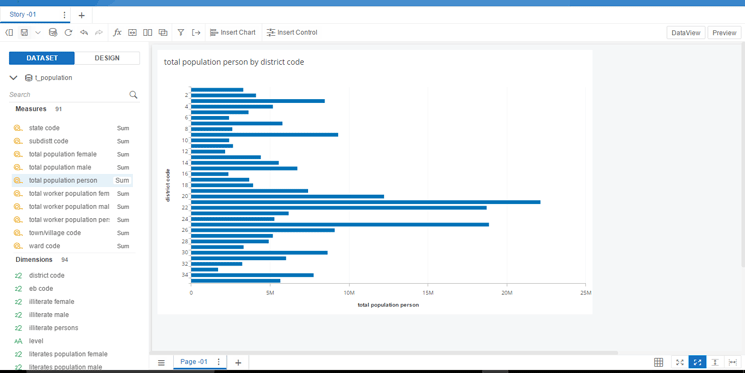
Figure 12
Completed chart built on Cloudera data
Connecting SAP Lumira 2.0 to Hortonworks
The steps to connect to Hortonworks Hadoop follow. They are similar to connecting to Cloudera. These common steps have only been covered in brief in this section.
1. Start SAP Lumira 2.0, discovery component desktop client from the start menu as shown in
Figure 1.
2. Select the Query with SQL option shown in
Figure 2 to go to
Figure 13.
3. Select the appropriate Simba driver under Apache. In this case, select the option for Apache Hadoop Hive 0.12 – Simba JDBC Drivers as shown in
Figure 13. Click the Next button.
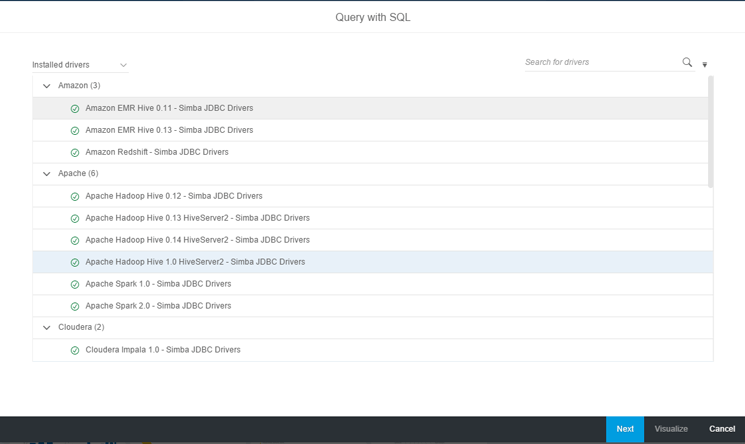
Figure 13
Select the Simba driver for Apache Hadoop
4. In the log-on screen that comes up, enter data in the User Name, Password, and Server (port) fields for the Hortonworks server as requested (
Figure 14). The port for connecting to Hortonworks is 10000.
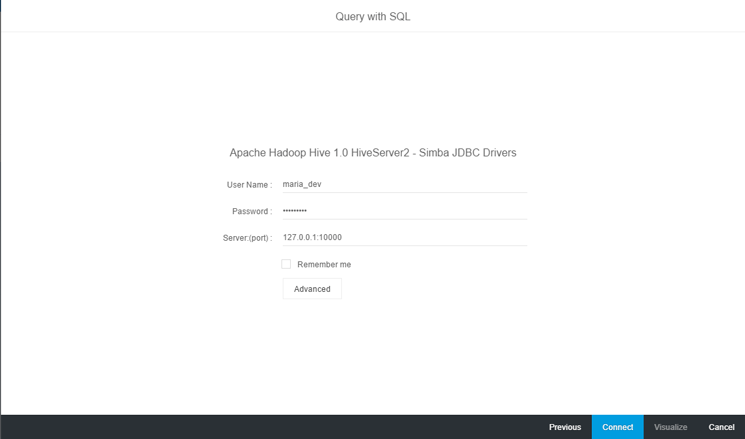
Figure 14
Connect to the Hortonworks server
5. Click the Connect button as shown in
Figure 14. SAP Lumira starts the data acquisition process as shown in
Figure 15.
Figure 15
Data acquisition by SAP Lumira from the Hive table
6. The Hadoop Catalog View comes up (
Figure 16). This screen shows the default database for Hortonworks, which is Hive.
Figure 16
Hortonworks Hive database under the CATALOG_VIEW
7. Select the default database under Hive and the appropriate table (t_population in this case) as shown in
Figure 17.

Figure 17
Select data from t_population and preview
8. Select the dataset from the query. In this case as well, * is used in the query to select all columns in the table. For further information refer to step 7 in the “Connecting SAP Lumira 2.0 Discovery to Cloudera” section.
9. Click the Preview button to see a sample of how the data will look. This view provides a brief overview of the dataset as shown in
Figure 17.
10. Click the Visualize button in
Figure 17.
11. This brings up the DesignView with auto-created dimensions and measures as shown in
Figure 18.
Figure 18
SAP Lumira 2.0, discovery component DesignView
12. Dimensions and measures can be created, modified, or deleted from the left panel.
13. Data manipulation can be achieved by clicking the DataView button, which brings up the DataView details shown in
Figure 19. For further information refer to step 10 in the “Connecting SAP Lumira 2.0 Discovery to Cloudera” section.
Figure 19
SAP Lumira 2.0, discovery component DataView
14. Drag and drop the appropriate dimension from the left pane onto the chart. Combine it with a measure by dragging and dropping the measure into the chart as well. This is shown in
Figure 20.

Figure 20
Drag and drop measures and dimensions onto the chart
15. The data from Hortonworks Hadoop is now shown as a bar graph (
Figure 21).
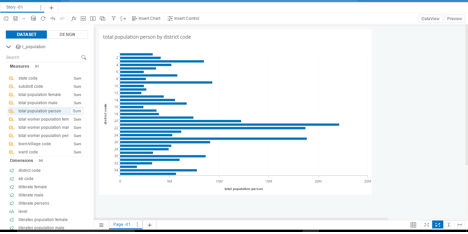
Figure 21
Completed chart built on Hortonworks Hadoop data
The discovery component of SAP Lumira 2.0 provides advanced options to connect to multiple data sources. Datasets from popular Big Data distributions can be explored and analyzed using the new version of SAP Lumira 2.0.
Vinayak Gole
Vinayak Gole is a senior Business Intelligence consultant with 15 years of experience in IT across multiple business domains. Part of the global SAP Analytics Center of Excellence at Tata Consultancy Services, Vinayak has been engaged in architecting solutions on SAP Business Objects suite including Lumira and Business Objects cloud.
You may contact the author at
vinayak.gole@tcs.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.







