Implementing an efficient star schema data model in your BW environment is critical if you expect your system to perform well. The author introduces you to the star schema and explains how it is used across the BW system and in the InfoCubes that underpin the system.
Key Concept
Data modeling in a BW system should reflect the decisions the BW team and other groups made during the earliest stages of implementation. Critical design elements, including ODS and InfoCube structures and load strategies, must be considered in the initial data model. Issues surrounding granularity, which is the lowest level of data BW users can access, must be resolved. If not, you may have to tweak your design — a potentially costly proposition after the system goes live.
The single biggest cause of poor performance during data loads and query retrieval is attributable to poor data modeling choices made early in the BW implementation process. Your initial data model reflects the most important decisions you will make during your BW project and includes such critical design elements as ODS/InfoCube structure, data load strategies, granularity, as well as your overall star schema design.
It is much more difficult to alter your data model after implementation, and most modeling revisions require a data dump and reload. Often, a data model that is sufficient for a lower volume begins to slow down and develop problems as the volume increases. It is imperative, therefore, that you pay ample attention at the beginning of a BW project to ensure the star schema design is optimal and can meet future challenges.
Data modeling is a critical, ongoing process because the data warehouse is evolving to accommodate data loads, new business developments, user behavior, etc. Because of an organization’s changing needs and ever- increasing data volume, you should revisit the data model from time to time to determine if the assumptions you made for the original model are still valid. It is likely that new requirements will be needed and data should be segregated differently by adding new ODS or InfoCube structures or new aggregates.
Entire books have been devoted to star schema data modeling and the subject is vast. I will limit my focus to only the most important decisions required in the BW data modeling process. Beginning with an overview of the star schema itself, I will provide you with some insight into the biggest choices you’ll face as you set up your BW system. Then I’ll show you how to perform BW and InfoCube data modeling.
The BW Star Schema
To understand the BW data modeling process, you must first understand the star schema design (Figure 1). The star schema is, perhaps, the simplest data warehouse schema. It is called a star schema because its entity-relationship diagram resembles a star with points radiating from a central table. At the center of the star is a fact table and the points are the dimension tables. Fact tables used in the star schema are large and contain the primary information in the data warehouse. The dimension tables—also called lookup tables—are much smaller and contain information about the entries for a particular characteristic in the fact table.
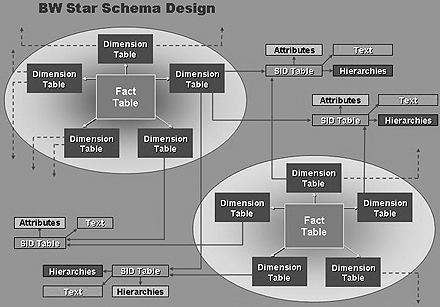
Figure 1
The BW star schema design
The BW star schema is a better design than generic star schemas because it allows master-data and hierarchy sharing during reporting. As a result, BW offers “as-posted” views in the fact table and “restated” values as navigational attributes from the associated master data. I will discuss this in more detail later. The fundamental design of an InfoCube is based on a star schema and includes a fact table and dimension tables. A BW InfoCube query creates a link, known as a “join,” between a fact table and a number of dimension tables.
The main advantages of the BW star schema design are that it:
- Provides direct and intuitive mapping between business entities being analyzed
- Offers highly optimized performance when running queries
- Is supported by a number of business intelligence tools including SAP BW
Tactical vs. Strategic Reporting
The star schema in BW was designed to support aggregating data and reporting on aggregated data for strategic analysis. Problems arise when the assumption is made that BW will be used for all reporting, and no reporting is required from the source transactional system. While BW does a great job fulfilling many analytical reporting needs, it is ill suited for providing others. So, to formulate an effective reporting strategy, you should be aware of BW’s limitations.
To determine your specific reporting needs and ensure that you are using the right reporting tools, it is helpful to classify your information requests into two basic types — tactical and strategic. Tactical reports typically contain real-time, dynamic transactional-level information such a list of those customers on credit hold. Strategic reports gather detailed data into an aggregated format for strategic analysis, the top 10 sales report by region for example.
The star schema design is ideal for the strategic requests, but not for tactical reports. Tactical reporting is often too detailed and dynamic. A system like BW, which stores and processes “batches” of data, cannot be properly updated to deliver this type of request accurately. It requires near real-time reporting on document level information, which is not easily done in BW but can be done more efficiently in the transactional system.
Your assumption should be that BW will not be the sole reporting tool. The source system should continue to be used for tactical, transactional, and operational reporting. BW should be reserved for what is does best — strategic analysis at an aggregated level. Although BW does allow for limited operational reporting from an ODS, it typically cannot provide the real-time level of data detail needed for many operational decisions.
Make the Right Choices Early
Before attempting any data modeling, BW teams need to consider the expectations of the end-user community and some degree of consensus must be reached as to how detailed the reporting will be. This establishes the scope of the BW project.
The following topics should be fully understood and documented in detail:
- Data volume
- Frequency of data update
- Data history requirements
- Restatement/realignment processes
- Batch processing windows
- Query requirements
- Performance expectations
- Query layout and design
- Query delivery method
- Volume of users
If these factors aren’t fully understood, the decisions made in the data model could be incomplete, and thus, inefficient.
Granularity
Granularity represents the lowest level of data a user can access in BW and is critically important for your design. The degree of granularity affects overall system performance because it determines data volume. It can become a point of contention between the data modeling team and the user community.
Typically, users want to access the most granular and detailed level of data. Often they are not aware that the more granular the data, the more adverse the impact on performance. Greater granularity means greater costs both in terms of data storage and query performance.
I recommend that you fully understand the frequency users need to see detailed data at its most granular form, and make sure that the costs are analyzed for the level of granularity chosen. Typically, data loaded on a daily basis is exponentially larger than that same data loaded on a monthly basis.
If there are conflicting requirements on the granularity of data, your data model can be designed to offer a compromise. A granular ODS, for example, can be provided along with an aggregated InfoCube, allowing jump targets to reach into the ODS to view the granular data. This gives a hybrid approach to provide granularity without some of the performance penalties.
Levels of granularity can be determined by looking at the key fields in the ODS (Figure 2) or the characteristics and time characteristic tabs in the InfoCube (Figure 3). Granularity is established from the smallest time characteristic and fields in the characteristics tab in the InfoCube. The more detailed these characteristics, the more data in the InfoCube. For example, adding material and customer to a sales InfoCube is more granular than the same InfoCube with material. This is also true if the data is saved based on calendar day and calendar month or simply calendar month.
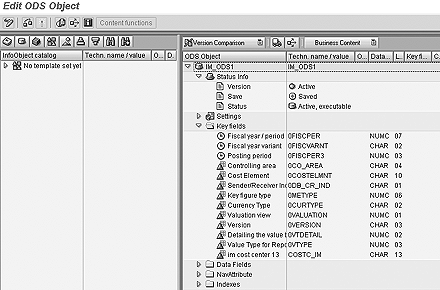
Figure 2
Key fields in the ODS offer insight into granularity
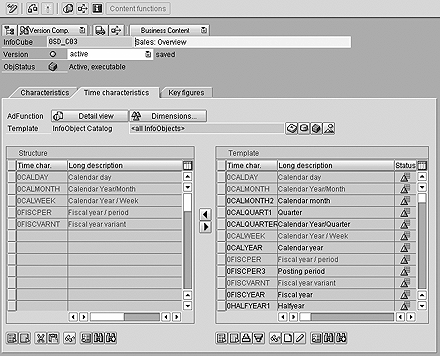
Figure 3
Level of granularity can be determined from an InfoCube’s time characteristics
BW Data Modeling
Once you have determined whether a report is strategic or tactical in nature, and have established the degree of data granularity and volume, you’re ready to consider the actual BW data model. Details of specific InfoSources, InfoCubes, and ODS structures used to load and analyze data are established in the BW data model.
Data volume must be factored in when determining the data model. There is no specific rule of thumb for the number of records that should be allowed in each InfoCube; too many factors come into play. I can offer one general rule: It is much better to have many smaller InfoCubes joined by MultiProviders than one large InfoCube.
In most databases, using MultiProviders allows for parallel request processing. Very little overhead is associated with MultiProviders. In fact, because they support parallel processing, MultiProviders boost performance significantly. Parallel processing is curtailed, however, if all your data exists in one InfoCube.
Whenever possible, each InfoCube should also be partitioned to allow for even more parallel processing if allowed by the database system. Partitioning splits the data in the InfoCube based on time criteria, and data is stored in many separate fact tables rather than one large fact table. This partitioning allows the database to split one query into several separate requests that can run in parallel, which is significantly faster than processing one request.
BW works best when granular data is homogenized into an ODS and aggregated into one or many InfoCubes. An ODS loaded with document-level data should be used to load one or more InfoCubes. This makes for a more sound data model because the InfoCube contains smaller amounts of aggregated data, which improves performance.
Typically, this approach means the InfoCube contains no document-level detail. The lack of transaction numbers (invoice numbers, for example) allows the InfoCube data to be aggregated for strategic reporting. In some instances, document level data is loaded into an InfoCube, but only in cases when the transactional data volume is low because it limits any aggregation and performance suffers. As a general rule, transactional data should be loaded into the InfoCube, just not at the document level.
It helps to have an overall view of the entire data model to see where data exists and how data flows. The BW data model can be viewed in the metadata repository (Figure 4). Because the data model of an entire BW system is so large, you see snapshots of its different components rather than one view.
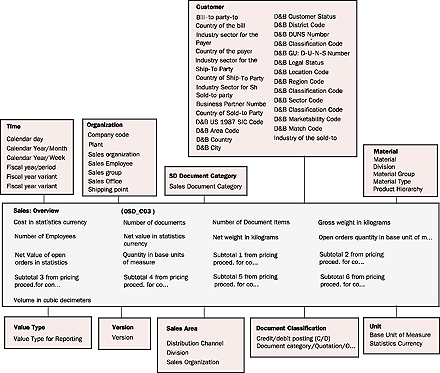
Figure 4
The BW data model can be viewed in the metadata repository
InfoCube Modeling
The InfoCube data model is a subset of the entire BW data model. Proper InfoCube modeling ensures efficient reporting and helps the overall data model achieve its best performance.
When determining the InfoCube data model, transactional-data access should be thought of as both “as- posted” and “restated.” As-posted transactional data is loaded as it is at the time of inception, while the restated view offers associated transactional data with the current master data. The restated view is accomplished by viewing the attributes of master data. This allows for a restatement of data because master data can be loaded independent of transactional data, and these attributes provide the restatement.
Navigational attributes allow queries to display restated values loaded into master data records and provide queries with a current look at the master data. For example, the material master has a material group attribute. If a transactional data record is loaded into the InfoCube, the material group can be linked via the material number and accessed from the master data table during a query. This allows for a restated view because the material master data table can be reloaded often.
By designing InfoCubes with the navigational attributes, you allow queries to be created using the restated values. The as-posted view simply displays values loaded from the transactional data, which does not change. This data is frozen as it was when the transaction occurred.
You want an as-posted view in some cases and a restated view in others. For example, data for an individual salesperson is stored on the customer master data as an attribute and also in the transactional data. As salespeople leave the company, it may be desirable to see who the salesperson was when the sale was created, but it might also make sense to see the current salesperson on the customer master. The star schema design supports both views of data.
Master data attributes can be “display only” or available for navigation. Navigational attributes are established in the InfoCube (Figure 5) and have an adverse effect on performance because the system must read the associated master data dynamically then present the associated attribute. Understanding which characteristics are needed for navigation and which characteristics should be restated is an important part of the data model because of the overhead on the system at the time of query processing.
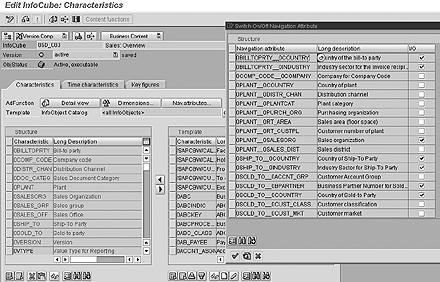
Figure 5
Maintain InfoCube navigational attributes to enhance performance
Dimension Tables Matter
Often, not much thought is given to the dissemination of characteristics to dimensions. Dimension tables, however, have a huge impact on InfoCube performance. The star schema design works best when the database can assume minimal records in the dimension tables and larger volumes in the fact table.
Choosing the characteristics that make up a dimension is an important decision (Figure 6). Each dimension should be of approximately equal size and that the file size of each dimension should not make up more than 10 percent of the associated fact table. The dimensions must also support growth.
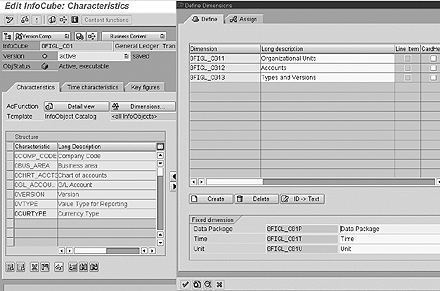
Figure 6
InfoCube dimensions are set up in the InfoCube creation screen
You should make every attempt to split up the most dynamic characteristics so they do not exist in the same dimension. This ensures that the system does not create too many entries in a dimension table.
Consider the following: Order data is loaded into BW with the dynamic characteristics customer and material. If these InfoObjects were to be placed together in the same dimension, it poses a problem for the system because a new dimension record would be created each time the combination of customer or material changed. This would make the dimension very large in relation to the fact table.
Tip!
Transaction code LISTSCHEMA can be used to show the different tables associated with an InfoCube, as shown below.
When one dimension grows very large in relation to the fact table, it makes it difficult for the database optimizer to choose an efficient path to the data, because the guideline of each dimension having less than 10 percent of the fact table’s records has been violated. This condition of having a large volume of data growth in a dimension is known as “degenerative dimension.”
The best way to fix a degenerative dimension is to move the offending characteristics to different dimensions. This can only be accomplished if no data is in the InfoCube. If data is present, however, a dump and reload is required. This underscores the point that the data modeling decisions need to be well thought out during the initial implementation to avoid a dump and reload of data.
Because it is far better to have many smaller dimensions than a few large dimensions, I suggest you identify the most dynamic characteristics and place them in separate dimensions. The current size of your dimensions can be monitored in relation to the fact table by running report SAP_INFOCUBE_DESIGNS in transaction SE38 for live InfoCubes (Figure 7). This shows the size of the fact table and its associated dimension tables. It also shows the ratio percentage of fact to dimension size.
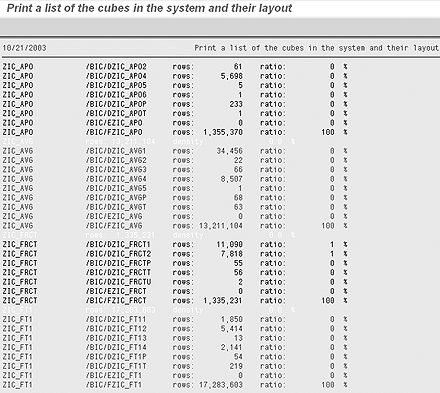
Figure 7
Report SAP_INFOCUBE_DESIGNS
Note
Make sure that statistics are updated for the InfoCube prior to running SAP_INFOCUBE_DESIGNS in transaction code SE38. A dimension that is very large in relation to a fact table should be a red flag. Such issues usually manifest themselves as poor query or load performance.
As I mentioned earlier, BW data modeling is an ever-evolving process. As your business needs evolve and new evaluation methods are added, BW will be used differently. The data model should be constantly evaluated to see if changes can be made to better meet the needs of the users and to ensure the system is performing at its optimal level.






