Data and solution integration is becoming one of the most important aspects in enterprise architecture. Learn about the functionalities provided by SAP data replication and transformation solutions and their proper use.
Key Concept
Modern business solutions often run in a complex enterprise landscape that requires extensive use of data replication and transformation functionality. Tools such as the SAP Landscape Transformation Replication Server, SAP Data Services, SAP Replication Server (formerly called Sybase Replication Server or SRS), and SAP Event Stream Processor (SAP ESP) offer a wide variety of technology, functionality, data sources, and formats to build enterprise-ready data replication and transformation solutions.
Today, most enterprise IT environments support complex solutions that are installed in a distributed environment that requires solution and application integration. The systems may run in local client-based data centers, managed cloud service platforms, or public cloud environments. Additionally, the enterprise data is mainly generated and maintained in internal data sources, such as transactional systems, data logs, and emails, and its integration in the distributed environment becomes one of the key aspects of solution complexity.
I present the possible data replication and transformation options between the old (already running) and new SAP and non-SAP business applications. Included are SAP-provided tools and solutions that support the real-time and batch-oriented replication and transformation of business data.
Insight into Data
Businesses in the digital era have data that comes from a variety of external data sources, such as the Internet of Things (IoT), social media, websites, instant messaging systems, and third-party sources. This means that a lot of data has completely different data formats. Such unstructured data, including audio files, photos, and videos, doesn’t fit neatly into traditional and modern databases such as SAP HANA. That increases the demand and complexity of data management and supporting tools that need to extend to integrate Big Data solutions.
SAP has provided data replication and transformation solutions that allow you to integrate SAP and non-SAP business applications and data sources that can be running on premise or in the cloud. In the first part of this series, I concentrate on the tool introduction. In the second part I discuss various scenarios and their coverage by tools, showing you some options for building solutions in your business environment.
Existing Tools
Let’s start with a short description and the pros and cons of existing tools such as SAP Landscape Transformation Replication Server (SAP LT Replication Server), SAP Data Services, SAP Replication Server (formerly called Sybase Replication Server or SRS for short), and SAP Event Stream Processor (SAP ESP).
Even the best technology wrongly used can result in a solution that does not work properly. Misuse of technology or its wrong configuration can result in performance or functional problems related to data consistency and user visibility (such as access rights and authorizations). Following are points to consider during the design phase of data replication and transformation in an SAP landscape.
Note
SAP also provides the SAP HANA Direct Extractor Connection (DXC) to load or replicate data into SAP HANA by leveraging the embedded SAP BW dedicated functionality in the SAP Business Suite. This replication uses pre-existing foundational data models of SAP Business Suite entities for use in SAP HANA data-mart scenarios. That results in a significant reduction of data-modeling complexity in SAP HANA and an acceleration of reporting and BI implementation projects for SAP HANA. However, because of the defined and targeted use-case scenario it supports, the solution is not presented in this article.
SAP LT Replication Server
SAP LT Replication Server is the SAP solution that supports real-time and scheduled data replication from SAP and non-SAP source systems using trigger-based technology to transfer to the target system, mainly to SAP HANA. Currently SAP LT Replication Server supports replication from all SAP-supported databases (e.g., SAP HANA, SAP Adaptive Server Enterprise (formerly SAP
Sybase ASE), SAP MaxDB database, Microsoft SQL Server Enterprise Edition, Oracle Enterprise Edition, IBM DB2, and IBM Informix).
From a technical perspective SAP LT Replication Server replicates tables from the database that is used by SAP and non-SAP business applications using database triggers. These triggers may slightly hinder the performance of the replication source system. In practice users would notice a performance problem only in extreme situations (e.g., massive table operations such as insert, update, or delete in a database that is already having some performance and resource-related problems).
SAP LT Replication Server runs on the SAP NetWeaver platform and therefore is installed on a separate server or on an SAP ERP Central Component (ECC) system. You should not install this solution on the same SAP HANA appliance server on which the SAP S/4HANA and other SAP HANA-based business solutions are running.
First, an SAP HANA appliance is dedicated hardware for SAP HANA and SAP does not allow the installation of an SAP NetWeaver component on it in a productive environment. Second, the SAP S/4HANA or SAP Business Suite on the SAP HANA app that runs on SAP NetWeaver can be used for installation of the SAP LT Replication Server. However, because the sizing of the server is typically done without an installation of SAP LT Replication Server, you need to consider the required resizing. If the new size calculation allows, then you can install the SAP LT Replication Server solution on an SAP NetWeaver server, but in my experience the save solution is a separate installation on dedicated hardware.
In a production environment it is better to install the SAP LT Replication Server on its own hardware, for performance and ease of managing the updates for software changes.
The SAP LT Replication Server is technically an ABAP add-on to the SAP NetWeaver ABAP stack as a Unicode system. Therefore, several installation options are technically possible:
- On an SAP ABAP-based source system (i.e., an SAP Business Suite system with SAP Basis 7.0.2 or higher)
- On a separate SAP NetWeaver ABAP Stack (Release 7.0.2 or higher)
- On an SAP ABAP-based target system (i.e., an SAP BW or SAP Business Suite system with SAP Basis 7.0.2 or higher)
Figure 1 shows the SAP LT Replication Server installed in a separate system. This three-tier approach is useful when the source system does not conform to the required SAP kernel or SAP NetWeaver versions that are typically relevant for mixed replication. That includes non-ABAP source systems. Additionally, this configuration allows independent software maintenance and flexibility, but requires some investment and maintenance effort for a separate server such as SAP NetWeaver. On the other hand, the integrated installation in the existing SAP NetWeaver instance allows you to reduce running instances, but has an adverse performance impact and defines software maintenance dependency.

Figure 1
Overview of the high-level architecture of the SAP LT Replication Server-based solution
Note
You need to consider that the possible supported use cases for the SAP LT Replication Server can be restricted by the license. For example, if the license for your SAP LT Replication Server is included in the license of SAP HANA Enterprise Edition (Runtime license model and Full-Usage license model), the typical use cases are limited to integration of the SAP systems with a side-by-side SAP system on SAP HANA (for example, SAP S/4HANA). Therefore, check your license before you start using SAP LT Replication Server to replicate and transform data in your enterprise landscape.
SAP LT Replication Server allows you to define the replication jobs using the defined tables in the source system and transfer the definition and content to the target system. In the first replication step you transfer all metadata table definitions from the non-SAP source system to the target system (e.g., SAP HANA). Next, the table replication is started. SAP LT Replication Server creates logging tables within the source system. Afterwards, SAP LT Replication Server uses the read module and accesses the entries using the established database connection, performs the structure and data transformation, and uses the write module with the database connection to record the replicated data in the target system.
The SAP LT Replication Server uses the modules to control the load and replication processes execution and defined data transformations. To perform the initial load and replication process, the SAP LT Replication Server uses the following main jobs:
- Monitoring job - Runs every five seconds and monitors jobs checking whether there are new tasks. If yes, it triggers the execution of master control jobs. The job deletes the already processed entries and tasks from the task table and writes statistics about job execution.
- Master control job - Started on demand by the monitoring job and is responsible for creating database triggers and logging tables in the source system, creating tables and synonyms in SAP HANA, and generating either the load object or the replication objects.
- Data load job - Responsible for loading data, replicating data, and managing the status of entries in control tables. If the job does not complete successfully, the master control job restarts it.
The advantage of SAP LT Replication Server is the support of various replication scenarios. For example, you can define a load scenario in which the SAP LT Replication Server starts an initial load of replication data from the source system as a one-time event. Therefore, the initial load procedure does not require the creation of database triggers or logging tables in the source system. However, you should be aware that after the initial load process is completed, no further changes in the source system are replicated.
Therefore, the replication scenario is the typical most-used scenario that combines an initial load and the subsequent replication procedure (real time or scheduled). In this scenario to support the delta replication (replication of created, modified, and deleted table entries) before the initial load procedure starts, the database triggers and related logging tables are created for each table in the source system.
The SAP LT Replication Server support includes a stop scenario in which the currently running load or replication process of a table can be stopped. This function is very convenient if you’ve detected an inconsistency in the loading results. For example, you have wrongly defined relations to related business data that is not replicated by SAP LT Replication Server. After you have called the stop function, SAP LT Replication Server completely removes the database triggers and related logging tables. However, be aware that after the function call, you cannot continue loading or replicating a selected table from the state or moment when you have stopped it. You must initially load the table again to ensure data consistency.
To avoid this inconvenience, you should consider the use of the suspend function, which pauses the initial load or replication of a table. In this case the database triggers are not deleted from the source system and the recording of changes is continued. Related information is stored in the related logging tables in the source system. Using the resume function, you can later restart the replication for a suspended table.
The advantage of this function is that previously suspended replication is resumed and no new initial load is required. However, the use of this function may have a side effect. The size of the logging tables may increase permanently, even if the data is not replicated to the target system. To avoid problems, monitor the running processes and size of the logging tables. Based on the analysis take respective administrative actions (e.g., stop the suspended replication processes if this process is not needed anymore or adapt the size of the SAP LT Replication Server and its logging tables).
The replication using the SAP LT Replication Server is defined by SAP as a real-time replication, but some data latency can be expected. Therefore, you should consider the evaluation of the sizing of the SAP LT Replication Server, which is described by SAP in “Sizing SAP Landscape Transformation Replication Server for SAP HANA, SP11”:
https://help.sap.com/http.svc/rc/24061ced53984fb0b93e7c98dacef5e4/1702%20YMKT/en-US/SAP_SLT_Guide_21122015.pdf
Note
Latency is the length of time to replicate data (a table entry) from the source system to the target system.
SAP suggests you consider the customer-specific configuration, software version, and proper configuration for the source system (e.g., the number of replication and background jobs in the SAP LT Replication Server and SAP HANA, and the wide range of network factors). The chosen type of data reading could have a significant influence on the performance of the replication solution (e.g., where the parallel data load is possible or an additional data index is required to support replication). You can see more details in “Sizing SAP Landscape Transformation Replication Server for SAP HANA, SP11.”
During the planning of a data replication solution, you may also consider the sizing of the target system, which is typically SAP HANA. For more information about the sizing of SAP HANA go to the “Master Guide to SAP HANA Sizing”:
https://saphanatutorial.com/sap-hana-sizing/
Note
In some cases you may recognize some problems in the initial load or replication to SAP HANA because of the limited number of entries into the non-partitioned table. Therefore, if the table size in SAP HANA exceeds two billion records, you need to split the table by using portioning features in SAP HANA. You should use the partitioning functionality supported by SAP LT Replication Server settings in the configuration of the replication process.
The advantage of the SAP LT Replication Server is the almost-free combination of the number of sources and target systems (although there are some restrictions). This means SAP LT Replication Server supports the replications of multiple source systems into a single target system (e.g., SAP HANA schema), replications of multiple source systems to their own separate target systems/schemas (e.g., different schemas in the same SAP HANA platform), replication of multiple source systems to separate SAP HANA systems, and replication of one source system to up to four separate target systems or schemas (for example, four separate schemas in more than one SAP HANA system).
A useful functionality in SAP LT Replication Server is the automatic Unicode conversion between the source and target systems. This means the table replication can be defined against a non-Unicode source SAP ERP system (its database) to start initial loading and replication to the target system (e.g., SAP HANA). Therefore, you do not need to patch the source system to a Unicode-converted ABAP kernel, which may save you some required investments (for migration, data conversion, and testing) for your SAP ERP source system.
Another advantage of the SAP LT Replication Server is the support of simple transformations. You can define transformation rules in replication configuration that define how the data, its structure, definition, and entries are converted between the source and target tables. The transformation can be grouped into the following rules:
- Skip records
- Convert fields
- Fill empty fields
SAP LT Replication Server supports a simple conversion of data (e.g., anonymizing certain fields, setting an initial value based on the defined conditions and converting units or currency, and recalculating amounts and values using coded rules). This functionality is often used to increase the performance of the target system, especially if additional fields are frequently used to support a business functionality provided by target application. This is because the replications and transformation step is executed only once in the SAP LT Replication Server, and the business process in the target system accesses already converted business data. Otherwise, the replication process is running faster, but the target business application is calculated each time the data is required.
The SAP LT Replication Server solution allows you to adjust the structure and definition of the target table. For example, you can use the SAP LT Replication Server to extend, reduce, or change the table structure and adjust the technical table settings. The typical example is merging the same table from different systems and creating additional fields to avoid duplicate entries (e.g., the use of a new number range to avoid conflicts in integrated data and creation of reference entities to access original systems and records).
Note
You may also consider implementing an advanced data transformation of replicated data in the SAP LT Replication Server by adding custom ABAP code, but be aware that this functionality may significantly hinder the performance and final state of replicated data. Test the ABAP code carefully before you use it to replicate mass data in a productive environment.
The SAP LT Replication Server also supports the integration and replication in cloud-based scenarios. The SAP LT Replication Server can be installed on the on-premise source site and be replicated to the target system installed in a managed or public cloud. It also can be installed directly in the cloud (besides the target system) and access the on-premise running source system. Read more about the configuration in the article “Real-Time Data Replication For The Cloud” at
https://scn.sap.com/community/sap-replication-server/blog/2015/02/28/real-time-data-replication-for-the-cloud.
Let’s summarize the features of the SAP LT Replication Server:
- The SAP LT Replication Server uses a trigger-based approach, which has a very limited or even no measurable performance impact on the source system.
- It allows Unicode conversion between sources and target systems that saves the investment required for migration, data conversion, and testing in the source system.
- It supports an almost free combination of a number of sources and target systems.
- It provides transformation and filtering capability.
- It allows real-time and scheduled data replication, replicating only tables and data into SAP HANA from SAP and non-SAP source systems based on the replication configuration (e.g., including use of filters).
- Replication from multiple source systems to one SAP HANA system is allowed, and also from one source system to multiple SAP HANA systems, which gives wide flexibility for the configuration of the replication landscape.
SAP Data Services
SAP Data Services is an extracting, transforming, and loading (ETL) tool providing data integration, data quality, data profiling, and data processing (including text analysis). It allows you to integrate, transform, and improve trusted data to support business processes in a single environment or multiple environments for development, run time, management, security, and data connectivity.
SAP Data Services is especially dedicated to batch load-based data replication from SAP sources and non-SAP sources with complex ETL requirements mainly required if you extensively use a scheduled load scenario (with no real-time replication).
SAP Data Services consists of a user interface (UI) development interface, metadata repository, data connectivity to the source and target systems, and a management console for job scheduling. The SAP Data Services consists of several components, including:
- SAP Data Services Designer (SAP DS Designer): Allows you to create, test, and execute replication jobs between the source and target systems. It provides development capability enabling the creation of objects. The configuration by selecting data-related business actions results in a source-to-target flow diagram. It allows you to define data mappings, transformations, and control logic workflows for job execution definitions and data flows for data transformation definitions.
- Job Server: Launches the SAP Data Services processing engine and serves as an interface to the engine and other components in the SAP Data Services suite.
- Engine: Executes individual jobs defined in the application you have created using the SAP DS Designer. The SAP Data Services Job Server launches the instances of the engines to accomplish the defined tasks.
- Repository: A database that stores SAP DS Designer predefined system objects and user-defined objects, including source and target metadata and transformation rules.
SAP positions SAP Data Services as a critical component of the SAP-provided and client-specific business applications running on SAP HANA platform, because it helps to discover all formats of data in your organization, including unstructured data. SAP Data Services supports the “standard” databases and the Big Data, cloud, and non-SQL database (NoSQL) systems. This includes the mainly used cloud platforms such as Amazon Web Services, Google Cloud Platform, Microsoft Azure cloud marketplace, and SAP Cloud Platform.
Additionally, SAP Data Services supports the newest databases and runs on top of solutions that include SAP HANA, SAP Vora, HPE Vertica, MongoDB, Apache Spark on Apache Hive, SAP IQ, Apache Cassandra, Teradata, Greenplum Database, MS Analytics Platform System, and Apache Spark. It supports data functionality provided by Hadoop’s MapR, Cloudera, SAP Cloud Platform Big Data Services (formerly known as Altiscale Data Cloud), and Hadoop distributed file system (HDFS) data storage and its formats – CSV, Avro, Parquet, and ORC.
Finally, SAP Data Services provides ready-to-use social media adapters for Facebook, Twitter, and Google+. It natively supports the formats used for unstructured text (e.g., PDF, Microsoft Word, Web log, Microsoft Outlook, Microsoft Excel, and transfer protocols such as File Transfer Protocol [FTP], Secure File Transfer Protocol [SFTP], Pretty Good Privacy [PGP], and Single Sign-On [SSO]).
Figure 2 presents a high-level overview of the SAP Data Services solution that allows replication and transformation of the various resources and modeling of data transformations provided by SAP DS Designer.
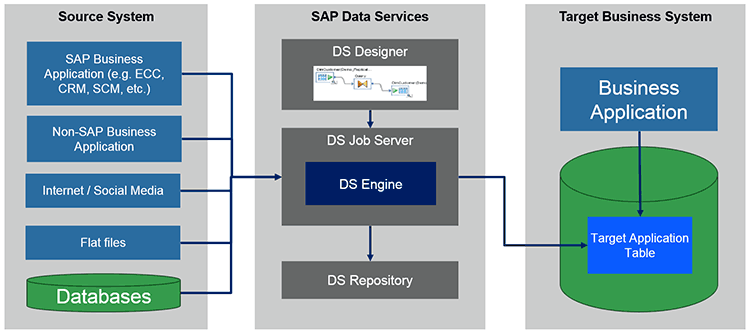
Figure 2
Overview of the high-level architecture of the SAP Data Services-based solution
The advantage of the SAP Data Services is the wide set of provided and supported data transformation capabilities that can be classified into the following four categories:
- Data integrator
- Data quality
- Platform
- Text data processing
The data integrator category supports:
- The functionality covering data transfer (controlling of the flow execution)
- Generation of keys, dates, and effective dates (generate columns with values for the keys of the source data and date values based on the business conditions),
- History flattening (flattening hierarchical data into relational tables building a star schema)
- Creation of pivots (rotates values of columns to rows and vice versa)
- Support of table comparisons and XML-based pipelines (processing of XML inputs and batches)
The data quality category supports:
- The functionality covering data transformations and data cleanse. For example, it identifies and parses text-based business data such as names and titles to find duplicates and similar entries generating additional data meaning and formatting.
- Associates results of data matches and use of geographic coordinates (latitude and longitude) and combines them with business data (e.g., customer, partner, and supplier addresses)
- Matches records based on user and business rules and any client-specific conditions (use of Python code to build user exists providing client-specific business logic)
Additionally, the SAP Data Services provides:
- Functionality allowing unification and consolidation of data from two or more resources (e.g., sources merging and query pruning)
- Case-driven data operating (e.g., simplification of conversion and transformation logic in data flows by consolidating decision-making logic in one transformation unit)
- Data validation (ensures that the data at any stage of transformation meets the validation criteria)
- Data masking from use of data-masking techniques (e.g., character replacement such as number, date, and pattern variances to hide or manipulate business information, including bank account numbers, credit card numbers, or security IDs)
Finally, SAP Data Services includes the transformation functionality combined in the so-called text data processing category. This may help extract text-based data from structured and non-structured sources’ business entities by performing linguistic processing on content. It uses semantic and syntactic knowledge of words to identify paragraphs, sentences, and clauses, and can extract entities and facts from text. The typical use of the functionality is to analyze a text with specific information you want to extract and then use downstream to generate business value.
SAP Data Services can be combined with the SAP LT Replication Server solution. For example, you can use the SAP LT Replication Server to replicate the structured business data from SAP or non-SAP business system and then use SAP Data Services to enrich it with data from different and maybe even non-structured sources. For example, you can use SAP Data Services to excerpt business relevant data from Big Data storage or file systems that contain a business document or social media sources such as Facebook and Twitter. Additionally, this solution is very useful if you need to load files from weird formats, such as fixed format files.
There are some tips and tricks on how to build the optimized replication functionality with SAP Data Services (they may apply to other replications too) that can be combined with the following three golden rules (see the SAP Data Services page for additional information at https://wiki.sdn.sap.com/wiki/display/EIM/Data+Services):
- Perform the major transformations during the replication process into the target system using all the available data sources and not in the target system where the transformation context is not provided. This means that you define the data and its formats during the transformation process in SAP Data Services and not in a separate, next-step process after the data is stored in the target system. That may result in a longer replication and transformation process, but it is typically significantly better from a performance and quality perspective than frequent use of data transformation functionality with missing context information (e.g., not all the data is available in the target system, which may result in incorrect transformation, and the frequently used Core Data Services (CDS) in SAP HANA may provide performance problems).
- Use the parallel process threads (especially in the file loader) for bulk loading on the target table. Commit the size in the target system (e.g., the SAP HANA table loader) to optimize the loading of data in your scenario.
- Be aware of resource consumption of SAP Data Services and make sure you configure enough computation power (installed and available CPU cores), memory, computation threads, and network bandwidth between the source system and SAP Data Services and finally between SAP Data Services and the target system to support all running replication and transformation processes.
Following is a summary of the features of SAP Data Services:
- It is mainly used to replicate data in non-real-time scenarios; this means, it is especially dedicated to batch load-based data replication from SAP sources and non-SAP sources with complex ETL requirements. It is mainly required if you extensively use a scheduled load scenario (no real-time replication).
- It supports a broad spectrum of structured and non-structured data sources (e.g., databases, Big Data, and Internet sources)
- It provides an immense number and variety of transformation and filtering capabilities
- It supports an almost free combination of a number of sources and target systems.
- The data transfer can be automatically optimized, and therefore the data flow could be transformed into sub-data flows executed serially.
- Data transfer transformation creates a temporary database table that is used as a staging table for operation. This ensures the push-down functionality. This means you can optimize the number of rows and operations that the engine must retrieve in the replication process by pushing down operations to the source database, which improves the performance.
SAP Replication Server
SAP Replication Server is a real-time data replication tool that uses database log-based replication from and to various databases such as SAP Adaptive Server Enterprise, Oracle, Microsoft SQL Server, IBM DB2, and SAP HANA. This allows you to support an initial load and replication of the whole database or selected tables with committed transactional data. The replication includes the transfer of database artifacts that are defined using the Data Definition Language (DDL) and Data Manipulation Language (DML), which helps to lower the replication impact in the real-time replication process and guarantees a stable data delivery with zero operational downtime.
Note
SAP Replication Server uses the trigger-based replication for the SAP HANA to SAP HANA replication.
Figure 3 shows the basic architecture of the replication solution using SAP Replication Server.

Figure 3
Overview of the high-level architecture of an SAP Replication Server system
- Source database (also called a primary database). A database that is the source of data and transactions that modify data in the target database.
- Replication agent. A database (depending on the source database)-specific agent that supports data and transaction replication from a source database to a replication server. The replication agent runs as a standalone application and can be installed on the same host as the source database or on any other server that has network access to the source database (access to the transaction logs of the source database).
- Replication server. The server receives replicated data and transactions from the source database via the replication agent and controls its transition to the target database. The replication server (Figure 3) can be installed as a solution divided into a primary replication server, which takes the data from a replication agent, and the replicate replication server, which sends replicated transactions to a target database (so-called replicate database). In small and simple solutions, both servers (primary replication server and replicate replication server) are installed as a single replication server running on one physical server.
- Target database (also called replicate database). A database that is the target of data and transactions that are modified in the source database.
During the initial load and replication, the replication agent reads the transaction log of the source database and generates the Log Transfer Language (LTL) output, which is a notation (using a language) that the replication server uses to process identified and collected data throughout the replication channel from the source to the target database.
The primary replication server receives the LTL from a replication agent and sends the replicated data to the replicate replication server (when a split between primary replication server and replicate replication server is used). Otherwise, the sending does not take place because the data is operated by the single replication server instance). The replicate replication server converts the received data from the LTL to the native format and language used by the target database. It sends the replicate data to the target database for processing, which closes the replication process (if it is committed in the target database).
For data consistency reasons (no loss of data) each replication server uses a database called the Replication Server System Database (RSSD) to store replication data and metadata. This information can be used by a replication agent to provide advanced replication features such as transfer of database data logic (procedures).
The typical use of the SAP Replication Server is the transfer of all data entries and transactions for all tables of the source’s database. This means the initial load and real-time replication of all data and its modifications from the source to the target database. However, the SAP Replication Server allows you to replicate the data by selecting tables and procedures. The replication agent identifies and collects for replication all transactions that are committed, affect the data in that table, and are touched by that procedure.
If a transaction affects both marked tables and unmarked tables, only the operations that affect the marked tables are collected for replication. Operations on unmarked tables are ignored. In the case of a stored procedure, all parameter values provided with the procedure invocation are captured and recorded in the transaction log. If the marked stored procedure maintains (creates, modifies, or deletes) data that affects data in marked tables, the replication collection automatically solves this problem and ignores already replicated data. This guarantees full consistency between the replication configuration of tables and procedures.
SAP Replication Server is often used in SAP HANA high-availability and disaster-recovery scenarios when the real-time data replication between an active and non-active SAP HANA instance is established to increase the availability of SAP HANA-based solutions (e.g., SAP S/4HANA or Business Suite on SAP HANA).
The SAP Replication Server was placed by SAP as the replication solution for SAP ERP scenarios before SAP LT Replication Server with its real-time capability was introduced. Until now SAP Replication Server had some benefits over the SAP LT Replication Server. For example, the use of database logs lowers replication latency and overhead, especially from the source database perspective (also for “long-distance” replication). However, there are some restrictions. You need to have a full enterprise license for your source database. If you are an SAP customer using the restricted run-time license via the Software Application Value (SAV) program (e.g., rent an Oracle or IBM database for 8 percent to 15 percent of its application value), you need to check with SAP to discover the legal aspects of using SAP Replication Server for data replication. In addition, because it works on database logs, SAP Replication Server has some technical dependencies such as Unicode and support of certain versions and certain databases.
Following is a summary of the features of the SAP Replication Server solution:
- SAP Replication Server is the real-time database log-based replication between the source database and target database (such as SAP HANA)
- It replicates data from sources running SAP or non-SAP applications
- The use of read data from the source database log allows replication of an entire database or identified objects (e.g., data stored in selected tables or managed by selected procedures).
- SAP Replication Server supports the replication of changes in DML and DDL.
- It preserves data integrity at the transactional level
- It leverages your existing network to replicate data from diverse geographical locations
- SAP Replication Server normalizes, generates, and sends data using LTL, which allows the flexible adoption of the data to the supported by the particular database formats.
The database log-reading functionality supports filtering and parallelism, which guarantees the good performance of the replication execution with zero downtime for disaster-recovery solutions (use in SAP HANA-based solutions such as
SAP S/4HANA).
SAP Event Stream Processing (SAP ESP)
SAP ESP is the SAP solution concentrating on an increasingly growing demand for support of new event streams (for example, from smart devices, scanners, and RFID readers). The next examples could be streams used in social media: tweets, posts, check-ins, or streams from the financial markets for prices, trades, and quotes. The business solution itself uses the streams to handle user actions in an application, transactions, and workflow events and even to cover the logging events in IT systems. It allows for support of new business functionality that was not covered in the classical ERP system and previous SAP data replication technologies.
From a business perspective the sensors, readers, and scanners can be used in IoT scenarios to monitor and control the execution of business processes. Based on this information you can determine the status of the production line, detect potential problems (e.g., business solutions implementing predictive maintenance scenarios), calculate the current use of machines and resources (e.g., business solutions for the optimization of the production line and sales), and provide data to build models to predict future resources and financial demand (e.g., automatic demand-driven purchasing and calculation of investment for support).
SAP ESP can filter, aggregate, and summarize data from the arriving data before storing it. This enables better decision making based on more complete and timely information. To simplify the development, SAP ESP provides a development platform called SAP ESP Studio that supports the building and testing of event-based applications without a significant programming effort.
Data flows into the SAP ESP Server from external sources through built-in or custom adapters. The adapters translate incoming messages into a format that is accepted by the SAP ESP Server: message formats that are compatible with external destinations such as SAP RAP. (SAP RAP was introduced by Sybase and called at that time Sybase Real-time Analytics Platform or Sybase RAP for short). SAP RAP includes sample schema, sample data, sample queries, configuration scripts, DDL scripts, manual and automated load scripts, and these components for SAP Adaptive Server, SAP ESP, and SAP IQ. SAP IQ was formerly known as SAP Sybase IQ or Sybase IQ, which is a column-based, petabyte scale, relational database software system used for business intelligence, data warehousing, and data marts. The messages are processed by the Sybase Control Center, which provides an operations console for monitoring and managing the SAP ESP Server.
Figure 4 presents a high-level overview of the SAP ESP data processing between source systems (sources of stream) and target systems (e.g., business applications running on SAP HANA).
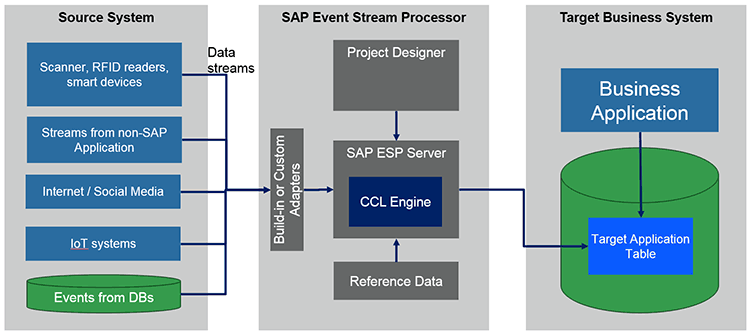
Figure 4
Overview of the architecture of the SAP ESP
The SAP ESP uses the Continuous Computation Language (CCL) for data operations. It is the primary event processing language. The CCL is based on Structured Query Language (SQL). It is adapted for event stream processing supporting data selection and calculation, which includes data grouping, aggregation, and joining. The CCL includes functionality that is required to manipulate data during real-time continuous processing, such as windows on data streams and pattern and event matching, which together with its ability to continuously process dynamic data is the biggest strength of this language. CCL reuses the SQL syntax, but does not use the SQL query engine. This means it compiles CCL into a highly efficient byte code that is used by the SAP ESP Server to construct the continuous queries architecture.
The use of streams and proper configuration of SAP ESP is often the key business value of the implementation. This is what is often referred to “velocity” streaming aspect of Big Data. New data is constantly arriving at a high speed and in high volume, and you face the importance of stream handling to excerpt, collect, and replicate useful business data in real time. Designing the solution using the streams and SAP ESP, you resolve two issues:
- How to manage the ever-growing stream and excerpt the business-relevant data from the current flood of information
- How to turn raw data into useful information and how to understand and act on the information
Testing the solution, its design, and performance helps to guarantee the expected business value. In addition, you should define and build in your solution functionality that constantly checks the quality of the processing and collection of data. This means you should consider if the stream contains the required information and that the stream analytics successfully excerpt the business-relevant data. You should be aware that this kind of check highly increases the quality of your solution. For example, it can inform you about the existing and potential processing and quality issues. Those issues may have a significant adverse influence on the performance of the collected data or may increase the resource requirements of the whole solution (sizing of SAP ESP).
In summary, SAP ESP could replace the typical data loading and database replication solution. Its main features are:
- SAP ESP extends the SAP data integration and replication capability to support streaming technology by event-driven data analysis. It could be used as an alternative solution to SAP LT Replication Server, SAP Data Services, and SAP Replication Server.
- It receives and process event streams from one source or thousands of sources.
- It processes the data as fast as it arrives in either real or almost real time.
- SAP ESP can be used to filter out the noise, according to simple, complex, or even dynamic criteria.
- It can apply continuous queries to monitor trends and correlations. It watches for patterns or compute data aggregations to build high-level value business information.
- It continuously streams to select information for live dashboards and to generate alerts to initiate an immediate business response.
SAP LT Replication Server is strong in the real-time replication scenarios, but you need to consider the potential performance problems. They may occur if you replicate the data from a database that is “underestimated” (e.g., working on limit and the created triggers may cause performance degradation) or if you use the transformation options and do not properly size the SAP Landscape Transformation for the amount of transfer data in your productive environment.
To simplify the overview Table 1 presents a list of key features and use cases that you may consider in the planning of the data replication. You should be aware that this is the first indication of which tool can help you to replicate data in your business scenario. You may need to check some usage conditions (e.g., licenses and term of usage) in your enterprise landscape to integrate and replicate the data from and to SAP and non-SAP business systems.
| Feature |
SAP LT Replication Server |
SAP Data Services |
SAP Replication Server |
SAP Event Stream Processor |
| Real-time replication |
++
|
O (very restricted)
|
++
|
++ / + (depending on complexity)
|
| Batch/scheduled data replication |
+
|
++
|
-
|
-
|
| Transformation |
+ (simple)
|
++
|
+ (simple)
|
+
|
| Streaming data |
-
|
-
|
-
|
++
|
| Replication from SAP |
++
|
++
|
O (license)
|
++
|
| Replication from non-SAP |
O (license)
|
O (license)
|
O (license)
|
++
|
Table 1 Summary of the features and use cases provided by SAP data replication tools
Note
In the table the signs have the following meaning:
++ Very strong support of this functionality,
+ Support of this functionality,
O Functionality supported with restrictions
- Functionality is not supported
In the next part of this series I concentrate on the presentation of typical use cases in which the replication solutions are used to transfer and adapt data to the business requirements. The presented replication solutions can help you build integrate business applications and component on the data layer (on database level) and on the business application layer (on the application level where the business logic is defined), which may have a significant adverse influence on the solution functionality, complexity, and performance.

Robert Heidasch
Robert is the chief innovation and technology lead in the global Accenture Technology Platform, which is responsible for SAP Leonardo and the new digital technology defining business value and driving the digital transformation of complex enterprise solution for Accenture diamond and strategic clients. Before that he was responsible as innovation and solution lead for the design and architecture of new business applications developed jointly by Accenture and SAP based on the newest SAP and non-SAP technology. Robert is the Accenture certified Senior Digital Architect and Senior Technology Architect. He is coauthor and trainer of a couple of SAP technology-related trainings for the in-memory platform and architecture of new business applications (e.g., SAP HANA, SAP Cloud Platform, and SAP Leonardo applications for solution architects and technical architects, all of which were provided by Accenture in Europe, the US, and Asia). Robert has more than 23 years’ experience designing and developing IT systems. He published several technical and business articles about SOA, SAP NetWeaver and its integration with non-SAP systems (e.g. Microsoft, Oracle, etc.), and SAP HANA technology. He is also an inventor of 38 patents in the US in the area of in-memory technology, artificial intelligence and machine learning, security, semantics, and SOA. He is a frequent speaker in international business conferences and SAP Forum. He is a subject matter expert in customer projects worldwide and has extended experience in team leadership in Europe, the US, and India.
You may contact the author at
robert_heidasch@outlook.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.







