You can approach the common task of change validation in SAP ERP HCM in a number of different ways. Deciding among the options depends on the task at hand and the user’s experience, level of skill, and personal preference. See the pros and cons of five common options.
Key Concept
SAP ERP HCM users are often required to work on interfaces to external systems for pensions, health care benefits, or company car providers. Most third-party systems don’t want to receive a complete set of employee data every time they run the interface because they only require transmission of data that has changed since the last time they ran the interface.
When designing an interface, it’s easy to define a set of data entry activities that should trigger interface records to be sent to an external system. A typical definition might be: You should interface all new employees, people who have left, and changes to pay, hours, benefits, or other employee details. Changes made to master data in SAP ERP HCM should be interfaced to the external system as soon as they are detected.
However, considerations regarding the date effectiveness of those records make this triggering more complex. There may be backdated payroll changes, which are often due to the late notification of payments such as overtime. They may also include the late data entry of employees’ joining and leaving dates.
Likewise, you need to account for future-dated records. SAP ERP HCM allows for future-dated records to be input but most interfaces specify that only records effective in the current period are to be sent. Therefore, you must include logic to check the validity of records, not just the date of entry. Beyond this, it may be necessary to store a separate reference record of what was previously sent by the interface to prevent valid changes being missed, or spurious false-positive changes being sent in error.
If an interface does not have well-designed change validation logic, then over time SAP ERP HCM and the external system diverge. New employees may be missing, people who have left may still have active records, and updates may be sent from SAP ERP HCM to records that don’t exist in the external system. This results in tedious and time-consuming checking of error logs and manual update tasks. With the aim of minimizing this type of scenario, you can choose one of the following methods to identify changes.
Check the Infotype Timestamp Field
The simplest method for identifying which infotypes have changed is to check the timestamp. The Changed on Date field (AEDTM) is updated whenever an infotype is maintained in an action (transaction PA40) or master data maintenance (transaction PA30), as shown in Figure 1.

Figure 1
Infotype 0001 record with the change date and changed by fields highlighted
In the simplest case, you could use a select statement to identify those infotype 0001 records that had changed in a date range between the current interface run and the previous time (Figure 2).
|
types: t_pa0001 type TABLE OF pa0001.
data: ta_pa0001 type t_pa0001,
wa_pa0001 type line of t_pa0001.
PARAMETERs: p_begda like pa0001-begda,
p_endda like pa0001-endda.
select * from pa0001
into table ta_pa0001
where aedtm between p_begda and p_endda.
loop at ta_pa0001 into wa_pa0001.
* process records here.
endloop.
|
| Figure 2 |
Sample code to demonstrate how to select infotype 0001 records by the change date |
In practice, you could use an SAP ERP HCM logical database (e.g., PNPCE) to reduce the amount of programming effort required in building the interface. This simplifies the creation of the interface selection screen and automatically checks that the user running the interface has the necessary authorizations. Most significantly, you can use the logical database to make all the database access calls so that the programmer doesn’t have to code these explicitly. The logical database reads the data — a number of HR infotypes — and makes this readily available to the interface program as internal tables. In this case, you could use a provide/end provide statement to loop through these internal tables according to the change date stored in field AEDTM. However, the principle remains that infotype records are selected or filtered using the changed on field. You could build a sequence of similar statements for the other infotypes required by the interface and add associated logic to identify only those changes required by the interface.
While it has the benefit of simplicity, using the infotype timestamp may not provide the necessary level of accurate change detection. The first limitation is that no information about the type of change (e.g., new record, update, or deletion) is stored. If a record was deleted it would be completely missed by the infotype read statement since there is no infotype record with a change date to be read. Therefore, you must use some other method to identify deleted records. The second limitation is that the change date applies to the whole infotype and is not field specific. Updates not relevant to the interface could be sent since there is no means of identifying which field has changed. In the best case, the effects of overwriting a record that already exists on the external system may be benign. However, it is equally possible that in some cases a valid record that has already been sent to the external system and may be overwritten with an incorrect one or the current record may be overwritten by a historic one.
Checking the timestamp may work if the interface requirements are basic. However, if the interface requires retroactive changes, if you need to send future-dated entries only when they become effective, or if you have to cater for any type of interface re-run functionality, then this method may not be accurate enough. Since not enough detailed change information is validated, it is likely that the process will not detect some updates and will generate false positives.
Check Out the HR Infotype Change Audit Report
A more sophisticated approach is to use the change document functionality (Figure 3). Short-term documents are specifically designed for identifying changes to Personnel Administration (PA) master data to transfer these to external systems. The infotypes and fields to be tracked in change logs are defined in a set of interrelated table views: HR Documents: Infotypes to be Logged (V_T585A), HR Documents: Field Group Definition (V_T585B), and HR Documents: Field Group Characteristics (V_T585C). You can use a standard report called Logged Changes in Infotype Data (RPUAUD00) to view the change logs.
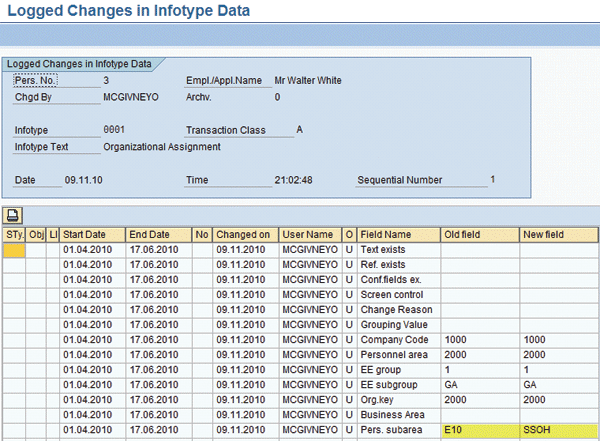
Figure 3
Output from the infotype change log report (RPUAUD00) showing a change to the personnel subarea
Within an interface, you can use SAP-provided function modules to query the change documents:
- List Logged Infotype Records (HR_INFOTYPE_LOG_GET_LIST)
- Read Logged Infotype Records (HR_INFOTYPE_LOG_GET_DETAIL).
This provides an effective manner of identifying changes to PA master data. The system captures a full set of information about each change in the documents, so you can identify the from and to changes for each field.
The creation of change document records can create a significant system overhead and a large volume of change log data that may have performance and archiving implications. The Basis team should understand these potential setbacks before you move forward.
A more significant issue with this approach is that the change documents can be difficult to interpret. This is mainly due to the detailed way in which infotype updates are captured. Take the example of a change to pay action. It copies a basic pay record and enters an increased salary amount from the effective date. This is stored as three separate change documents: the old basic pay record is deleted, another old basic pay record is created with an end date of the effective date -1, and a new basic pay record is created with the new salary starting from the effective date. The challenge lies in creating interface logic so that these three change documents are correctly identified as an update to the employee’s pay. The deletion of the old basic pay record should be ignored in this case. It is essential to gain a full understanding of how change documents are created first. A simple way of doing this is to run through a wide range of PA transactions (e.g., create new records, copy, change, and delimit and delete existing records) and then view the change logs in the standard program before designing the interface logic.
Custom-Build a Snapshot Engine
Another approach is to design a custom snapshot engine. Custom tables (Z tables) are created to store a reference copy of data relevant to the interface (Figure 4). These tables are loaded with employee data in an initial run to form the first snapshot. Then at any subsequent point you can compare the current state of employee data stored in the infotypes against the snapshot. You can easily identify changes and use them to trigger interface records and update the snapshot. You can repeat this daily, weekly, monthly, or at any interval you require.

Figure 4
A custom built or Z-table used in an SAP ERP HCM interface
Some aspects of this approach work well: The change detection method is simple and enables comparison at the field level. On the downside, this approach is wholly non-standard, meaning that HR data is duplicated outside of the standard infotype structures giving rise to the possibility that the data sets become misaligned. Another consideration is that the custom tables may contain sensitive personal information and therefore you might need additional security and authorization objects. Depending on the size of the datasets, there may be sizing and performance issues.
Use Payroll Results to Extract Payroll and SAP ERP HCM Data
Many interfaces to pension, health care, and benefits providers are required to send both payroll and HR data. First the interface checks for changes to the employee infotype data (e.g., change in hours or pay) using one of the methods above, and then wage types are derived from the payroll results. What may not be appreciated is that the payroll results may have already evaluated all relevant changes to the employee’s PA master data and stored them in a readily accessible way. The payroll schema may have identified changes to the employee status in such a way that it isn’t necessary for the interface to derive these from first principles by looking at the infotypes. Since the payroll results are already being read, only a small amount of additional work is required to read the changes to PA data stored in payroll.
Standard function modules available for reading the payroll results such as PYXX_GET_EVALUATION_PERIODS are well documented and are beyond the scope of this article. The payroll results consist of a nested structure. Of most interest are the results table (RT) and cumulative results table (CRT), which hold the wage types. Often overlooked is the Payroll Results: Work Center/Basic Pay (WPBP) structure (Figure 5). It contains a large dataset derived from infotypes 0000 (employee’s action), 0001 (organizational assignment), 0007 (planned working time), and 0008 (basic pay).
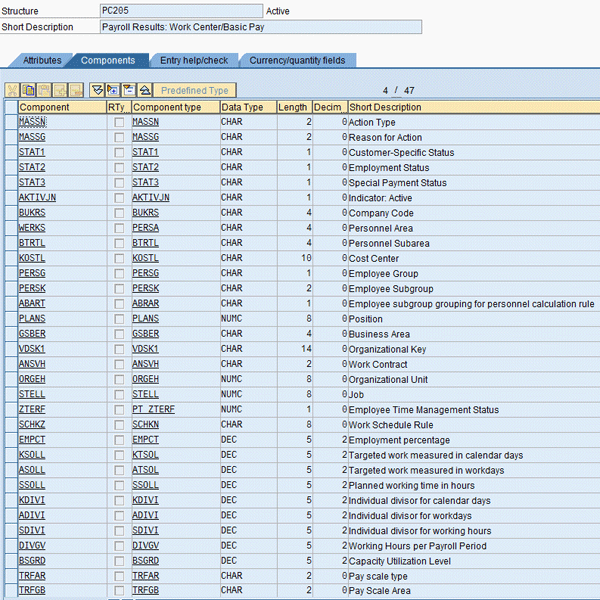
Figure 5
A partial field listing of the fields in the WPBP structure
The system automatically adds a new line entry (called a split) to this structure whenever a significant change occurs during the current (or in a previous) payroll period (Figure 6). By checking for splits in the current period, or by comparing this month’s WPBP structure against last month’s WPBP, you can identify changes to the employee such as changes to pay or work schedule or joining and leaving actions.

Figure 6
A WPBP split in an employee’s payroll results identifies that an employee left the company on September 10, 2010
You can add code to use this as a trigger mechanism if you require further infotype information not available in WPBP. Other structures in the payroll results may provide additional change information such as the Bank Transfer structure (BT) or the pensions structure (PEN).
This approach is only possible when the interface frequency and the payroll frequency are the same. A good understanding of the structures used in payroll is a prerequisite, as is a complete understanding of retroactive accounting functionality and the different types of splits.
Become Familiar With the Interface Toolbox
The HR interface toolbox (transaction PU12) is an effective and functionality-rich medium for designing effective change-based interfaces. A wide variety of documentation on the Interface Toolbox is available, including the following comprehensive SAPexperts articles:
The interface toolbox (Figure 7) allows the user to select the data sources for the interface (such as PA, Time Management, and Payroll) and then drill down further to select tables, fields, or data structures using check boxes. You can specify the change validation requirements (which determine the way in which data is only exported if it has changed) using a predefined set of options. These selections are then used to generate an ABAP export program. The user subsequently defines a conversion program that carries out all necessary conversion, formatting, and mapping to the data extracted by the export program. It is possible to create an interface without any custom code, although in practice it is more likely that you use the toolbox to create an interface framework and insert custom code at the appropriate points.
The interface toolbox provides a wide range of change validation functions. You can set up specific change validation behavior for:
- Changes at the table or infotype level
- Changes at the field level
- Linked changes at the field level so that if one field changes, a predefined set of related fields can also be output by the system automatically
- Specific response to record creation, deletion, or delimitation
- Customer-specific change validation routines
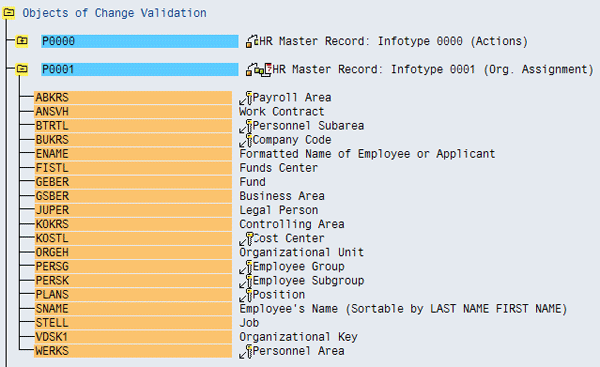
Figure 7
A number of infotype 0001 fields identified as key fields for the automatic change validation routine
The interface toolbox stores a reference copy of all the data extracted within the clusters, and is therefore able to compare the current infotype or payroll data against this reference copy to drive the change validation. All the coding necessary to read and write this information to the clusters is generated automatically, so that their use is transparent to the user.
The interface toolbox requires a large initial investment in time to become familiar with the amount of functionality available. Perhaps for this reason this tool is frequently overlooked, and developers resort to more standard ABAP approaches. In my experience this can be a mistake as the initial time spent is more than repaid in the effort saved in not having to redesign functionality to cope with the specific structures found in payroll, Time Management, and PA, or to create effective methods of identifying changes and dealing with retroactive accounting. Developers don’t have to write code to extract and process data from the infotypes or payroll and time clusters as this is all generated automatically. It allows them to concentrate on the more demanding issues specific to that interface such as the interface logic or treatment of retroactive accounting.
Owen McGivney
Owen McGivney is a senior consultant at iProCon Ltd., part of the iProCon group, based in London, England. He has worked on implementing SAP HR and payroll systems since 1998. Owen has delivered UK, Irish, and multi-national payroll solutions for a wide range of private- and public-sector clients. He has a special interest in combining ABAP programming with configuration to create innovative and effective solutions.
You may contact the author at o.mcgivney@iprocon.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.





