SAP HANA has features to both manage data and improve data quality that many SAP users might not know exist. These new options offer real-time transformational possibilities that were unthinkable until recently. Learn about the tools you can use to cleanse, match, or enhance data in real time with Smart Data Quality.
Key Concept
Many define data quality as whether data is fit for use. Poor quality data can make or break an analytics endeavor for an organization. Without quality data real-time analytics can offer little value to the organization. Using SAP HANA developers will not only offer real-time analytics, but analytics of high data quality as an output. This offers credibility to the solution and helps prepare data in real time for better utilization.
Data quality is always a challenge for organizations seeking a robust analytics solution. If the data does not conform to high quality standards, then the analytical capabilities of the solution are highly diminished.
Data quality is even more important for a real-time analytics solution based on SAP S/4HANA. Take a recent experience I had with a company with a dashboard that is powered by an SAP HANA ERP system. This analytics solution allowed the company to have unprecedented access to real-time operational data. The business was very excited about the new capabilities and the value that this would bring to the organization.
However, when the solution was demonstrated to the chief financial officer (CFO), all the excitement around the new capabilities began to stall. The CFO had so much knowledge of the business and history of the company that he could immediately tell that the numbers in the dashboard were not possible. All development was halted until the data quality issues could be remediated.
Problems like this are very real when speaking about the real-time data access that SAP HANA provides. This is a problem that cannot be handled by legacy batch-based tools as the solution would be in real time. Fortunately, SAP has a pretty unique solution in SAP HANA to help with real-time data quality issues: SAP HANA’s Smart Data Quality tool.
Smart Data Quality in SAP HANA allows a developer to combine functionality to fully transform data that would normally be limited to SAP Data Services or other batch-based extract, transform, and load (ETL) programs. It can perform those transformations in real time as the records are created in a source system. Developers can provide data-quality enrichment to a person or firm/business, and address data literally as the data is being created in the source system. Figure 1 shows a Smart Data Quality flowgraph that performs operations to accomplish these transformations.
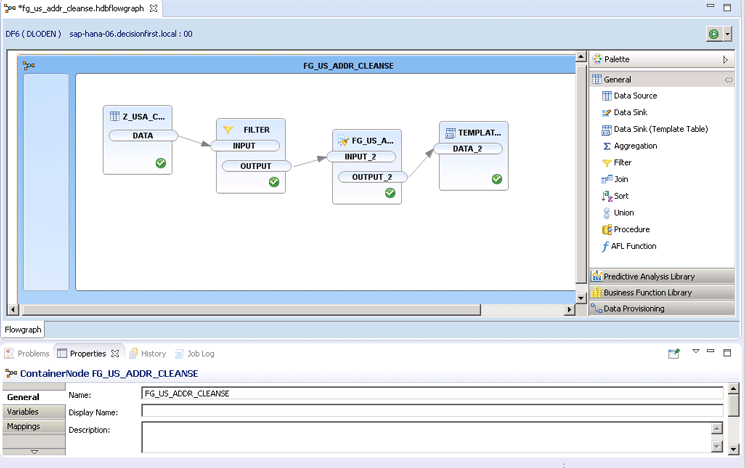
Figure 1
Example of a Smart Data Quality flowgraph
This example shows a source table, Z_USA_CUSTOMERS. This table contains both the customer name and business names, as well as the associated address of the customer. This is a typical layout for a variety of systems as well as a good starting structure for a reporting dimension table. I show how to use the flowgraph that is constructed in Figure 1 to cleanse the customer and customer address information to enable greater reporting capabilities when this customer data is used in reporting as a dimension.
To accomplish this, create the flowgraph file, which is just another type of file in SAP HANA development, by navigating to the development perspective in SAP HANA studio and selecting a package. Right-click that package to produce a pop-up menu. The example package in Figure 2 is the package titled donloden.

Figure 2
The donloden package
After you right-click the donloden package, click New from the pop-up menu. Then click Other… . A new window appears where you can browse for the type of object you wish to create. To do this, the easiest method is to start typing the word flow. This starts a search in SAP HANA to produce the selection called Flowgraph Model. This searching and selection process is shown in Figure 3.
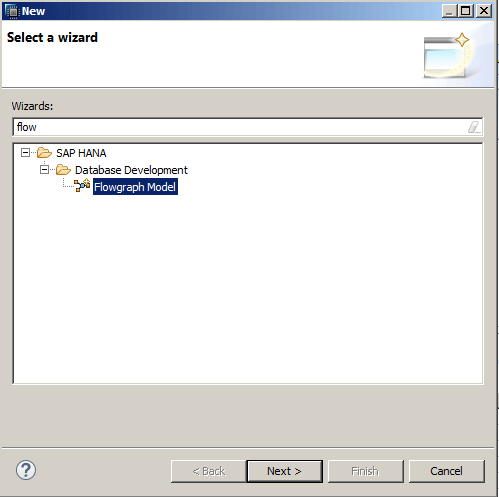
Figure 3
Create the new flowgraph
Click the Next button to create the basic Flowgraph Model that is the starting point of the one that is shown in Figure 1. You then step through many of the tools in the tool palette to create the Smart Data Quality flowgraph to cleanse and enrich the data.
The first step is to select the source of the customer data that is being cleansed in this example. Select the Data Source node under the General section from the tool palette on the right side of the screen, as shown in Figure 4.

Figure 4
Select your source data table for cleansing
This first step is important as you now have data to read into the flowgraph for cleansing. Also, pay special attention to the Realtime Behavior: field, highlighted in Figure 4. If you want to make the reads in real time as the data is occurring natively in the source table, then check the Realtime check box. Now, as data is created in the source system, it flows into the flowgraph to be transformed on the way into SAP HANA. In Figure 5 you can see where to filter the incoming data.
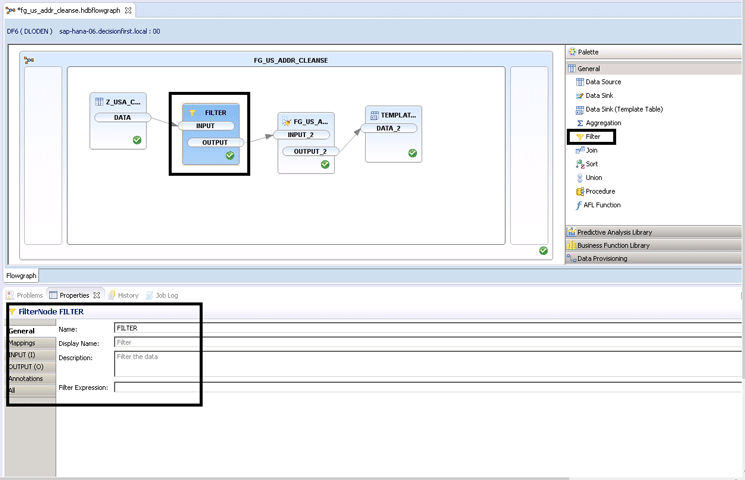
Figure 5
Filter node configuration and the Filter Expression: field location
In this example I do not filter any of the incoming customer records, as I want to show how successful SAP HANA can be with cleansing and enriching records. The Filter node is only present for reference, as it can be very useful to limit your cleansing result set. For instance, if you were only licensed for United States address cleansing, it would make sense to filter on a country field. Now, I examine the heart of the SDQ cleansing flow: the Cleanse node. The Cleanse node is shown in detail in Figure 6.

Figure 6
Input Field configuration of the Cleanse node
Notice in the Cleanse node that there are three tabs: Input Fields, Output Fields, and Settings. The Cleanse node is different from many other transformation objects (under the palette on the right side of the screen) in that the developer has access to cleansed data from an SAP system as well as various postal services around the world. The way this node is used is that fields are mapped fields from input tables or source data and then you select the output fields that you would like to be visible and output to the target table or system. Table 1 describes the three tabs and their functions.
| Tab name |
Tab description |
Input Fields
|
Fields for the source table or system that can be mapped to various input fields for cleansing. These include address data as well as person and firm (business names) data. |
Output Fields
|
The Output Fields tab is the third-party reference data elements (provided by SAP and various postal organizations) that are returned by the Cleanse node. Note that licensing from third-party postal agencies is required for the postal organization fields functionality to operate.
|
Settings
|
Default settings that are found here can be altered to suit many common development tasks. |
Table 1
Descriptions of the Cleanse node configuration tab options
To configure the Cleanse node, you map the input fields into the Input Fields tab, as shown in Figure 6. The fields that I mapped for this sample exercise are listed in Table 2.
| Input field type |
Cleanse Input field |
Mapping/table field |
Address
|
Street Address: Free Form |
ADDRESS
|
Address
|
Street Address: Free Form 2
|
CITY
|
|
Address
|
Street Address: Free Form 3
|
POSTAL CODE
|
Firm
|
Firm |
FIRM
|
Table 2
Cleanse node of the input tab field mappings
The Cleanse Input field is the function of the Cleanse node that you wish to use. Notice that I have used the Free Form option in the Street Address section (Figure 6). This means that any relevant street address data that is country specific in any of the mapped fields from the source table is considered for cleansing. This is a feature that allows for cleansing and enriching of data fields even if the contents of the table fields are mismatched to the field descriptions. For example, if there is address line information in the city field, the cleansing operations would still work. Now that the fields are mapped, consider which data elements to output from the Cleanse node. These are shown in the Output Fields tab in Figure 7. You select them by setting Enabled to True. The bottom screen is open already. It expands when you select the Cleanse node as shown in the figure.
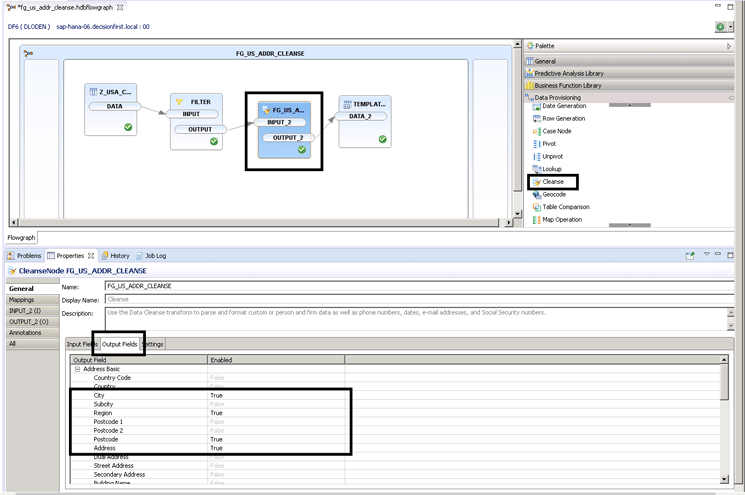
Figure 7
Output Field configuration of the Cleanse node
As a review, these are the cleansed data elements that I return from the Cleanse node in my SDQ flowgraph:
- City
- Region
- Postcode
- Address
Now that the data is cleansed and enriched, it is time to output the data to an SAP HANA target table. This is performed by using a Data Sink from the General section of the tool Palette on the right side of the screen in Figure 8. You drag and drop from the right side Palette onto the middle white canvas to use it in the same way you use other nodes and tools. The section of the screen at the bottom dynamically changes based on what is selected.
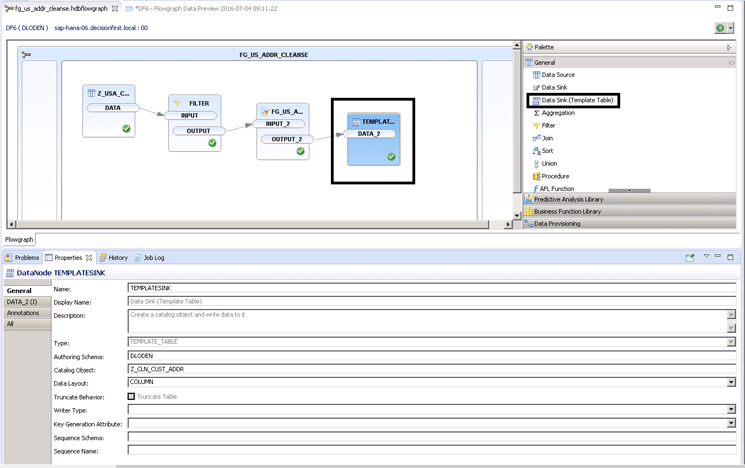
Figure 8
Target template table configuration and schema destination
The target configuration is straightforward. You declare the Authoring Schema that is the target or destination schema location in SAP HANA by typing the schema where you will land the data in SAP HANA into the Authoring Schema field. In this case you put the data into the DLODEN schema since that is what we specified in the Authoring Schema field. You also need to declare a Catalog Object to create in this schema as the Data Sink creates a table in SAP HANA based on the fields and data types that were used as outputs in the Cleanse Node. This is performed by choosing a table name and entering this name into the Catalog Object field. For my example, the Catalog Object is called Z_CLN_CUST_ADDR. (You do not need to save as SAP HANA saves with every field exit.) This creates a new table in the DLODEN schema called Z_CLN_CUST_ADDR.
To view the data in the new table after executing the flowgraph, you merely select the data via SQL as you would in any other table in SAP HANA. Figure 9 shows the table I made in this example.
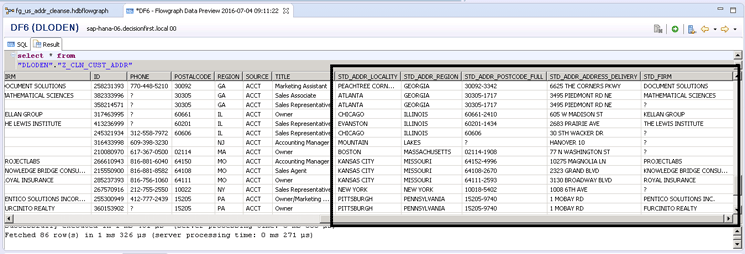
Figure 9
Data quality Address and Firm fields produced by SAP HANA Smart Data Quality flowgraph
You can see all the new STD_ cleansed fields that are now present in the target table. All the original source data is left unaltered for this example, and the new cleansed data elements are side by side in the table with the original field contents. This is helpful for debugging as well as for use as display items in downstream applications.
This completes the development of the real-time-enabled SAP HANA SDQ flowgraph. As you can see it is a graphical development environment with many concepts that an ETL developer would find familiar. This is important as mature SAP HANA companies are focusing increasingly more on cleansing and data enrichment. These capabilities exist to extend the development platform to perform real-time transformation tasks that set SAP HANA apart from other data-warehousing tools.

Don Loden
Don Loden is an information management and information governance professional with experience in multiple verticals. He is an SAP-certified application associate on SAP EIM products. He has more than 15 years of information technology experience in the following areas: ETL architecture, development, and tuning; logical and physical data modeling; and mentoring on data warehouse, data quality, information governance, and ETL concepts. Don speaks globally and mentors on information management, governance, and quality. He authored the book SAP Information Steward: Monitoring Data in Real Time and is the co-author of two books: Implementing SAP HANA, as well as Creating SAP HANA Information Views. Don has also authored numerous articles for publications such as SAPinsider magazine, Tech Target, and Information Management magazine.
You may contact the author at don.loden@protiviti.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.








