With wireless communication and mobility applications growing, telecommunication billing systems have to process a large volume of data in a near-real-time manner. The billing system is among the critical components in a telecommunication company’s IT landscape, so a high-performance mediation engine, providing high availability, data integrity, and system throughput, is critical. Learn about the architecture of the mediation engine on top of SAP NetWeaver 7.0 and the architectural choices made in satisfying the requirements of the mediation engine.
Key Concept
The mediation engine in SAP NetWeaver 7.0 reads and validates call data records for telecom and utility companies. It also allows you to log errors and then reprocesses the records once errors have been corrected. Most importantly, it is a mediator among SAP ERP Central Component, SAP Convergent Charging (a rating and pricing engine), and reporting systems such as SAP NetWeaver Business Warehouse.
The primary source of revenue of companies in the telecommunications industry is their customers. The company charges a monthly fee based on the total number of seconds the services (e.g., phone call, email, Internet browsing) are used or active. For example, “email” and “phone call” might be two services for which a user is billed. Obviously, a typical telecom company has millions of users and each customer uses different services several times a day. A single use of service creates two records in the provisioning system: the start and the end of the service use. These records are called call data records (CDRs). The CDR represents the entry point to the telecom company billing systems. The CDRs have to be retrieved from the provisioning system, validated against the company rules, processed, and stored in a local database in an aggregated manner.
SAP Convergent Charging (SAP CC) is SAP software that allows companies to rate such records. SAP CC is a high-volume pricing and rating engine, but it requires a mediation engine solution to preprocess the CDRs. The mediation engine is an intermediate component between the provisioning system and SAP CC. It has to prepare the data for SAP CC by validating and aggregating the CDRs. The provisioning system sends the start and end event records to the billing system.
For example, if Service X starts on January 1 at 10:00:00 am, a start record comes from the provisioning system. When Service X ends on January 1 at 10:10:00 am, an end record is sent. The billing system has to charge the customer for the period of time the service was used. The mediation engine reads these two records and aggregates them to be able to be rated and processed by SAP CC and the billing system.
We’ll explain to you the requirements of a mediation engine conceptually, and then show you how it reads and processes the CDRs. Then we’ll cover the architecture that you should use to construct the engine, including the different layers involved. Finally, we’ll show you some example measurements and results.
Mediation Engine Basics and Requirements
The mediation engine has to handle a huge volume of data. The provisioning system provides several million records a day and this number is expected to increase on a monthly basis. In general, the mediation engine has to:
- Read the CDRs
- Validate the CDR content based on business rules
- Maintain a mediation database that has tables representing the statuses of services on specific devices
- Log the exceptions and errors, and send the alerts
- Allow reprocessing for the corrected records
Figure 1 shows the business process of the mediation engine at a conceptual level. Five systems are involved in this business process: the provisioning system, SAP ERP Central Component (SAP ECC), SAP CC, a reporting system (e.g., SAP NetWeaver Business Warehouse [SAP NetWeaver BW]), and a mediation engine. Let’s look into those in more detail:
- Provisioning system: This is the source system of the main transactional data — the CDRs. The provisioning system should be designed to provide a set of new records periodically. For example, it produces around 30,000 new CDRs every 15 minutes. It should also be designed to create these new CDRs in a separate table (or file). This table later acts as a queue of CDRs.
- SAP ECC: This is the system for master data and configuration data. The customer and service information have to be replicated to the mediation database. The mediation engine uses this data to implement the CDR processing logic.
- SAP CC: SAP CC provides a rating and charging solution for high-volume processing in service industries. It delivers pricing design capabilities, high-performance rating, and convergent balance management. It provides a Java API that allows the mediation engine to rate the service uses (e.g., number of billable hours or days).
- Reporting system (e.g., SAP NetWeaver BW): This retrieves the transactional and master data for reporting purposes.
- Mediation engine: This component is the main subject of this article. It represents the role of a mediator among the provisioning system, SAP CC, and the reporting system. Its main role is to prepare and manage the data for SAP CC, the invoicing module, and the reporting system.
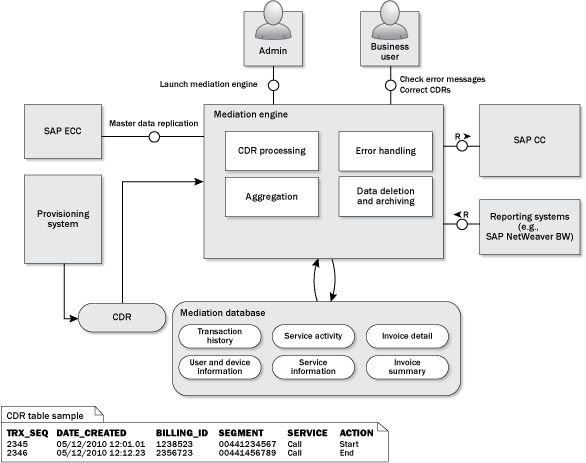
Figure 1
Mediation engine conceptual view
Two users are involved in this process. An admin user connects to the mediation engine system, sets the selection criteria, and runs the mediation engine. The admin user should be willing to run the archiving process for some mediation tables or schedule the archiving job. A business user connects to the mediation engine system, sees the exception and error logs, and then corrects the records that were processed with errors.
CDR Retrieval
The CDR stores the information related to the use of the service. Generally, it contains:
- The transaction sequence that identifies the record, date, and time of the event
- The billing ID that identifies the consumer
- The segment that categorizes the consumer (e.g., carriers, regions)
- The service that identifies the service that is used (e.g., email, phone call, Internet browsing)
- The action that represents the type of event (e.g., event start, event end, activation, deactivation, and modification of service)
Figure 1 shows an example of a CDR.
The provisioning system stores the CDR in a separate table or file. The table might reside in a different database that has to be accessed remotely by the mediation engine. The mediation engine concentrates on the CDR table. It retrieves the data from this external CDR table and processes, calculates, and stores it in its own database tables for processing by SAP CC and the invoice process. The mediation engine uses the CDR table as a queue, allowing the possibility of deleting the processed records from the table.
CDR Processing
Upon receiving the CDRs, the mediation engine analyzes its content. The Action field determines how the CDR should be processed. The processing depends on the action type. The mediation engine processes the start, the end, and the modification event differently. However, the CDR processing has the following common phases:
- Saving the transactional level of details, indicating when it was copied and processed or if there is an error state
- Storing the creation date of all transactions in the local time zone of the customer segment
- Validating all transactions against existing customer segments and services
- Validating transactions for duplicates
- Creating or updating a billable record with a start date or end date
- Maintaining the status of the services
- Stopping the further processing of a billing ID when there are uncorrected errors for at least one record of that billing ID
- Clearly identifying and storing failed validations or transactions with missing key data along with the reason
Figure 2 shows an activity diagram for CDR processing.
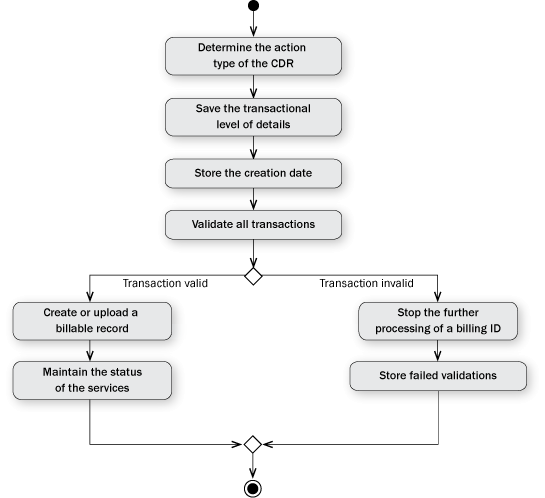
Figure 2
CDR process flow
Now we’ll go over the steps that any algorithm has to implement to process the CDRs. However, each telecom company has its own business rules. Hence, the algorithm should include these business rules in the CDR processing.
Challenges of Designing a Robust Mediation Engine
As stated in the previous sections, the mediation engine has to process a huge volume of CDRs and it should be done in a timely manner. The prepaid and postpaid service implies that the processing should happen as soon as the CDRs are available in the provisioning system. According to our experience, the number of records to be processed easily reaches 4,000,000 records a day and is expected to increase by almost 5 percent per month. The mediation engine should also consider that the sizes of the database tables are very large. As the CDR processing consists of reading and updating database tables, the design of the mediation engine should use optimal SQL statements.
The provisioning system is expected to produce the CDRs continuously. The mediation engine should have an architecture that allows the active component to run continuously. The mediation engine should be available 24 hours a day. At the same time, the mediation engine should be able to react to the configuration update and to the master data update. These modifications to the configuration and master data should be taken in consideration without any interruption to the mediation engine execution.
While processing the CDRs, the mediation engine has to validate the CDR data and business rules. The mediation engine should log all the exceptions and errors with meaningful text describing the reasons. It should provide performance statistics of the engine. After waiting for a configurable period of time and finding no CDR transactions in the CDR queue, the mediation engine needs to raise an exception to alert business users.
The exception and the errors have to be corrected. Consequently, the mediation engine solution should provide a user interface (UI) that empowers the business user with tools to make the appropriate correction to the system. The UI error correction should provide the ability to make updates to any field in an erroneous transaction, to reprocess an erroneous transaction after a correction has been made, to reverse or cancel an already-processed transaction by initiating an opposing status change transaction, and to have an erroneous transaction skipped or ignored for subsequent transactions to continue and allow for the correction of records in a massive way.
As stated previously, the mediation engine interacts with several active components. It reads what the provisioning system produces and makes the data available to SAP CC, the invoice process, and the reporting system. These interactions imply a constrained synchronization between the mediation engine and the other components. This synchronization is made more complicated by the necessity that it be done in a timely manner. The invoice process and reporting should start to run after the mediation engine finishes its work, and on the other hand the mediation engine should read the records that are complete in the provisioning system. The records have to be processed in their transaction sequence order; otherwise, the business rules are not satisfied and the CDR processing generates a tremendous number of errors. For example, the rule, start event, and end event that are processed in order end up failing.
Architecture of the Solution Using the SAP NetWeaver Platform
You should use an architecture that uses the features of the SAP NetWeaver ABAP platform to build the mediation engine that meets these requirements. The parallel processing of CDRs allows for improving the performance of the system and makes the mediation engine a scalable solution.
Architecture Overview
You should construct the mediation engine’s architecture to handle all the challenges and requirements that we have described in the previous sections. The proposed solution consists of the implementation of a new ABAP component for the mediation engine. Figure 3 shows the architecture overview. The proposed architecture of the mediation engine is structured as follows:
- A master data and configuration replication component that receives the master data (segment and services) using SAP NetWeaver Process Integration (SAP NetWeaver PI) from SAP ECC and updates the mediation database tables. This component also handles the configuration replication from the leading system to the mediation engine.
- A distributor component that retrieves the CDRs from the CDR queue table. It connects remotely to the provisioning database and continuously reads the records. Then the distributor splits the record processing into several work processes. The sets of CDRs are processed in parallel.
- Several work process CDR processing components get a set of CDRs from the distributor and process them. In doing so, they validate the business rules, update mediation database tables, update the CDR table in the remote provisioning system, and return the processing statistics to the distributor.
- An error handling and record correction component that provides a UI to business users to be able to show the exceptions and correct the CDRs. All CDRs are stored in a transaction history table. However, for this part only the records with errors are stored in an error table so you can reprocess them. The UI is a Web Dynpro ABAP application.
- An aggregation component calculates the billable days per service, service group, and segment. After the calculation, this component calls SAP CC to rate the billable days using an SAP Java Connector (SAP JCo). The results are stored in a summary table.
- A data access layer component provides the classes that are used by the other components to access the data stored in the database tables (local and remote)
- The data extraction pulls the data to the reporting system
- The archiving component uses the SAP Archive Development Kit (ADK) to implement an archiving mechanism that removes the unnecessary records from the mediation database. This archiving mechanism is required to keep the mediation engine tables at reasonable sizes to avoid severely affecting performance.
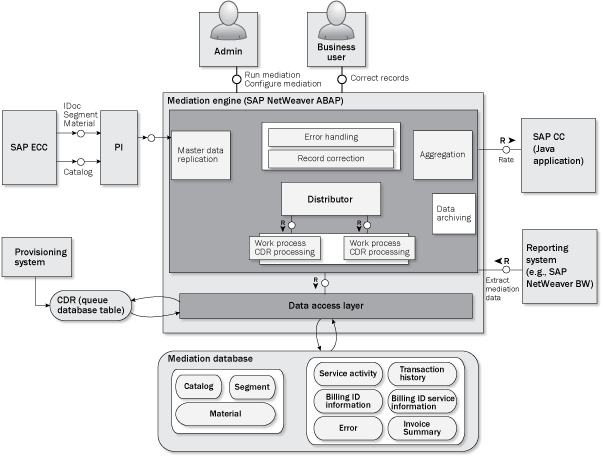
Figure 3
Architecture overview (technical view)
Distributor and Business Logic Layer
The distributor and business logic layer components are at the heart of the mediation process. The distributor retrieves and organizes the incoming data into logical CDR groupings. A separate task of the business logic is then initiated for each of these CDR groupings. The size of the CDR groupings is based on a configuration parameter making parallel processing adjustable. Each of the work processes returns a summary of the work done and the distributor accumulates the statistics. When all the data is processed, the distributor writes the statistics to an application log and triggers an event to start a new instance of the distributor after this instance ends.
The business logic layer comprises the actual work that is carried out on the data. This code performs all error checking and business functions to process the incoming data. It interfaces with the data access layer and configuration management.
Figure 4 shows an overview diagram of the distributor and business logic components.
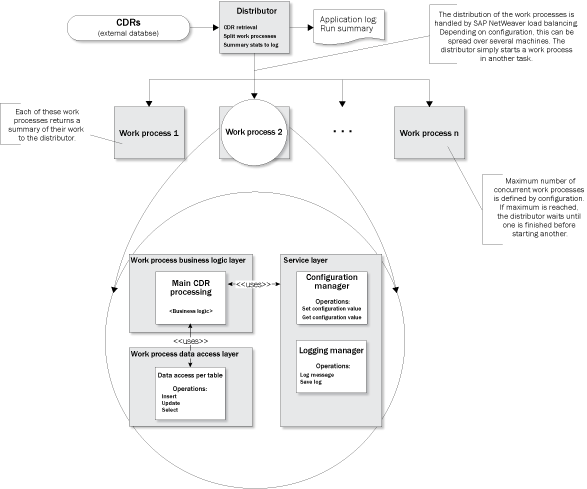
Figure 4
Overview diagram of the distributor and business logic components
Distributor
The distributor is at the core of the parallel mediation process. The three cornerstones of high availability, data integrity, and good system throughput were integrated into the eventual design. The process is designed to have a single version of the distributor running at any one time. Each run processes up to a configurable amount of data and then triggers an event to start a new instance of the distributor to run after a configurable time period. For example, it could process three (number of waves) waves of 100,000 (package size) CDR entries every 15 (pause time) minutes. The parameters for package size and number of work processes are also used to ensure that the distributor can complete its work within the configurable time period.
Figure 5 shows the package processing by the distributor.
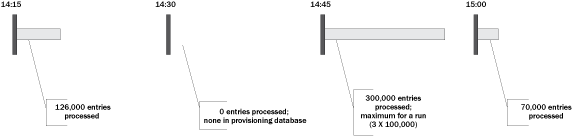
Figure 5
Package processing by the distributor
Data is processed in packages and only removed from the provisioning database after successful processing. An alert is triggered if any anomaly is found (e.g., can’t read from the database or more than configurable number of runs with no data). The distributor also reprocesses data that was in error but has since been corrected through the error correction UI (see the “Error Correction” section below). All data is read using data access objects from the data access layer.
The basic sequence of events is:
- Retrieve all data from the error CDR table that has been readied for reprocessing
- Divide into logical groupings of CDR entries (same processing segment)
- Start a work process with as many groupings as the configuration allows. For example, if the work process size is 2000, the number of CDR entries can be anywhere from one to slightly more than 2000). The work process is started in a separate task and can be on another server. The distributor keeps track of how many work processes are running by using end-of-task processing. If the number of work processes running is equal to the maximum allowed by configuration, the distributor waits until a work process is completed before starting another.
- Wait until all error reprocessing work processes are completed
- Do these steps until either there are no more CDRs in the provisioning database or the maximum number of waves (reads from database) is reached based on the configuration parameter
- Retrieve up to <package size> CDR entries from the provisioning database
- Divide into logical groupings of CDR entries (same processing segment)
- Start a work process with as many groupings as configuration allows. (This is the same process as number 3 for error reprocessing, above.)
- Wait until all work processes are completed
- Summarize results and write totals to the application log and control table
- Start the next iteration of the distributor by raising an event (FM BP_EVENT_RAISE)
Business Logic Layer
The business logic layer contains all logic for the validation of CDR entries, the update of the various mediation engine tables, and the deletion of processed CDR data from the provisioning database. Actual business logic differs between implementations and is therefore compartmentalized into its own class. The business logic work process framework calls a main method in this class that calls all other methods. You can adapt these methods to the requirements of any new implementation. The entire class is kept separate from the data access layer, which is called for all database functions.
Master Data Replication
The mediation engine requires a good set of master data for implementing the business logic based on customer segment, service product catalog, and material (i.e., service). A CDR contains these information pointers and business logic does not get additional information about this master data during calculations. Since the mediation engine is a mediator to aggregate and process data to be billing compatible, you need a set of master data to be available in the mediation engine. Based on the architecture, the mediation engine has to sit in a separate SAP NetWeaver box for various performance requirements. SAP ECC is the originating system because the sales and distribution (SD) module is part of SAP ECC.
We had several options to replicate master data:
- Connect to SAP ECC using a BAPI and read the information: This option was ruled out because the number of Remote Function Calls (RFCs) made to SAP ECC can hamper the performance and the whole motive of the mediation engine architecture is jeopardized.
- Replicate the skewed view of master data to the mediation engine using batch programs: This option was ruled out because the correctness and accuracy of master data can be challenged if the replication is done periodically.
- Replicate the skewed view of master data to the mediation engine using SAP NetWeaver PI: We went with this approach because the SAP NetWeaver PI replication is almost real time.
We evaluated standard message types versus custom message types, including several variations of custom message types. Standard message types did not meet our requirements, or getting complete information was too cumbersome. We decided on custom message types and created three different types of custom messages to explain if any value is updated or modified in SAP ECC. Appropriate inbound and outbound mapping modules were implemented in SAP ECC and the mediation engine side. The three types of custom messages are:
- Customer segment message type: Basic customer information and sales data set are replicated. The status of the customer if the customer is marked as retired or not is also implemented. This information is key for business logic and certain rules in the logic.
- Material master message type: This is a lean message type, which includes basic information such as the marginal group and the service family to which a particular service product belongs.
- Catalog message type: This message type covers the product information and the list of products a particular customer or customer segment can buy from the service provider. This also covers the pricing deals for the combination and the validity dates. This information is needed for calculating the aggregation.
Aggregation Process
SAP CC needs the aggregated values for several criteria so that it can rate or charge these values. The aggregation involves the following steps:
- Calculating the number of billable days, fiscal billable days, active count, unique count at service, service group, and invoice group level per segment, and saving them in the database table
- Communicating the aggregated data to SAP CC by making an RFC
- Receiving the rated data from SAP CC and saving it in the database
Aggregation occurs at various times to ensure that summaries exist at various levels and for different time segments (e.g., fiscal and bill months). Whenever required, the process reads detailed billing data, calculates counts (e.g., billable days, fiscal billable days, active count, and unique count) by segment, and saves the data into summary tables. The summarized data is then sent to SAP CC through an RFC, in which it is processed and returned with rating data. The rating data is then saved to the summary tables. The aggregation process then calls the next step in the billing process. If an error occurs in the process, a system alert is triggered.
Error Correction
During business logic processing, there can be situations in which you cannot continue with a given CDR entry. For example, you may have no record of a billing ID, yet receive a deactivate CDR entry. This entry is written to an error CDR table along with appropriate messages. If the error is at the billing ID level like this one, an entry is added to an exclusion table so you do not process any more entries for the billing ID until all errors are corrected. There is also an exclusion table for the segment level, excluding all CDR entries for the segment in the case of an error at that level (e.g., the carrier is not in master data, or the region is invalid). In any event, all error CDR entries are written to the error CDR table.
The mediation engine provides an error correction UI to business users for analyzing and correcting error CDR entries. This is a Web Dynpro ABAP component that allows flexible lookup, individual error correction, and mass update of errors. You can also ignore errors. Users can enter any combination of fields to select the errors in which they are interested. All fields carry F4 help and allow ranges and multiple selections. The business user can correct any and all errors so processing for the billing or segment can continue. When entries are corrected, the exclusion tables for the billing ID and segment are updated accordingly. When there are no more errors for a billing ID, the CDR entries are marked as ready for processing and the entry in the billing ID exclusion table is removed. This allows the distributor to reprocess the corrected CDR entries. The same is true for the segments: When there are no more errors for the segment, the entry in the segment exclusion table is removed.
System Alerts
System alerts are raised whenever an extraordinary error occurs in the system that leads to an exit of the program logic. The SAP standard CCMS alert mechanism is used from all areas of mediation, with subcategories by major process (e.g., distributor).
Application Log
The distributor, business logic work processes, aggregation, master data replication, and error correction UI all use SAP application logs for recording regular processing, as well as for listing errors and warnings. This can be used to monitor performance and check for any anomalous processing. It is used in conjunction with CCMS system alerts to pinpoint problems. The standard function module APPL_LOG_DISPLAY is used to display the application log.
Configuration Parameters
The design of the mediation engine allows custom tailoring to adjust the performance to fit the existing system volumes and hardware profile of the installation. This allows for scalability for an implemented system as well as the flexibility to satisfy both large and small companies. The main performance parameters are:
- Maximum number of waves for a distributor run
- Package size of the database read from the provisioning database (per wave)
- Start-to-end elapsed time for the next distributor run (basically, run every n seconds)
- Maximum number of concurrent work processes
- Package size for each work process (number of CDR entries)
Archiving
For archiving tables, SAP Archive Development Kit (ADK) is used. Custom programs were created by the project team using ADK function modules to select, archive, and delete data to maintain reasonably sized tables for the mediation engine. Actual analysis of the data from the mediation engine tables is possible through SAP NetWeaver BW, which copies new data on a nightly schedule.
Tracing
The mediation engine runtime supports tracing. The tracing is by default turned off. You can activate tracing any time provided the initial configuration is complete. This ability to trace what is happening within the system can be invaluable when a problem is encountered. Both the distributor and business logic components log all steps during their processing. This can result in huge trace files being produced so we recommend the trace be used for problem-solving situations only.
Performance Measurements and Lessons Learned
Now let’s look at some performance measurements and what we learned in the process of monitoring the performance.
Measurement KPIs
As discussed earlier, the main goal of this solution is to tackle the performance issue and implement the solution that consumes the least resources. We had to define the strategy as to what to measure to identify if the solution we built was on par with the expected behavior. We have identified the KPIs that need to be measured as throughput and resource consumption.
Measurement Tools
SAP offers a lot of tools to measure performance. It is important to know which tool to use to get the desired snapshot of the system at runtime. Since our focus was to determine the throughput sizing, we decided to use the SAP standard transaction code STAD (statistical records monitor). The SAP kernel gathers statistical records of all the dialog steps carried out by the applications in the SAP system. Every dialog step in the system is recorded along with information such as user name, response time, CPU time, and database time. These records are created by the work process of an SAP NetWeaver application server ABAP and provide an overview of the performance of the system.
You can run the mediation engine with several variants. As you can see from the features of the mediation engine in the previous sections, you can specify the package size of each work process and the number of work processes the engine can run in parallel. The package size of the work process represents the number of CDRs each work process should process. We performed our lab tests with these two parameters. We also considered database size as one of the parameters that can have an influence on the throughput of the solution.
Simulated Data for Measurements and Results
We have developed a simulator that generates a high volume of CDRs. We developed this tool to simulate the real-life scenario in which the database table size and volume of the CDRs that needs to be processed can be increased sequentially. We took the internal SAP NetWeaver system that has the following system capacity:
- Database and SAP NetWeaver Central Instance (SAP NetWeaver CI) server hardware: HP BL 495C Dual Quad Core 2.3 GHZ AMD Opteron 2356 processor, 128 GB memory (physical servers)
- SAP NetWeaver application servers (AS) ABAP 1 and 2: These are virtual machines having 4 CPUs and 24 GB of memory
- Database, SAP NetWeaver CI, SAP NetWeaver AS ABAP 1, and SAP NetWeaver AS ABAP 2 OS: SLES 11
- Database version: Oracle database 11g Enterprise Edition Release 11.2.0.1.0, 64-bit
- SAP NetWeaver setup: Database on physical, SAP NetWeaver CI on separate physical, and two virtual instances for the application servers (Database + SAP NetWeaver CI + SAP NetWeaver AS ABAP 1 + SAP NetWeaver AS ABAP 2)
- SAP NetWeaver version: SAP NetWeaver 7.0 with enhancement package 2
We conducted experiments while varying the table size in the magnitude of 20,000,000 records by keeping the number of work processes and package size. Our lab results showed that when the table size increased by 10 times the throughput was reduced by three times. At 105,000,000 records in the database, the system showed a throughput of 228 CDRs per second. Based on this result, it was decided that we need not go with database partitioning.
Figure 6 shows the number of CDRs processed per second.
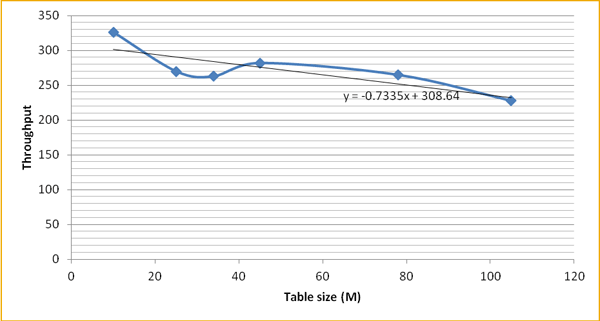
Figure 6
Number of CDRs processed per second
We also conducted the measurements by varying the package size and keeping the number of work processes and database table size relatively similar. The optimal value started from a package size of 200,000 for each work process.
Figure 7 shows the impact of the package size on the throughput.
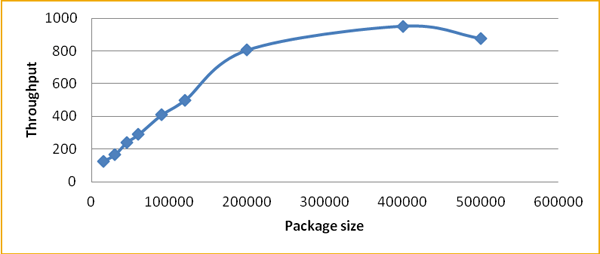
Figure 7
Impact of the package size on the throughput
On the other hand, when we altered the number of work processes by keeping the package size constant and the table size relatively constant, the results were very interesting. When the size is low and the number of work processes is higher, due to the fact that more work processes are used, the performance is better. When the size is too low, the RFC initialization affects the performance badly.
Figure 8 shows the impact of the work package size on the throughput.
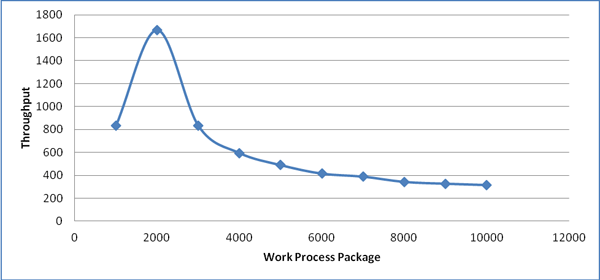
Figure 8
Impact of the work package size on the throughput
Inference from Experiments
All the experiments we conducted were in a specific environment and it should be a good practice to do the same in a to-be production environment. We can infer that package size and number of work processes has to be optimal when the table sizes can grow beyond 100,000,000 records. There is no hard-and-fast rule in deducing these optimal numbers. These experiments have to be done in an environment similar to the production system.
Note
Should your company use the in-memory database SAP HANA, you would find improved performance within the proposed architecture.
Abdelmorhit El Rhazi
Abdelmorhit El Rhazi, Ph.D is a principal solution architect with the SAP customer development group at SAP Labs Canada.
You may contact the author at
abdelmorhit.el.rhazi@sap.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.
Martin Donovan
Martin Donovan is a principal solution architect with the SAP customer development group at SAP Labs Canada.
You may contact the author at
martin.donovan@sap.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.
Narendar Akula
Narendar Akula is a principal solution architect with the SAP customer development group at SAP Labs Canada.
You may contact the author at
n.akula@sap.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.