In this exclusive special report, get an in-depth, step-by-step look at the aspects of implementing BI solutions on SAP HANA. Gain insight into how ETL integrates with SAP HANA and how SAP BusinessObjects BI 4.0 analyzes and visualizes the data stored in SAP HANA.
Key Concept
SAP HANA modeling is a process whereby a developer converts raw columnar tables into business-centric logical views, such as dimensions and measures. The result lets business consumers find their data elements, group by business elements, and filter and sort data. There are seven components behind SAP HANA modeling, each with its own function.
When you take a moment to think back to all the technical innovations that have occurred during the last 30 years, several thoughts come to mind. There was the invention of the Nintendo game console. In today’s standards, it is not a technical wonder but it did lead to the birth of a new market that paved the way for all the amazing game consoles and personal gaming devices that exist today. There was the invention of the Internet, which helped to essentially change the way we humans shop, communicate, share information, and collaborate. There was the invention of the smartphone, a device that put the power of the Internet in the palm of our hand in virtually every city in the world.
Just imagine for a second what life would be like if companies such as AOL, Apple, and Nintendo lacked the ability to develop these products and bring these technical wonders to market. Technical innovation is something that we have all come to expect, but how does one recognize when innovation will lead to fundamental change?
For those of us that have been working in the business intelligence (BI) arena for the past decade, the limitations of interacting with large quantities of data at speeds that were acceptable to business users has been a real challenge. The relational database technologies that had been a core component of our strategies were reaching a point of diminishing return. No real innovation was being introduced by the main database vendors— or at least innovation that offered major performance change. In large part, that was due to their need to support legacy solutions while attempting to provide perceived enhancements. Their strategy for innovation was slow and continually centered around the use of inefficient and increasingly expensive magnetic storage arrays.
In the meantime, SAP was struggling to find a solution to help its customers solve the ever decreasing performance issues associated with managing large volumes of SAP application data. In 2008, SAP began working on a pilot project to prove that the basic mechanisms and processes of a database could be re-developed, leveraging RAM and multi-core CPUs in a way that would revolutionize the capabilities of BI, analytics, and complex data processing. Based on first impressions and more than a year of experience working with SAP HANA, we believe SAP has developed an innovative data platform that will lead to revolutionary changes in BI and beyond.
SAP HANA is a merger of software, hardware, and creative ideas that afforded SAP the opportunity to rethink the database platform. Because SAP had the opportunity to develop this technology from the ground up, without the constraints of the legacy relational database management system (RDBMS) vendors, innovation was an inevitable result of its efforts. Hardware had evolved to a state where RAM could be addressed in terabytes and CPU cores could be numbered in the hundreds, all within a single blade chaise or server rack. When you combine this with SAP HANA’s ability to compress data in-memory, organizations had a viable solution for managing 40 to 120 terabytes of data on a platform that could produce query results so quickly that many questioned if what they were seeing was a hoax.
Will SAP HANA lead to fundamental change? In some regards we are already seeing other database vendors update their solutions to be more like SAP HANA. For organizations that have already adopted SAP HANA, there is no question that it has changed the capabilities of analytics and data processing. Only time will be the true judge of SAP HANA, but all indications are that SAP has developed a solution that will lead BI into the next generation.
When organizations look to develop solutions on SAP HANA, there are three ways you can categorize the available solutions:
- The first way that organizations can use SAP HANA, while leveraging their investments in traditional SAP BI solutions, involves moving their BW environment, based on a legacy database, to SAP NetWeaver BW powered by SAP HANA.
- The second broad category of solutions can be characterized as rapid solutions based on a specific industry, business process, or line of business.
- The final category and the main focus of this report pertains to the ways organizations can use the SAP HANA database by moving data from multiple sources, in either batch or real time, into the SAP HANA in-memory database. In general terms, we label this final solution SAP HANA standalone.
For organizations that have years of experience and knowledge invested in the SAP NetWeaver BW platform, SAP NetWeaver BW powered by SAP HANA will prove to be the most straightforward and cost-effective SAP HANA-based solution available. Organizations will experience very few process or procedure changes with this solution. This is due to the fact that primarily only the underlying relational database that powers SAP NetWeaver BW 7.3 will change.
However, there are specific optimizations whereby DataStore objects (DSOs) and InfoCubes can be converted to in-memory optimized versions. Under the covers, there are also several optimizations within the code that effectively push down processes that were previously handled at the application layer to the SAP HANA database. The net result is a substantial reduction in database storage requirements and query response times.
The SAP Web site (
https://www.sap.com/solutions/technology/in-memory-computing-platform/hana/overview/index.epx) has a long list of prebuilt or rapid accelerated solutions designed specifically to use SAP HANA. Each solution is tailored for a specific business process or line of business or industry. The list includes, but is not limited to, SAP CO-PA Accelerator, SAP Finance and Controlling Accelerator, SAP Smart Meter Analytics, and SAP Sales Pipeline Analysis. As of October 2012, you can find just over 20 solutions available, but you should expect to see the list grow as SAP and its partners find innovative ways to use SAP HANA.
The final category of solutions centers on SAP HANA standalone in-memory database. Those that have blazed the trail with traditional Enterprise Information Management (EIM) solutions will find the most comfort with this category. The solution includes the use of SAP BusinessObjects 4.0, SAP Data Services 4.0, and SAP HANA.
SAP Data Services 4.0 provides all the features needed to support enterprise level data management. SAP Data Services is a proven tool for managing all aspects of EIM. It is used by thousands of companies to extract, cleanse, translate, model, and load data into data warehouses and data marts. With the release of version 4.x, it is tightly integrated with SAP HANA while maintaining support for almost every popular legacy RDBMS and business application on the market. In short, it is an excellent tool for extracting data from both SAP and non-SAP based sources. SAP HANA will serve as the engine for storing, aggregating, calculating, filtering, and forecasting the data loaded into its columnar or row store in-memory tables. BusinessObjects 4.0 provides the tools needed to analyze and visualize the data stored in SAP HANA. It includes a Swiss army knife of tools that all have well defined mechanisms to connect to the data on SAP HANA.
As you continue to read this special report, we will walk you through all the aspects of implementing BI solutions on SAP HANA standalone using SAP Data Services to manage and load data, SAP Information Steward to profile and research data issues, SAP HANA to develop and manage multi-dimensional models, and the SAP BusinessObjects suite of tools to create mobile analytics, reports, and dashboards.
For those reading this special report with little or no experience using SAP BusinessObjects or SAP Data Services, we hope to provide insight into how companies and Decision First Technologies have implemented successful solutions for over a decade using SAP BusinessObjects EIM and analytic best practices. For those looking to find more information on creating multi-dimensional models in SAP HANA, this special report will also provide you with valuable insight into that world.
Managing SAP HANA with a Proper Data Model
SAP HANA provides such a powerful in-memory data platform that much more information is available at speeds never seen before. This is why managing information appropriately is more important than ever before. SAP HANA in a standalone configuration is truly a blank slate. There are no tables, no models, no views, and no data. You must not only get your data into SAP HANA but also plan and design the structures and strategy to house your data. In this portion of the special report, we focus on managing data effectively using proper data modeling techniques, profiling and examining data with SAP Information Steward, and finally loading data into SAP HANA using SAP Data Services.
Start with a Good Data Model for SAP HANA
Data modeling in SAP HANA is quite similar to traditional data modeling with some subtle differences. Data must be modeled into efficient structures that take full advantage of SAP HANA’s in-memory structure and analytic modeling capabilities before presenting the data to reporting tools such as SAP BI BusinessObjects 4.0. In certain cases this deviates from traditional data modeling techniques.
Traditionally, star schemas have been used as the backbone of BI design, and this approach also works well as a baseline data model for SAP HANA. With a traditional RDBMS, your data is modeled into a star schema consisting of fact tables with measures and dimension tables with attributes to describe the data. Notice in
Figure 1 that the Fact_Sales table has measures of units sold with foreign keys to the dimension tables: Dim_Date, Dim_Product, and Dim_Store. Data structured in this manner performs quickly and efficiently when joined in queries and presented to reporting tools.

Figure 1
Typical star schema example with one fact table and multiple dimensions
This is certainly a good starting structure for an SAP HANA data model, with a couple of exceptions. SAP HANA stores data either in rows or in a columnar format, so this degree of normalization is not always necessary or even beneficial for certain types of queries. Both in our lab at Decision First Technologies or at clients, we have seen better performance in some situations with SAP HANA by denormalizing or “flattening” data in certain fact tables when this flattened data is stored in column store tables.
When data is stored in a columnar table, the repeating data has a greater likelihood to be only stored once using run-length encoding. With this method, the values are sorted and the repeating values have a greater likelihood of being sorted together as run-length encoding counts the number of consecutive column elements with the same values. If the values are the same values, only one instance is stored.
This is achieved by actually storing column data using two columns: one for the values as they appear in the table and another for a count of the use of those values. This encoding method yields good compression and the query response times are often better querying this type of structure with repeating data stored in a columnar table over data stored in relational row tables. For example, in our tests both on client sites and in the Decision First lab, we have seen anywhere from six times to 16 times compression over traditional RDBMS structures, and the performance has been no less than incredible.
Another reason to stray from the traditional normalized approach over star schemas in SAP HANA for BI applications is due to join cost. Specifically, the join cost of including range-based operations from the two relational tables in the row engine is expensive due to the intermediate data being transferred from a columnar engine to a row engine. These types of analysis are not available in the columnar engine, so they must occur in the row engine. You then get a performance cost for joining the data that is referred to as join cost.
This repositioning of data at query runtime from the columnar engine to the row engine makes these types of operations much more costly from a performance standpoint. Take the star schema example in
Figure 1. This is optimized for RDBMS structures, which work fine in SAP HANA. However, the cost in performance of joining the two tables DIM_Date and Fact_Sales when running the following query is much greater when the heavy lifting is not performed by the column engine.
These are the kinds of decisions you must consider when modeling data for storage in SAP HANA. In some cases it makes sense to move from a traditional star schema modeling technique toward columnar modeling by using columnar functions available in SAP HANA. Take the example in
Figure 2 showing a typical star schema join between a sales fact table and a date dimension table.

Figure 2
Typical star schema join on sales and date
If the query were revised to use the SAP HANA EXTRACT function as shown in
Figure 3, which is natively supported in the columnar engine in SAP HANA, you could avoid the join cost altogether by using a lightning fast EXTRACT function to derive the necessary date values in real time rather than joining.
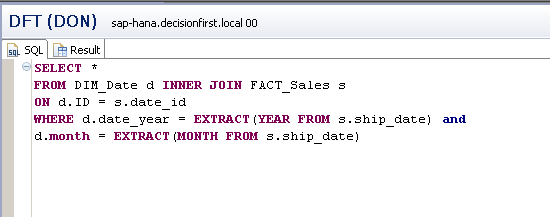
Figure 3
Using the columnar engine function EXTRACT to increase sales and date join performance
The query results come faster by eliminating a whole transfer step, with the processing occurring at the more efficient column engine in-memory using a built-in native SAP HANA function. This type of thinking is what fosters a discussion and a change in modeling data. This leads to the final topic to consider when modeling your data in SAP HANA: Cardinality.
Simply put, cardinality refers to the uniqueness of data in a column or attribute of a table. There are three types of cardinality: high, normal, and low. Most columns that have high cardinality are unique in their content. For example, IDs are primary keys that are unique and have high cardinality. However, state values repeat in an address table (
Figure 4).

Figure 4
Examples of high, normal, and low data cardinality
All new records in the Address table receive a new AddressID. This makes AddressID completely unique. Low cardinality is essentially the opposite and this refers to columns containing values that almost completely repeat. State data provides good examples of low cardinality, and are typically carved off, or normalized, into separate tables as the foreign key column StateProvinceID in the Address table shows in
Figure 4. Normal cardinality refers to columns with values that are somewhat uncommon. Take shipping address values that relate to SalesOrderHeader records. Sales orders will most likely be shipped multiple times to the same address for the same customers, so there will likely be some repetition of these values in the SalesOrderHeader table.
This is why in a traditional data model, the structure looks as it does in
Figure 4. The address records would exist in a normalized structure with an Address table with a foreign key to SalesOrderHeader. Both low and normal cardinality conform to this modeling technique for traditional RDBMS databases, but this is entirely the wrong approach for loading data into SAP HANA.
Again, you must consider the join cost of reassembling the information at query runtime versus a more natural structure for a columnar engine. A more efficient data model for SAP HANA is shown in
Figure 5. It merges
both Address and State information with SalesOrderHeader and with SalesOrderDetail data to create one table in SAP HANA.
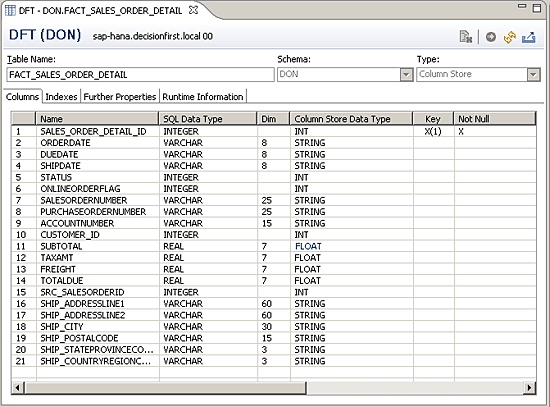
Figure 5
A merged sales table containing both address and state data in SAP HANA
One thing to notice in
Figure 5, aside from the denormalized data, is the use of float Column Store Data Type for all the amount fields. Normally, decimal data types would be used for their precision, but float data types accommodate a behavior that is unique to SAP HANA. SAP HANA requires the data type of the base column values to be able to cover or support the maximum value in size and precision of the data as it is rendered in aggregate operations.
This is especially important as the values of the datasets grow in size. For example a decimal (19, 4) data type at the individual record level in a table is fine, but as the aggregation of a recordset grows, the growth produces overflow errors that a decimal (19, 4) does not cover. So, you guard against this unique behavior by using floats for commonly calculated values, such as amount fields in base tables.
This fact table is a poor choice for a traditional data model, as a traditional approach dictates multiple structures, and the join cost in a traditional RDBMS is helped greatly by providing indexes at all join points. However, in SAP HANA, the compression achieved by the column storage structure as described before performs better than taking the time to join the separate tables in the row engine. The compression achieved by a Column Store table negates the gains of a traditional normalized structure.
We have discussed numerous examples of ways to model data and are almost ready to load the data and create these structures in SAP HANA using SAP Data Services 4.0. However, by not profiling the source data first, you may miss aspects of the data that could compromise the quality of your data. The last thing that you want in SAP HANA is really fast bad data, so you can ensure quality with data profiling in SAP Information Steward’s Data Insight.
Profiling Data with SAP Information Steward’s Data Insight
SAP Information Steward’s Data Insight is a tool for quickly ascertaining a grand amount of information from both data source tables and target tables. There are many profiling capabilities including columns, addresses, dependency, redundancy, and uniqueness. Data Insight also has the capability to measure and record data quality over time by creating scorecards that are fully configurable to measure quality aspects that are important to each individual company’s business. It is important to note that Data Insight is only one application in SAP Information Steward. For the scope of this special report, we limit our focus to the profiling capabilities of Data Insight.
Upon logging into SAP Information Steward, you land at the main application screen with the Data Insight application tab in focus, as seen in
Figure 6. For the purpose of this special report, we have created both a project called HANA_Source and a connection to the source SQL Server database within this project.

Figure 6
Data Insight application on SAP Information Steward’s main screen
With regards to profile tables in this project, you click the project to launch the Workspace home screen, which is where you set up and run the profiling tasks against the tables. In our example stated earlier for SAP HANA, we are loading both customer and address data with our sales data, so we need to take care and ensure that addresses are good, verified United States Postal Services (USPS) addresses and that customer and address data all have good quality before loading it into SAP HANA.
To set up the column profile task, select the tables Address and Contact in the Workspace Home application tab. Select Columns for the profiling task from the pull-down menu as shown in
Figure 7. After clicking Columns, you are prompted to click Save and Run Now. This executes the profiling job on the SAP Information Steward server, and the profile job runs the profile against the database tables. This is really all that you need to do to engage a column profile task.

Figure 7
Select the tables to profile in the Workspace Home and Columns from the pull-down menu
This takes care of column profiling, so now we now turn our focus to address data. SAP Information Steward has the unique capability to run address profiling tasks using USPS validated directories. It gives you information about your address data quickly with just a few clicks and field settings. You can determine if an address in a record is a valid, deliverable address, if an address in a record is correctable using the Data Quality Management transforms in SAP Data Services, or if an address in a record is invalid and uncorrectable. A correctable address means that according to the profile result, SAP Data Services has enough information available in the input record to a data quality job to adequately fix the address to ensure that it is deliverable by the USPS. All this is done with no coding using SAP Information Steward. Before this tool, that task was impossible.
To perform the address profile, select the Address table and Addresses from the Profile pull-down menu as represented in
Figure 7. This launches the Define Addresses Task window as shown in
Figure 8. Using this screen, you assign or map the fields from your database table that correspond to the field mappings shown in the Define Address Task screen. In our example table for the Address1 field in SAP Information Steward, we have an AddressLine1 field. For Address2 we have AddressLine2 in the database. Locality1-3 in SAP Information Steward refers to the city information and Region refers to state information, so those map to City and PostalCode fields, respectively. PostalCode is the Zip code field and a PostalCode field maps to this information. Upon filling out this form, you again click the Save and Run Now button to submit the address profiling task.

Figure 8
Map address attributes and click Save and Run Now
After the tasks finish in Information Steward, you have a lot of information about your source tables for the Data Services job. It helps fix data quality issues in your code before the data is presented to the data model that you have set out to establish in SAP HANA. Let’s consider the results of the column profile in
Figure 9.

Figure 9
Results of the Data Insight Column Profile task
You can see from the results of this column profile task in
Figure 9 that you have some work to do on the data before loading it into SAP HANA. There are some issues with names. It appears that some have been entered in upper case as indicated in the Value column by Xxxxxx and some in lower case as indicated in the Value column as xxxxx – for example, the record of gomez. You need to standardize all of the names on proper or mixed case as well as run them through data cleansing transforms before loading them into SAP HANA.
Looking at the address profile results in
Figure 10 it appears that you should cleanse the addresses as there are quite a few correctable addresses that the Address_Cleanse transforms in SAP Data Services can fix. These are valuable repairs before you load the data for further presentation in SAP HANA. You are now ready to begin building your code in SAP Data Services to both build tables and load data into the model you’ve designed in SAP HANA.

Figure 10
Results of the Data Insight Address Profile task
Loading Data into SAP HANA using SAP Data Services 4.0
After seeing the trouble that can arise from faulty addresses and faulty names, you are ready to craft both the FACT_Sales_Order_Detail table structure that was presented in the data modeling section of the special report in
Figure 5 and to load data into that structure. SAP Data Services is the only certified solution to load third-party data into SAP HANA, and this is our vehicle for data loads. You can quickly create both row- and column-based tables in SAP HANA, thus both building and loading the model laid out in the examples above. To accomplish this, you first need to create Datastore connections to the source SQL Server database and the target SAP HANA system.
Open the SAP Data Services Designer and browse to the Datastores tab in the Local Object Library on the bottom left portion of the screen. Right-click the white space to bring up the pop-up menu shown in
Figure 11. Click New on the pop-up menu to launch the Create New Datastore configuration screen.

Figure 11
Click New to create Datastore connections to both the SQL Server source and SAP HANA target
In the Create New Datastore screen, you specify the settings as shown in
Figure 12. Notice the ODBC Admin button on the screen. You need to create an ODBC connection to SAP HANA if you have not done so already. This is a standard ODBC connection just like any other data source using Windows Data Sources (ODBC) in the control panel in Windows. The only thing slightly different is that you use the SAP HANA ODBC driver shipped with SAP HANA over a standard, Windows-supplied ODBC generic driver. This is similar to using an IBM ODBC driver to set up an IBM DB2 connection much like other databases that are supported in SAP Data Services as ODBC connections. The SAP HANA ODBC driver is installed on the machine hosting the SAP Data Services job server.

Figure 12
Specifying new Datastore connection settings
You now have your Datastores created and have established connections to the Microsoft SQL Server source database and the SAP HANA target system. All the components in SAP Data Services are ready to create the data flows necessary to build the FACT_SALES_ORDER_DETAIL table in SAP HANA.
However, it would not be wise to go directly from the source to the structure laid out in the data modeling section of this special report. What if you choose to include other data sources in your well-modeled Sales Order Header fact table in the future? By going straight from the source to SAP HANA, you are to use the primary key from the source table as well as just taking the fields as they are in the source. Usually, this is not desired in a reporting data structure.
Dimensionally modeled star schema data marts or data warehouses should be divorced from the source and contain source-agnostic columns that represent business definitions and have source-agnostic primary and foreign key structures. The way to achieve a divorced storage structure is to use a staging database and create a surrogate (source-agnostic) primary key with a link back to the source primary key. To do this, you model a staging layer in SQL Server into your Data Services process before moving data or creating structures in SAP HANA. Follow these steps to model a staging layer.
Step 1. Create Staging with Surrogate Keys
Staging serves two functions in your load to SAP HANA. First, it divorces the source-primary key structure with the keys that you create while loading to SAP HANA. This allows you to easily integrate other data sources in the future.
The second function of staging is to do all the manipulation or transformation of the data necessary to deal with the issues that were found earlier in profiling using SAP Information Steward. To do this, you use SAP Data Services to create a table called SALES_ORDER_DETAIL_STAGE. It has flattened or denormalized data from the following tables in your source database: SalesOrderHeader, Address, StateProvince, and SalesOrderHeader. The data in these tables will be merged into the target table to take advantage of the unique columnar engine properties of SAP HANA. This type of data structure performs better and serves as a proper foundation to properly exploit the analytic modeling capabilities of SAP HANA. The fully realized data flow is depicted in
Figure 13.
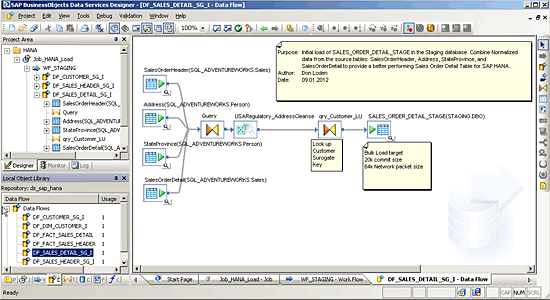
Figure 13
Create a SALES_ORDER_DETAIL_STAGE staging table
What’s inside the data flow components? The first thing that the data flow does is to join four disparate tables from the source database in the query transform labeled Query in
Figure 13. You can see in
Figure 14 how the joins are accomplished in SAP Data Services in the FROM tab of the query transform.
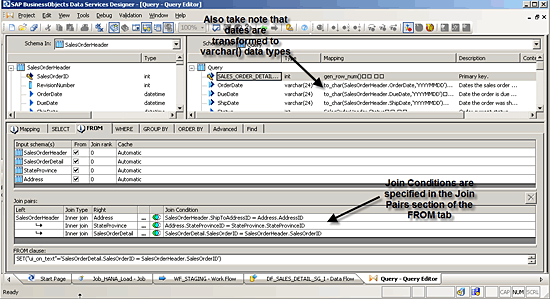
Figure 14
Join all tables together in the query transform of the data flow DF_SALES_DETAIL_SG_I
Take note in
Figure 14 that the native date fields from the source will be transformed in these data flows to varchar() fields and the format of the field should be YYYYMMDD. This means a date field in the OrderDate source table would look like 09/01/2012 11:59:59, but in the staging table or in SAP HANA, you want the date field to look like 20120901. The reason for this is that an SAP system contains sophisticated built-in date handling functionality that we explore in the next section (analytic modeling) of this special report. This varchar() format is what is required to take advantage of that functionality.
One last thing that is happening in the query transform in
Figure 14 is that the first field, SALES_ORDER DETAIL_ID, has a gen_row_num() function in the Mapping column of the query transform. This is the surrogate key as the gen_row_num() function generates a row number for each record. The source table key SalesOrderID will also be mapped to the target table so this staging table, SALES_ORDER_DETAIL_STAGE, will contain both the surrogate key as well as the source primary key. This table provides the link of the ultimate fact table in SAP HANA back to the source table.
Eventually, when you wish to add more sources to the fact table in SAP HANA, you just map the attributes appropriately to this staging table and add the new source’s primary key column as a new column in the staging table. The other fields signify the business terms, not a direct link to any source. Take, for example, the OrderDate field. An OrderDate is an abstracted business concept now. It is no longer just a linked field to the source. The OrderDate stands source independent and represents an OrderDate business concept outside of just coming from this source. This concept is agnostic to the source and can be used independently to describe any OrderDate from any source. A new source has a new order date field that is mapped to this OrderDate field in the SALES_ORDER_DETAIL_STAGE table. Therefore, all the other attribute fields, such as OrderDate, are reused with the new source. It is the primary key’s presence, along with the surrogate key, that provides the link back to any source table. This is the primary reason for taking the time to craft a staging layer for your load to SAP HANA.
Another issue that arose in the data profiling is the validity of the addresses. You can use the USARegulatory_AddressCleanse transform in your data flow DF_SALES_DETAIL_SG_I (as shown in
Figure 13) to correct the addresses. The address cleansing transforms are found in the Local Object Library under the Data Quality node as shown in
Figure 15.
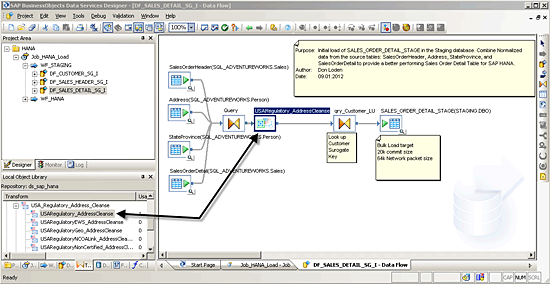
Figure 15
Where to find the USARegulatory_AddressCleanse transform
After placing the USARegulatory_AddressCleanse transform in the data flow, you configure both the input and output fields within the transform. The input fields map to the existing address fields coming from the source tables through the query transform. The address cleanse transform takes these field inputs and analyzes and corrects the physically stored addresses using SAP-supplied postal address directory files updated by the USPS. By using SAP Information Steward to quickly identify the address records to correct, you are able to use the address cleansing capabilities of SAP Data Services to effectively cleanse your records in the staging database.
Now that you have your staging table SALES_ORDER_DETAIL_STAGE correctly populated, this table can link you back to the various sources that will be loaded over time. You are now ready to load the data to SAP HANA.
Step 2. Move Data into SAP HANA and Create All Tables at Runtime in SAP Data Services
You have performed most of the heavy lifting in the staging data movements, and the load to SAP HANA is straightforward. You are essentially going to take your staging tables as a template, use the template table functionality within SAP Data Services to quickly create table structures, and load the data into SAP HANA. Template tables are handy tools. They take any recordset and craft a create table SQL statement against the target database. As soon as you have the structure for the table exactly as you wish, you can select a template table as the target for your data flow, as shown in
Figure 16. The table structure will be created in SAP HANA at data flow runtime. After executing the Job_HANA_Load SAP Data Services job to run your DF_FACT_SALES_DETAIL data flow, you now have your table structure created in SAP HANA.
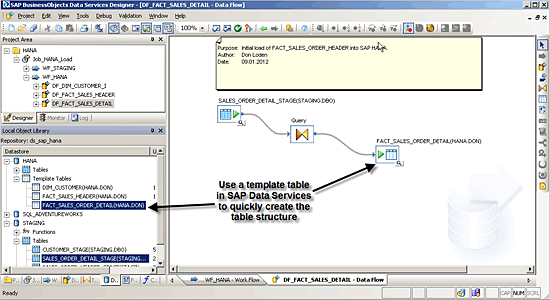
Figure 16
Completed data flow in SAP Data Services to load the sales order detail into SAP HANA
The template table is a great way to quickly create the structure of the table in SAP HANA, but it may not perform as well as bulk loading data using SAP HANA’s bulk loader. This is particularly important if you are loading a large table with millions of records. Smaller tables can stop at this point and use the template table to create the table structure and load the data, but with a larger table, such as FACT_SALES_ORDER_DETAIL, you probably want to explore the bulk loader options available from SAP HANA. To use the bulk loader capabilities within SAP Data Services, import the table into SAP Data Services as a standard table. To do this, right-click the template table in the Local Object Library that was created by running the job and data flow. Then the popup menu in
Figure 17 appears.

Figure 17
Import the table in Data Services to get standard table full functionality
After importing the table, you are free to set commit sizes or use the bulk loader by double-clicking the FACT_SALES_ORDER_DETAIL target table. This brings up the target table editor screen, in which you can specify many things about the load of the large FACT_SALES_ORDER_DETAIL table (
Figure 18). Since you know this table is large, use the Bulk Load Options tab to control the maximum bind array size. Set it to 1,000,000 rows. This is a practical starting value that we have used with good results in our Decision First lab. The maximum bind array value acts like a commit size control in other target databases and batches the records together into larger groups for performance in large loading operations.

Figure 18
Use the target table editor to control the maximum bind array size
After carefully crafting your SAP Data Services job and data flows to load the FACT_SALES_ORDER_DETAIL table in SAP HANA, the only thing left to do is execute the job. Navigate to the Project Area in Designer as shown in the top left of corner of
Figure 15. Right-click the job name, and select Execute Job from the pop-up menu. With data extracted, cleansed, and loaded into a series of SAP HANA columnar tables, you can now begin the process of developing multi-dimensional models or views based on those tables.
SAP HANA Modeling Process
SAP HANA modeling is a process whereby a developer converts the raw columnar tables into business-centric logical views. Much like the process in which a legacy BusinessObjects customer would define a universe based on relation tables, modeling within SAP HANA allows for columns of data to be defined as dimensions and measures. The result presents the data in a format that is more business intuitive, granting consumers an easy catalog to find their data elements, group by business elements, and filter and sort data.
There are seven main components to SAP HANA modeling. Each component has a specific purpose and function. When these components are compiled together, the result provides a meaningful multi-dimensional representation of the data. The main components of modeling are the following:
- SAP HANA Studio
- Schemas
- Packages
- Attribute views
- Analytic views
- Calculation views
- Analytic privileges
Let’s look at each component in more detail.
SAP HANA Studio
SAP HANA Studio (
Figure 19) is a Java-based client tool that allows developers and administrators to create models and manage the SAP HANA RDBMS. It is typically installed on a developer’s desktop and it is the basis for developing rich, multi-dimensional models that are consumed by the various supported SAP BusinessObjects 4.0 reporting tools. It also contains a subset of tools for the SAP HANA database administrator (DBA). Developers use the interface to create packages, attribute views, analytic views, database views, calculation views, and analytic privileges. DBAs use the interface to manage security, roles, backups, tables, and views and to monitor the system.

Figure 19
SAP HANA Studio
Schemas
Schemas (
Figure 20) are directly associated with user accounts created by the SAP HANA DBA and are used to store row and columnar tables. There are also other objects that are stored in an SAP HANA schema, including views and procedures. For each user created by the DBA or default to the system, a schema space exists that must be referenced when working with tables in SAP HANA. The term schema is not unique to SAP HANA. Almost every RDBMS on the market incorporates this term per the schema modification standards set by the American National Standards Institute.
Note
Schemas are secured in SAP HANA, so it is important that the developer’s account and _SYS_BIC (system account for managing SAP HANA models) have been granted the SELECT rights before models can be developed or activated in SAP HANA Studio.
Figure 20
Schemas
When you create a table using SQL syntax in the SAP HANA Studio, you must reference the schema in the CREATE TABLE and DROP TABLE commands. The syntax of every table-related function always references the schema name (
Figure 21).
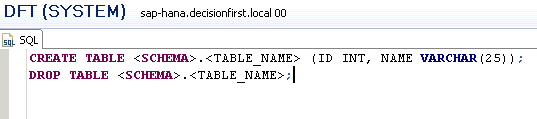
Figure 21
CREATE TABLE and DROP TABLE commands
Packages
Packages are the first logic storage component of an SAP HANA model. Within a package you define one or more attribute views, analytic views, calculation views, or analytic privileges. Packages can be created in a hierarchical order for the purposes of security and logic ordering of components (
Figure 22).

Figure 22
Package hierarchies
When you create your first package, you can give it a name, such as Sales. Subsequent packages can be created using the <Parent_Package>.<Sub_Packages> naming convention. In
Figure 23, we created a sub package named northamerica. Because we wanted this package to exist under the sales package, we named it sales.northamerica. The dot or period in the name indicates that the package should be created as a child to the parent package sales. Creating a hierarchical package structure is important for both organization of modeling objects and for securing objects within packages.

Figure 23
Creating a package
Attribute Views
Attribute views are the logical dimension and hierarchy containers within an SAP HANA model. SAP HANA Studio allows you to create them by joining and filtering tables found in SAP HANA schemas. Attribute views are not required for an SAP HANA model, but before you can create an analytic view containing hierarchies, you must first create an attribute view. The end result of an attribute view appears to be a single logic table or view of data.
Attribute views allow the developer to denormalize data by joining one or more tables, filtering one or more tables, or by developing calculated attributes. Imagine you are developing a SQL View based on three tables that will result in a record set that contains all the information about customers who placed a sales order. Within this attribute view you likely join tables such as Customer, Address, and Account. You can also filter the Customer table so that only active customer records are returned. The end result is a single, logical view of these tables that returns all the relevant customer information in a single unique row (
Figure 24).
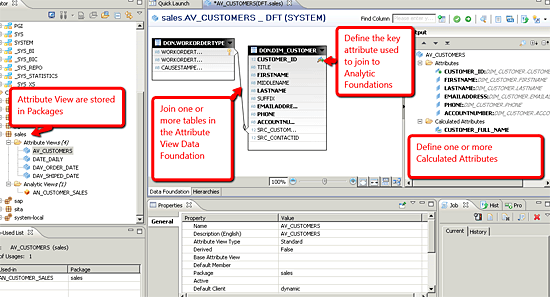
Figure 24
Components of an attribute view
There are two main tabs within the interface that developers use to create an attribute view. The Data Foundation tab is used to define the joins, keys, and filters needed to create a complete attribute view. The Hierarchies tab is used to define hierarchies that are available to some of the SAP BusinessObjects reporting tools.
The Data Foundation tab of the attribute view allows developers to denormalize a data set using joins, filters, and calculated attributes. The joins are defined as inner, left outer, right outer, referential, or text. If the developer right-clicks any column in a data foundation table, the user interface (UI) presents the option to create a filter. A filter at the foundation level is permanently applied to the results sets and should only be used to remove records based on technical or business requirements.
On the right side of the Data Foundation tab are the output columns. These columns are added by right-clicking a column within a table found on the Data Foundation tab. On the right-click menu, there is an option to Add as Attribute. Any value available on the output window is accessible anywhere the completed and activated attribute view is used.
Another option available on the output windows is the derived column. You can derive attribute columns using the calculated attribute option. This useful feature allows developers to derive columns to support various reporting requirements (
Figure 25). For example, you could concatenate the customer’s last and first name separated by a column. You can also use the if() and now() function and CUSTOMER_EFFECTIVE_DATE field to create a calculated column that flags customers that have more than five years of history with your company.
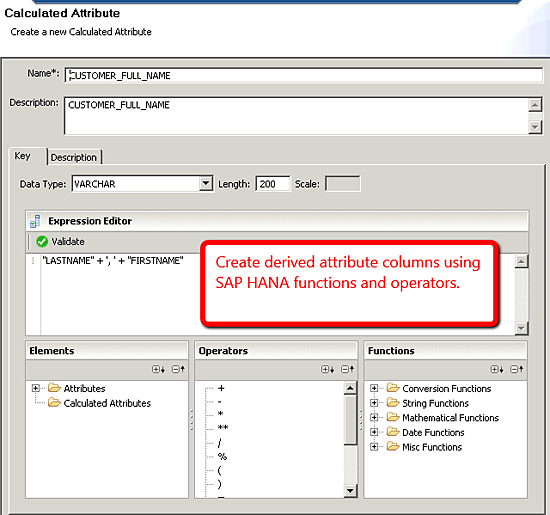
Figure 25
Calculated attribute
When you define an attribute view, you select one or more columns and establish the attribute key (
Figure 26). The attribute key is the basis for joining the attribute to an analytic foundation, which we discuss in more detail later. Developers can find the option to add an attribute key by right-clicking the table in the data foundation and selecting Add as a key attribute. It is important that the values for this column be truly unique in results. In traditional data modeling, developers define a primary key that signifies that all records are unique based on the column or columns defined as a primary. The same is true with an attribute view. When the attributes are joined within an analytic view, each record must be unique to prevent the duplication of records and subsequent over-aggregation of data.

Figure 26
Components of an attribute view
Within an attribute view, developers can create hierarchies that can be directly used by tools, such as SAP BusinessObjects Analysis for Office and BusinessObjects Analysis for OLAP. Developers can find this option by clicking the Hierarchies tab (
Figure 27). In future releases of SAP BusinessObjects 4.0, these hierarchies will also be accessible by SAP BusinessObjects Web Intelligence (also known as WebI) and possibly SAP BusinessObjects Crystal Reports for Enterprise via direct binding to SAP HANA analytic views. Hierarchies add a logic order to data ranging from a narrow to a broad category.

Figure 27
Attribute hierarchies
Hierarchies are useful when reporting needs require expand and collapse functionality for displaying key performance indicators and other measures. In
Figure 28, you can see that the AccountNumber column contains a + sign, which indicates that there are child objects available. In almost every line of business, you will find hierarchies that are useful for analyzing measures or key figures.

Figure 28
SAP BusinessObjects Analysis for OLAP
There are four main options available when creating an attribute view in SAP HANA Studio (
Figure 29):
- The standard attribute view type is just as the name implies. This is the type of attribute view developers choose when creating or deriving attributes based on existing tables stored in SAP HANA.
- Time-based attributes are derived based on pre-loaded date and time tables maintained by the SAP HANA system. When you create a time-based attribute, you have the option to establish the calendar type, variant table, and granularity. Time-based attributes are handy because they eliminate the need for an external tool to load and manage date and time tables.
- Developers use the derived attribute type to create aliases of existing attribute views. They are handy when your analytic foundation contains multiple foreign keys for various dates or times. For example, a typical sales_order_detail table likely contains three columns that represent the order_date, ship_date, and due_date. Each of the three columns contains a unique date that will be joined in that analytic foundation to three different date-based attributes. If you attempt to join all three columns to the same time-based attribute, you create a logic loop. The results of your model then only display transactions in which the order_date, ship_date, and due_date all occur on the same day. To overcome this issue, you must create a derived attribute based on an existing date-based attribute for each expected date key in your analytic foundation. Derived attributes are permanently fixed to their parent attribute. Every change made to the parent automatically is reflected in each child-derived attribute and associated analytic view. Developers find them efficient when an attribute view alias is required.
- The final option when creating an attribute view is the use of the copy from option. This is different from the derived attributes in that a physical copy of an existing attribute view is created. The copy will have no further association with its parent once the copy process is complete. This is typically used when a developer wants to rename an existing attribute view without affecting the overall model.
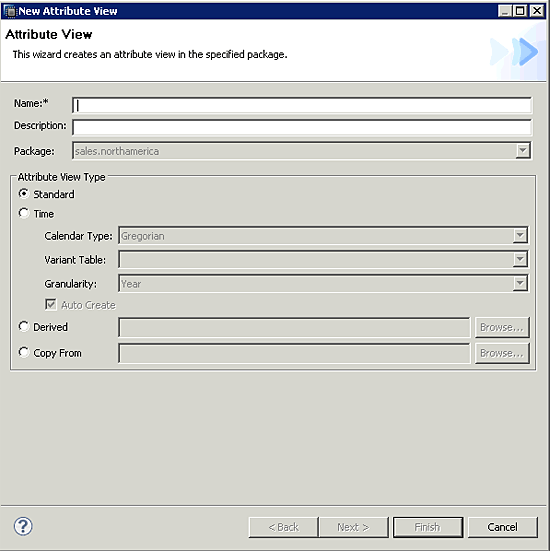
Figure 29
Attribute view options
Regardless of the type of attribute view you select, each attribute view is used within one or more analytic views to complete a multi-dimensional model. Once you have completed the design of your attribute view, click the save and activate icon to commit its definition to the metadata repository of SAP HANA (
Figure 30).
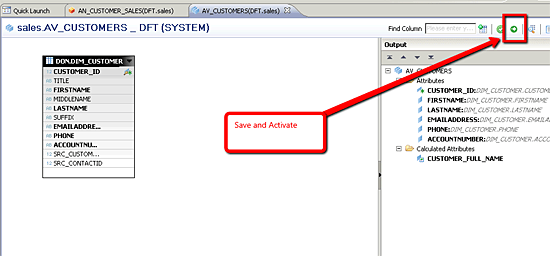
Figure 30
Save and activate your attribute view
Analytic Views
Analytic views are the heart of SAP HANA’s multi-dimensional models. They bring together the attribute view and are the basis for the measures or key figures that make up a multi-dimensional analytic model (
Figure 31). In almost every circumstance, the analytic view is defined using a transactional columnar table. Transactional tables contain each record of activity within a line of business. They can range from sales transactions to a customer’s calls to units shipped.

Figure 31
Adding an attribute view to the data foundation
If you are using SAP Data Services to extract, transform, and load (ETL) data into SAP HANA, and also following standard data modeling approaches, you will use fact tables as your analytic foundation. If you are loading data without using an ETL processes, transaction tables might be more difficult to identify. With almost every transaction table, there is a general set of characteristics that you can use to recognize these types of tables. They typically contain dollar amounts or unit counts that occur over time or over a sequence of events.
In the examples used in this report, the SALES_ORDER_DETAIL table is a perfect example. It contains three distinct dates and four columns that can be used as measures (
Figure 32). Once joined with the attribute views, users can subtotal these amounts over fiscal and calendar dates, months, years, or quarters or by customers, states, regions, or countries.
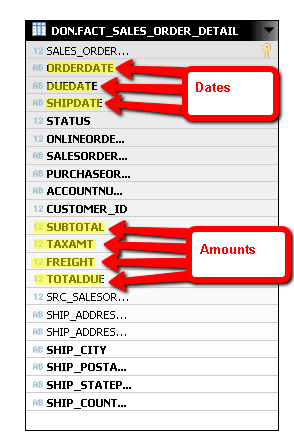
Figure 32
Transaction tables
When creating an analytic view, you must use a new or an existing package for storage and security. You specify the analytic view name and choose from the Create New or Copy From options (
Figure 33). Note that you cannot change the name of an analytic view once it is saved and activated. However, developers can use the Copy From option to create a new version with a different name.

Figure 33
Creating an analytic view
There are two main tabs within an analytic view. The Data Foundation tab is the starting point for designing an analytic view. It contains all the components needed to define the transaction or fact table. The Logic View table is used to define the joins between the data foundation and existing attribute views.
On the right side, developers add one or more tables to the data foundation. Once the tables are added, developers define private attributes and measures by right-clicking each column and selecting the appropriate option (
Figure 34).

Figure 34
Analytic view on the Data Foundation tab
Private attributes are the columns used in joining to existing attribute views or for defining display attributes that do not exist in an attribute view. In most cases they are used to define a join path, but they are present in the output of any model and can be used for filtering, grouping, and sorting within analytic tools once the model is complete. Developers can also define filters that will be applied to any results generated by the final model.
Developers typically filter the analytic view data foundation to eliminate records that should be excluded from any calculation based on the final model. For example, a transaction table might contain multiple order statuses and duplicate measure values for each status. From a business user point of view, only the final or confirmed order status is necessary for reporting. Using an analytic view filter eliminates the status used in the workflow of entering, verifying, and confirming an order and only presents calculations on the records representing the final status of the order.
From a technical perspective, developers need to filter the order status to prevent the model from over-aggregating the results. If an order has three statuses and subsequently three order-detail line records, only one record can be included in the results without triplicating the values of the measure.
It is possible to include more than one table in the analytic view foundation. However, we caution against this approach as it results in significant performance degradation when both tables contain millions of records. In almost all cases, it is better to model the data into a single table using SAP Data Services as data is loaded into SAP HANA. This not only simplifies the SAP HANA modeling tasks but also increases the query response times of any model.
The Data Foundation output includes all the columns that are available for use on the Logical View tab. They consist of Attribute Views, Private Attributes, Calculated Attributes, Measures, Calculated Measures, Restricted Measures, Variables, and Input Parameters. The output columns available in this view can be managed on both the Data Foundation and Logical View tabs (
Figure 35). However, items will not be visible until the joining of the attribute view work has been completed on the Logical View tab (
Figure 34).

Figure 35
Analytic view columns
The attribute view contains all the columns defined within attribute views that are joined to the foundation on the Logical View tab. Until you have added and joined the attribute views to your foundation, this section remains empty.
Private attributes are those that you select in the foundation for joining on the Logical View tab. They represent columns that you can use for the display in the final model or with restricted measures. In any case, unless hidden, these values are available in the final model and appear as though they are standard attribute views.
Calculated attributes allow for the manipulation of any attribute using SAP HANA formulas and functions. In most cases, we recommend that you design calculated attributes in the appropriate attribute view. However, developers may sometimes find it necessary to concatenate, substring, or derive new output columns based on multiple private attributes or attribute view columns within the analytic view.
Generally developers create them in the analytic view because the calculation spans multiple attribute views or private attributes. This is difficult to accomplish in the attribute view because the values might exist in disparate tables in the data model.
Measures are defined by right-clicking columns in the foundation that will be aggregated in the final results of the model. SAP HANA analytic views only support the SUM, MAX, and MIN aggregation functions at this time. To perform more complex aggregations, you need to develop a calculation view, which we discuss later in this report.
Calculated measures are defined in the output section of the analytic view. They represent calculations that involve static values or additional measures. For example, users might want to see the total value of an order less the shipping costs. This can be accomplished in calculated measures simply by subtracting the shipping costs from the sales order total. Developers can also define ratios and percentages at this level, but they must consider the tools used to consume these values as summing a ration or averaging. Average might occur at the reporting tool level.
Restricted measures are a feature of SAP HANA models that allow the developer to define conditional aggregates. When defining restricted measures, the developer selects an existing attribute, defines an operator, and indicates a value to which it must be equal. For example, developers can define a measure that totals sales for 2003 and another that totals sales for 2004. When these values are aggregated and grouped on country, users can see total sales for 2003 and 2004 for each country.
Variables allow the developer to define single value, interval, or range filters within the analytic view. Any query that is executed against the published analytic view must satisfy any mandatory variables. This is a very useful feature if the developer intends for the result set to be limited for a specific date range, attribute, or other criteria. Note that most of the SAP BusinessObjects reporting tools do not recognize these variables at this time. However, we have been told by SAP that this functionality will be fully supported in the next few service pack releases. Variables are different from filters in that they are intended to be dynamic or changed based on the values selected from the input parameters. Filters, on the other hand, are hard coded and must be re-coded by developers when business requirements change.
Variables work hand in hand with input parameters. These placeholder values allow developers to enhance the use of variables by allowing the executor of the query to insert a custom value upon execution. For example, each time the query is executed, the user interface requests that a beginning and ending fiscal year be entered to limit the results. When developers define input parameters, they must indicate the name, database data type, length, and scale. There is also an option to specify the default value of the input parameter if needed for the users.
After the data foundation is defined, the second tab of the analytic view is named the logical view. The logical view is the basis for defining the joins between the analytic foundation and existing attribute views (
Figure 36).
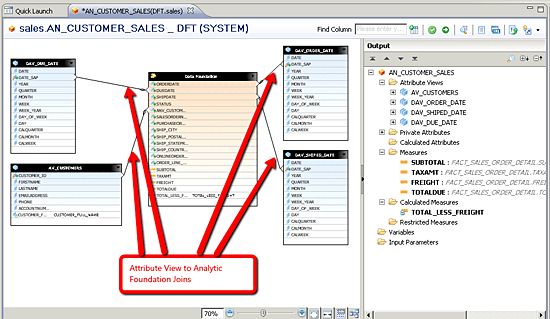
Figure 36
Logical view
Developers add the existing attribute views either using the new analytic view wizard or by dragging them from the navigator pane on the far left side of the SAP HANA Studio modeling perspective. Attribute views are joined to the analytic foundation using the attribute key of the attribute view and the private attributes of the foundation. The basic inner, left outer, and right outer join types are all supported. Each join is assumed to use the equal operator, which limits the use of between, less than, or greater than joins.
There are also two additional join types of joins, referential and text. Referential joins are the default join type. They offer better performance compared to inner joins assuming only a subset of attributes are queried in relation to the overall number of attributes defined in an analytic view. They act as an inner join but they are not enforced if attributes are not selected in a query. This is unlike the SAP HANA inner join, in which attributes defined in the analytic foundation are enforced even when they are not selected in a query. In short, the referential join helps to reduce the number of expensive join operations by eliminating joins that are not relevant to any user defined query.
However, the results of one query to the next might vary because the analytic foundation records will be excluded or included based on the inner joining of the various attribute views selected in the query. They should only be used if the referential integrity between the analytic foundation table and all its attribute views is known to be sound. In database terms, a logical foreign key constraint should exist. In layman's terms, every record in the analytic foundation table should have a matching record in the analytic views. If this is not the case, a query by YEAR and SUM(SALES_DOLLARS) might return different results than a query on YEAR, CUSTOMER and SUM(SALES_DOLLARS) when a sales transaction record exists in the foundation that has no matching customer in the attribute view.
Text joins are used within attribute views. They are a special join type that allows developers to join two tables when one contains characteristics and the other contains the characteristic in a specific language. Text joins were developed specifically to work with SAP ERP tables and the SPARAS field to provide for automatic translation of characteristics. Text joins act as an inner join, meaning that they will restrict the results based on matching records. There is also a special dynamic language parameter. It is defined in the attribute view foundation join definition that is automatically processed within to filter the text to a specific language based on the locality of the user querying the attribute. In short, they are used to provide automatic multi-language support in query results.
Based on the documentation, you can also establish the cardinality between tables to help the various SAP HANA engines quickly and accurately execute the analytic view. We have never noticed any difference in performance when changing the cardinality rules, but we have seen a model fail to activate if an attribute key is not truly unique. When viewing the interface from the Logical View tab, the same output columns and their various types are available. There is no real difference in the output when switching between the data foundation and logic view. The only exception is that attribute views are only visible in either tab once they have been added to the model on the Logical View tab.
Once developers have fully defined the model, they must save and activate the analytic view before it is available within the SAP HANA metadata repository (
Figure 37). To save and activate the model, developers click the save and activate icon. Activation also validates that no rules have been violated within the design of the model. Developers should pay close attention to the Job Log window, as it indicates if there are any failures in the activation. If there are any failures, the font color changes to red, indicating that there was an issue in the attempt to activate the model.
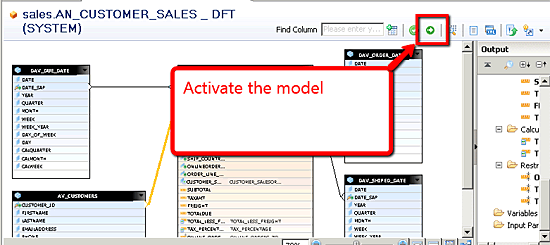
Figure 37
Save and activate the analytic view
Developers can double-click an item in the Job Log to open the Job Details window (
Figure 38). Within this window, a detailed explanation is provided as to the issues that led to the activation failure. The same is true when a model is validated without activation.

Figure 38
Job Log details
Calculation Views
Calculation views are the basis for performing complex calculations, aggregations, and projections. It is difficult to describe the full functionality of calculation views, but they are generally used to produce result sets that span multiple analytic views. A more simple explanation might include the use to produce a distinct count or to further filter and aggregate the analytic view for faster processing. Calculation views can be used to produce a view of that data that spans multiple fact tables or contexts, similar to the way Web Intelligence and a universe manage multiple queries.
In SAP BusinessObjects, the universe and Web Intelligence report engine overcome cross fact aggregation by passing multiple independent SQL statements to the relational database and then merge the results as if they were a single query within the report engine. SAP HANA approaches this differently in that calculation views are used to merge data sets into a single logical view of the data. They incorporate a more set-based philosophy in working with data than you see in a traditional database view or procedure. SAP HANA can provide most of this functionality in a graphical UI (GUI) without the need to write hundreds of lines of SQL code. With that said, calculation views can also be based on script logic if needed.
The calculation view UI is similar to that of the attribute view and analytic view. On the left side, developers can create logic dataset workflows to guide SAP HANA in the processing of the data sets. The center window contains details on only objects selected from the left-side window. The right-side window contains the output column definitions for each items selected from the left side. Each item selected from the left side produces a different view for both the center and right windows (
Figure 39).

Figure 39
Calculation view overview
For the purposes of this special report, we do not go into great detail on all the facets of calculation views. However, we do describe in general terms a solution in which calculation views are used to produce meaningful results.
Take, for example, an analytic view that produces customer sales orders and another that produces customer product returns. The analytic view for each area would be capable of calculating results for not just products and dates, but also for customers, sales reps, distribution centers, and other facets. For the purposes of this solution you only need to use a few of those facets to produce the results.
Using a calculation view, you can develop a results set that compares the number of orders for a given product and subsequently the number of returns for that same set of products. To develop this solution using a calculation view you would start by adding both analytic views to the GUI. You then would project them to include only the columns needed to satisfy the requirements. Projection is a process in SAP HANA in which developers can reduce the amount of in-memory data blocks that are accessed by removing columns from an analytic view that are not needed within the calculation view. In most cases, projecting the analytic view increases the performance of the calculation view.
Once they are projected, you can aggregate the results of the sales analytic view to include the product, year, month, total units shipped, and a null value place holder for products returned. Using the sales returns analytic view, you can aggregate the results to produce product, return year, return month, total units returned, and NULL place holder for units shipped (
Figure 40). The purposes of the NULL value place holders are to facilitate the subsequent UNION of the two results. When performing a UNION, both results sets must have the same number of columns.

Figure 40
Setting a NULL column
Within the aggregation of each set, you create a calculated column and set it to a NULL value (
Figure 41).

Figure 41
Results of a projection and aggregation of two analytic views: products sold and products returned
Taking the results of each aggregation, you then can UNION the records sets. The results of the UNION operation would only be temporarily managed by SAP HANA and never returned by the results set of the calculation view. However, it is important to logically understand what is happening within the sequence of calculations that produce the desired results (
Figure 42).

Figure 42
UNION of the record sets
Using the aggregate option within a calculation view, you can then aggregate the results again to produce a single records set that displays the results as if they were stored together in the database (
Figure 43).

Figure 43
Aggregation of UNION
The setup of such a calculation can be done completely using a GUI. Each object in the GUI represents a different dataset-based operation that can project, aggregate, UNION, aggregate, and output a results set. Within the SAP HANA Studio, this is represented as a series of set-based operations (
Figure 44). From a workflow standpoint, you are simply taking two datasets, aggregating each set, combining the two sets, and then aggregating the combined sets to produce a single result set (
Figure 45).

Figure 44
An SAP HANA Studio calculation view workflow

Figure 45
Logic workflow of a calculation view
Analytic Privileges
Analytic privileges allow developers to define automatic, row-based filters based on an SAP HANA user account. In general, we refer to this as row-level security. Analytic privileges can either protect data or automatically filter data for each SAP HANA logon. They are set up and stored with the same packages that are used to manage attribute views, analytic views, and calculation views.
When defining an analytic privilege, the developer specifies one or more view objects to restrict. Once the objects are selected, they must then define the attribute to restrict. The final step of the process requires that a restriction be set up for that selected attribute. For example, an analytic privilege can set up to restrict the results of a calculation view to only the country of Great Britain (
Figure 46). Once the analytic privileges are saved and activated, the DBA can then assign it to an individual user or a database role (
Figure 47).
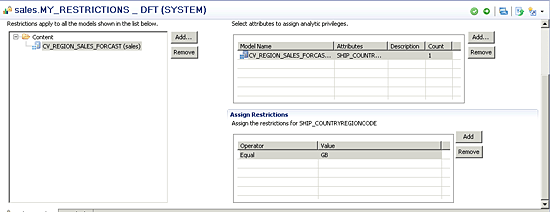
Figure 46
Creating an analytic privilege

Figure 47
Assigning the privilege to a user
Combining the Modeling Components to Produce Analytic Views and Calculation Views
Now that we have discussed all the main components of SAP HANA modeling, it is time to show how they all work together to produce usable, multi-dimensional data models. You start with loading data, using SAP Data Services 4.0, into SAP HANA schemas and tables. You then create attribute views to define all possible facets of your multi-dimensional model. Once the attribute views are created, you define the analytic view. You can also define measures and additional attribute views within the analytic view to complete your multi-dimensional model (
Figure 48). Once you have one or more analytic views created, you can use calculation views to produce data sets that require more complex calculations or processing. If data security is a requirement, you can create dynamic filters that are applied based on individual user accounts or database roles.
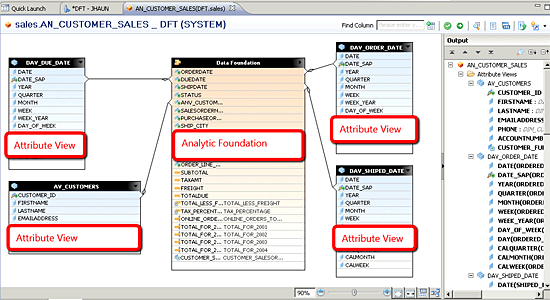
Figure 48
A complete analytic view
Reporting and Analytics
With the multi-dimensional models and columnar tables loaded into an SAP HANA schema, you are now ready to review the different ways that SAP BusinessObjects 4.0 can be set up to use data in SAP HANA.
Various methods are available in SAP BusinessObjects 4.0 to analyze and visualize data loaded into SAP HANA. We begin with the methods by which you can connect data sources built in SAP HANA to the tools available in SAP BusinessObjects. We then highlight the process for connecting a universe, using the SAP BusinessObjects Information Design Tool (IDT) to SAP HANA. Finally, we discuss the various tools that are available, including information about which tools can connect directly to SAP HANA and which must connect via other methods, such as the semantic layer.
Connecting to SAP HANA
In all of the conversations that we have had on analytics and visualizations built on top of SAP HANA, the most frequently asked question we’ve heard is: How do we connect to SAP HANA?
Individuals always wonder if there’s any special learning or knowledge that must be gained before they can successfully connect to data sources with SAP HANA. For the most part, the most difficult part of connecting SAP BusinessObjects to SAP HANA is the configuration of the ODBC or JDBC client drivers. Once you have the connections set up properly, the SAP BusinessObjects 4.0 tools work essentially the same way that they would with any relational source.
SAP HANA Database Client
To connect SAP HANA to SAP BusinessObjects 4.0, you begin with the SAP HANA JDBC and ODBC client. This client is available in both 32-bit and 64-bit for a wide variety of operating systems. You can locate these clients on the SAP Service Marketplace (
Figure 49).
Figure 49
Finding SAP HANA clients on the SAP Service Marketplace
To find the download files, follow these steps.
- Log on to the SAP Service Marketplace (https://service.sap.com/support)
- Choose the Software Downloads tab
- Open the SAP Software Download Center in the left frame and click Support Packages and Patches
- Click Browse our Download Catalog from the left frame
- Click SAP In-Memory (SAP HANA) from the list in the center frame
- Click SAP HANA Enterprise Edition and then SAP HANA Enterprise Edit 1.0
- Click Comprised Software Component Versions
- Click SAP HANA Client 1.00
- Select the appropriate operating system (Figure 50)

Figure 50
Operating system choices for SAP HANA
10. Scroll to the bottom and download the version that matches your SAP HANA database (
Figure 51)

Figure 51
Download options
Note
All SAP HANA client patch installations allow for either an upgrade or a full installation. It is best to only install the version that matches the SAP HANA database that will be used for connectivity to SAP BusinessObjects 4.0. With the SAP BusinessObjects 4.0 server services, you need the 64-bit client. With the SAP BusinessObjects 4.0 client tools, you need the 32-bit version.
Once the correct installation has been downloaded, find a file with a .SAR extension. This is a special SAP archive (much like a ZIP file) that you need to extract using a utility called SAPCAR.exe. You can find SAPCAR.EXE in the SAP Service Marketplace. To download SAPCAR in the SAP Service Market Place, use the following steps:
- Choose the Software Downloads tab
- Choose Support Packages and Patches from the left frame
- Choose Browse our Download Catalog from the left frame
- Choose Additional Components
- Choose SAPCAR (Figure 52)
- Select SAPCAR 7.10
- Select the appropriate operating system where you will run the utility.
Figure 52
SAPCAR options
SAPCAR does not require any installation to use. It is standalone executable. Simply download it and save it to any folder. To use SAPCAR you must access it from the command line. For example, you can extract the SAP HANA client .SAR archive using the following example:
SAPCAR – xvf IMDB_CLIENT100_XXXX.SAR (
Figure 53).
Figure 53
Extract the downloaded SAR file
This extracts the SAP HANA client to a sub folder within the path in which you executed SAPCAR. Within the newly extracted folder, look for hdbsetup.exe. This starts the installation of the SAP HANA client. If you are upgrading your client, choose the Update SAP HANA Database Client option (
Figure 54). If you are installing for the first time or installing side-by-side, choose the Install New SAP HANA Database Client option. With the appropriate install option selected, review and confirm the installable components and click the Install button (
Figure 55). Step 3 (Install Software) displays the progress of the installation. Once complete, Step 4 (Finish) displays (
Figure 56). Click the Finish button to close the installation wizard.

Figure 54
Define the SAP HANA client install options
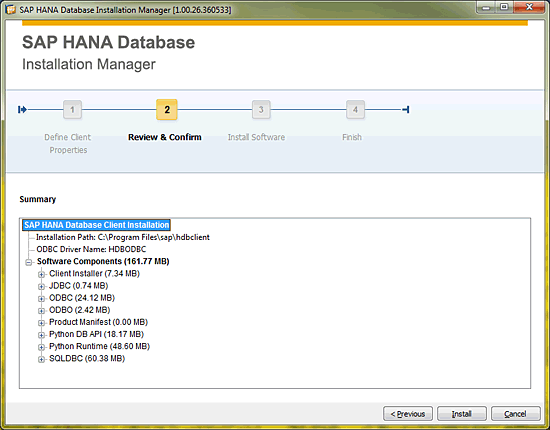
Figure 55
Review the SAP HANA client installation components
Figure 56
Complete the installation
SAP HANA ODBC Data Source
Now that the database client is installed, the next step is to open the ODBC Data Source Administrator. For SAP BusinessObjects 4.0 client tools, open the 32-bit ODBC data source at c:windowssyswow64odbcad32.exe. For SAP BusinessObjects 4.0 server services, open the standard 64-bit ODBC manager found in the control panel.
When the ODBC source is created on the SAP BusinessObjects 4.0 server, it must be created as a 64-bit ODBC data source because the SAP BusinessObjects 4.0 server runs as a 64-bit application. A typical ODBC Data Source Administrator looks something like the screen in
Figure 57. Click the System DSN tab and click the Add button to add a new data source.

Figure 57
The ODBC Data Source Administrator
Scan the list in Figure 58. Find the HDBODBC data source, select it, and click the Finish button to open the SAP HDB properties page.
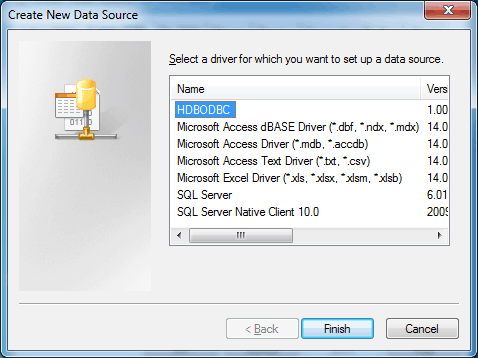
Figure 58
Select the HDBODBC data source
Enter a short name for the ODBC data source along with a description, the server name, and port number (Figure 59). In the Server:Port field, enter <hostname.domain.com>:<port>. The default port for most SAP HANA database instances is 30015. This information can be determined by contacting your SAP HANA administrator.
Once the information is entered, click the Connect button. A new window appears (
Figure 60). Within the window, enter a valid SAP HANA user and password and click the OK button to verify the connection details. A new window appears to verify that your connection is set up properly (
Figure 61). If your connection is successful, click the OK button on each subsequent window until the ODBC data source administrator is closed (
Figure 57).

Figure 59
Provide a name, description, server, and port for SAP HANA
Figure 60
Enter valid credentials for SAP HANA
Figure 61
Successful connection message
If you receive an ODBC error (Figure 62), check with the SAP HANA administrator to verify that the connection details are correct and that the SAP HANA system is available.
Figure 62
An error in creating the connection to SAP HANA
Once the ODBC data source is built on your workstation (Figure 63), ensure that the same data source is created on the BusinessObjects Enterprise 4.0 servers to which you will publish your semantic layers, analytics, and visualizations. Without this, analytics and visualizations created or published on the SAP BusinessObjects 4.0 server will not connect to the SAP HANA data source. You are now ready to build a semantic layer using the ODBC data source.

Figure 63
A completed ODBC Data Source Administrator with SAP HANA
SAP BusinessObjects IDT
We now discuss the steps required to use the SAP HANA ODBC data source connection to create a semantic layer with the SAP BusinessObjects IDT. This is not a step-by-step guide on how to create an IDT universe, but rather an overview of how a developer would establish relational connections to SAP HANA using ODBC drivers. Once an SAP HANA relational connection is created in the IDT, universe design processes are very similar to those used with any relational source. There are a few exceptions to this statement, which we discuss below.
Developers need an IDT universe to support SAP HANA data access for SAP BusinessObjects Web Intelligence, SAP Crystal Reports for Enterprise, and SAP BusinessObjects Dashboard Design. SAP BusinessObjects Analysis for OLAP and SAP BusinessObjects Explorer do not use the universe layer to connect to SAP HANA. It is also worthy of mention that both Crystal Reports 2011 and Crystal Reports for Enterprise can now directly connect using ODBC. In addition legacy UNV Universes can connect using ODBC to SAP HANA starting with SAP BusinessObjects 4.0 SP4.
There are two main methods or methodologies for creating an IDT universe. You can either connect directly to the SAP HANA base columnar tables or you can connect the universe directly to the analytic views or calculation views developed using the SAP HANA Studio. However, before developers can access the SAP HANA tables or analytic view they have to create a connection to the data source within the IDT. Within the IDT developers create a connection to SAP HANA within the standard Repository Resources window (
Figure 64). They follow the same process that is used for creating any typical relational connection.

Figure 64
Typical Repository Resources and connections
During the process of creating a relational connection to SAP HANA, the Database Middleware Driver selection window appears. The SAP HANA ODBC and JDBC drivers are found under SAP>SAP HANA database 1.0 > ODBC or JDBC (
Figure 65). Outside of the location of the SAP HANA drivers, the process for creating the connection to SAP HANA is the same as always.
Figure 65
Select the ODBC drivers in the Database Middleware Driver Selection
After selecting the ODBC driver option the developer clicks the Next button. The connection wizard then requests the authentication options, server and port information, and user name and password required to connect to an instance of SAP HANA (Figure 66). The server name is entered in using the standard <host:port> convention – for example, sap-hana.org:30015. You can use the Test Connection button to validate that everything from the ODBC to the IDT Universe connection information is in working order.
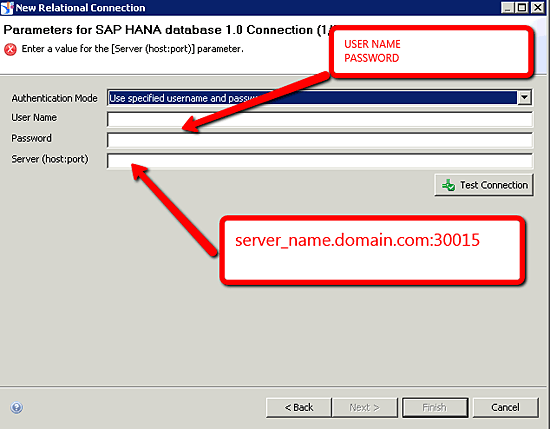
Figure 66
Configure the IDT Universe SAP HANA authentication and server
SAP HANA Tips for the IDT Data Foundation Layer
With the server side connection and the connection shortcut created in the local project, you now create a data foundation layer. Again, the scope of this section of this report is to help developers understand the concepts within IDT specific to SAP HANA. How a developer accomplishes basic tasks within IDT is beyond its scope.
As mentioned before, you can set up a data foundation for an SAP HANA universe in two ways:
- You can directly use the SAP HANA models, both analytic views and calculation views, which you created in the SAP HANA Studio
- You can use the base columnar tables that were loaded by SAP Data Services 4.0
If the universe will be used directly to support analytical calculations in charts, graphs, tables, and other visual components, it is best to use the analytic views or calculation views in the data foundation of your universe. The analytic views already contain all the modeling work needed to facilitate these types of BI needs.
However, if your universe will support enterprise reporting, generate lists of records, or provide insight into data that is not highly aggregated or measured, it is best to use the base tables to set up the data foundation.
There is no simple guide to help developers make the correct choice, but each query executed against an analytic view must contain a group by and aggregate function. With this in mind, it would only really facilitate analytic analysis of data.
It is also important to remember that you need analytic views to support SAP BusinessObjects Explorer or Analysis for OLAP. Some organizations do not want to develop and support both SAP HANA analytic view metadata and traditional universe metadata. When the base tables are used, there are no requirements to execute a SUM() or group by statement to facilitate SAP HANA-based queries. However, it is wise to include measures containing database level aggregates in either scenario.
When working with the IDT universe data foundation, developers can locate the SAP HANA analytic views or calculation views by examining the _SYS_BIC schema. Within this schema, developers see a relational representation of the multi-dimensional model stored in the SAP HANA metadata repository. Analytic views can be located by their distinct icon and name. The analytic view icon has an orange cube and the fully qualified name that includes the package, analytic view, and the term OLAP within its name (e.g., package/analytic view/olap.) Simply add these table objects to the foundation and you are finished (
Figure 67).
Figure 67
A listing of schemas in the IDT
Because all the required modeling was completed on SAP HANA, there is no need to set up any additional items at this level. Future releases of SAP BusinessObjects will allow for direct binding to SAP HANA models. This will render the need to set up universes on those models obsolete. However, because that functionality does not yet exist, we provide details on how to use them in current versions of SAP BusinessObjects 4.0.
When working with the IDT universe data foundation, developers can locate the base columnar tables within the schema to which the data was loaded using SAP Data Services 4.0. From a traditional BusinessObjects universe design standpoint, the process for using the columnar tables is exactly the same as developing a universe against any RDBMS. The developer adds the tables to the data foundation, joins them based on the appropriate columns, filters them based on business or technical rules, or creates derived tables to facilitate advanced calculations. In short, this is the traditional BusinessObjects universe design process (Figure 68). If developers choose to build their universe on the base tables, they are bypassing all the models that were created in SAP HANA Studio. In effect, they will now be responsible for creating all the joins, aliases, and filters that are needed to facilitate the de-normalization of the data.
Again, we do not go into the details of how the data foundation is set up in the IDT. However, this information should provide developers with an overview of the two options available for creating data foundations within the IDT when SAP HANA is the source.

Figure 68
A standard or traditional IDT data foundation using SAP HANA as the source
SAP HANA Tips for the IDT Business Layer
Whether developers are using an analytic view or the base columnar tables within their foundation, they need to define the business layer (
Figure 69). The process for defining the business layer is the same for both types of foundations. You define dimensions, measures, details, restrictions, and classes in an organized, business-centric structure. Developers can also add calculations, derive columns, and add additional logic at this layer.
Figure 69
A business layer created from an analytic view-based data foundation
The main goal of the business layer is to make it easy for a non-technical user to locate data elements, but business logic can be expressed at this layer using the SAP HANA SQL functions. If the business layer is defined on foundations that are using the SAP HANA analytic views, make sure that all the measures have the SUM(), MIN(), or MAX() functions defined to prevent errors when executing queries. Arguably, this should be implemented for any universe to push down aggregation to the underlying RDBMS.
We do not go into detail about how the business layer is set up in the IDT. However, this information should provide developers with an overview of the options available for creating business layers within the IDT when SAP HANA is the source.
Using Visualization and Analytic Tools in SAP HANA
Now let’s look at which tools can connect directly to SAP HANA and which must connect via other methods, such as the semantic layer.
SAP BusinessObjects Web Intelligence
SAP BusinessObjects Web Intelligence provides a highly interactive and customizable way to report on data from virtually any data source in any system. Web Intelligence places the power of ad hoc analysis back into the hands of the business by providing users the ability to retrieve, visualize, analyze, and share and store queries and reports. The business is no longer required to request that reports be developed by IT and then published.
SAP BusinessObjects Web Intelligence can connect to SAP HANA through a pre-developed semantic layer in the IDT. The process for connecting a Web Intelligence report to a universe is beyond the scope of this article, but here are a few tips specific to universes based on SAP HANA:
- If your Web Intelligence reports are using a universe based on the SAP HANA analytic view, you need to include a measure in every query.
- If your Web Intelligence reports are based on a universe that incorporates the base SAP HANA tables, you can use any type of basic query.
- If your report needs multiple queries to facilitate requirements, it is better to ask the universe designer to add context or derived tables to the universe to fully use SAP HANA. There are several development techniques and parameters in the universe that can force SAP HANA, and not the Web Intelligence report engine, to process multiple queries
SAP BusinessObjects Dashboards
SAP BusinessObjects Dashboards is a flexible dashboard development tool that allows designers to build customized dashboards in nearly any configuration imaginable. Dashboards historically have been built with data contained within an embedded Microsoft Excel spreadsheet.
In recent years, the SAP BusinessObjects Dashboards (formerly known as Xcelsius) application has been expanded to include data sources from external locations such as Web Services, LiveOffice, XML Data Maps, BEx, and others. As of SAP BusinessObjects 4.0, dashboard design has been updated to allow for direct query binding to universes designed in the IDT (example in
Figure 70). Similar to Web Intelligence, there are no special skills over and above standard dashboard design techniques and direct binding knowledge needed in order to connect dashboards to SAP HANA.
Figure 70
A dashboard using direct binding to an SAP HANA IDT universe
There are no special requirements for connecting dashboards to SAP HANA data. Developers will find that all the legacy and new options available for connecting dashboards to live data apply with SAP HANA. Following are the connections available for connecting dashboards to a live SAP HANA data source:
- Direct binding of queries (new feature in SAP BusinessObjects Dashboard 4.0)
- QaaWS (Query as a Web Service)
- BIWS (BI Web Services)
- Excel with LiveOffice connectivity
Again, this is nothing unique to SAP HANA, but it is important to understand that in order to use the SAP HANA engine within dashboards, developers must create a universe on SAP HANA as a starting point.
SAP Crystal Reports 2011
SAP Crystal Reports is a well-known reporting tool that allows users to develop highly professional, pixel-perfect reports. While not as quick and easy as Web Intelligence, Crystal Reports provides the ability to create complex reports. However, Crystal Reports 2011 cannot take advantage of the IDT universe semantic layers to develop reports.
In Crystal Reports 2011, use the ODBC (RDO) connector to attach directly to the tables and views (
Figure 71). To connect to an instance of SAP HANA from Crystal Reports 2011, create a new blank report. Select ODBC, then pick the HANA ODBC data source. Enter the correct credentials. The listing of schemas, including the _SYS_BIC schema, displays.

Figure 71
Open the ODBC (RDO) connector and select an existing ODBC (SAP HANA) connection
Developers can choose to use the base columnar tables or write their own custom SQL command to access SAP HANA. From this point forward, you build the Crystal Report using standard design methodologies and best practices. Developers can also use analytic views with Crystal 2011, but they need to write custom SQL commands that include the SUM() and group by requirements to use these OLAP objects in the _SYS_BIC schema.
SAP Crystal Reports for Enterprise
SAP BusinessObjects Crystal Reports for Enterprise is a new, Java-based version of Crystal Reports that simplifies and standardizes the reporting capabilities of the legacy Crystal Reports application. Crystal Reports for Enterprise provides the ability to connect to semantic layers (UNX) as well as SAP HANA and SAP NetWeaver BW BEx sources.
There are two options for accessing SAP HANA data for Crystal Reports for Enterprise:
- Select an existing universe that is based on SAP HANA
- Use ODBC or JDBC to connect directly to the schemas and tables in SAP HANA
The ODBC or JDBC option is similar to the options for Crystal Reports 2011, whereby developers can select the tables or develop custom SQL commands to access the analytic views or tables in SAP HANA.
SAP BusinessObjects Analysis for OLAP
SAP BusinessObjects Analysis for OLAP is a Web-based client tool or application that is imbedded within the BI Launchpad. It allows ad-hoc users or developers to create a traditional OLAP style report that can display charts, graphs, or crosstabs in one or more tabs while directly using the hierarchies and measures defined in SAP HANA analytic views and calculation views.
Analysis for OLAP connects to SAP HANA directly without the use of a universe or ODBC connection. It is capable of parsing and displaying the metadata of SAP HANA analytic views and calculation views to display objects in a more native OLAP fashion. It is also capable of displaying and interacting with the hierarchies that are defined in SAP HANA.
Analysis for OLAP can only connect to SAP HANA analytic views and calculation views. To enable this connectivity, SAP BusinessObjects administrators need to create an SAP HANA OLAP connection in the Central Management Console (CMC). The OLAP connections section of the CMC has an option for SAP HANA (as of SAP BusinessObjects 4.0 SP4). The connection information is configured in a way that is similar to the options required for ODBC and JDBC connectivity.
Figure 72 contains an example of how this looks in the CMC. Once the OLAP connection object is created, Analysis for OLAP recognizes and is capable of connecting to SAP HANA analytic views.
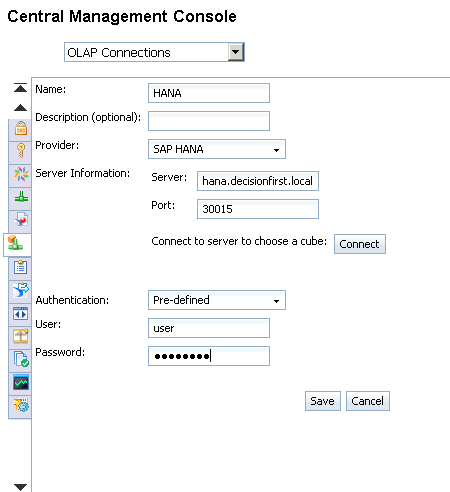
Figure 72
The CMC option for connecting to SAP HANA
SAP BusinessObjects Explorer
SAP BusinessObjects Explorer is a data visualization and analysis tool that provides unprecedented access to your data by giving users the ability to directly interact and visualize the data with a small learning curve. The dimensions (also known as facets in Explorer) are presented in a horizontal order along the top of the interface. Touching the data within each facet filters the data in the visualization at the bottom of the interface.
SAP BusinessObjects Explorer can connect directly to SAP HANA without the need for a universe, cached information space, or any SQL code. Its connectivity is similar to how Analysis for OLAP connects directly to SAP HANA, but Explorer does not use hierarchies defined in analytic or calculation views. Explorer can also use a universe based on SAP HANA, but this option moves the data from SAP HANA and into the Explorer information space on the SAP BusinessObjects server. With the data on the SAP BusinessObjects Explorer server, the scalability and performance of the information space becomes degraded.
SAP has provided a special connection to SAP HANA within Explorer. It can be accessed when designing the Information Space. If an SAP HANA relational connection is detected in the repository, Explorer automatically adds the SAP HANA appliance connection option to the list of available sources (
Figure 73). As the nodes under the SAP HANA appliance are expanded, developers see a list of available analytic views and calculation views that they can use as a source for SAP BusinessObjects Explorer information spaces. Once an analytic view or calculation view is selected the process for creating a Information Space is the same as with any source. The details of how Information Spaces are built are beyond the scope of this report, but it is important to understand that SAP BusinessObjects Explorer has special direct access to SAP HANA.
Figure 73
The SAP HANA appliance options in the SAP BusinessObjects Explorer Information Space
Other SAP Visualization and Analysis Tools
So far, we have given examples of some of the most popular tools available for visualization and analysis from SAP. While tools such as Web Intelligence, Crystal Reports, BusinessObjects Dashboards, and BusinessObjects Explorer provide a wide range of capabilities, other tools are available now or coming soon that provide expanded functionality, including SAP Visual Intelligence and SAP BusinessObjects Design Studio.
SAP Visual Intelligence is a desktop application that connects to OLAP and SAP HANA data sources. The look and feel of SAP Visual Intelligence is similar to Explorer. SAP Visual Intelligence tends to merge the functionality of information spaces and exploration views into a single, cohesive interface. Connecting to SAP HANA data sources in SAP Visual Intelligence is as easy as selecting the data source type (SAP HANA) and entering the server name, port, user name, and password. You can even take SAP HANA data offline for visualization and analysis when you are not connected. SAP Visual Intelligence 1.0 is currently available on the SAP Service Marketplace.
SAP BusinessObjects Design Studio (formerly known as SAP Zen) is due for release in November 2012. Design Studio takes the concept of customized dashboards to a new level by providing drag-and-drop components and “wiring” through dialog-driven JavaScript. It also has the ability to publish dashboards as HTML5, which is consumable on mobile devices, most notably iOS devices. Design Studio (beta) can connect to SAP NetWeaver BW and SAP HANA. You simply create the connections within the Preferences > Backend Connections dialog in the application. Designing the dashboards is no different in SAP HANA than for SAP NetWeaver BW.
Tool Connectivity Matrix
In summary, the various applications offered by SAP BusinessObjects connect to SAP HANA data sources in different ways.
Table 1 is a matrix that displays the various ways that analytic and reporting tools connect to SAP HANA. The semantic layer (UNX) connects to SAP HANA using a standard ODBC or JDBC connection as described earlier in this special report. Crystal Reports 2011 connects directly using ODBC or JDBC without the use of a universe. Crystal Reports for Enterprise can connect using a universe and ODBC or JDBC. There are also other tools that can connect natively to SAP HANA.
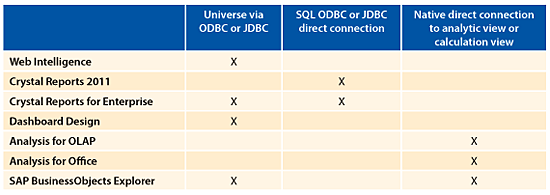
Table 1
SAP BusinessObjects tool connectivity matrix
Conclusion
After reading this special report, you should have a better understanding of the tools, processes, and components that make up a successful SAP HANA standalone deployment. Successful solutions on SAP HANA standalone start with SAP Data Services 4.0, in which data is cleansed and loaded, and end with SAP BusinessObjects 4.0, in which data is visualized and analyzed. However, at the center of this solution is the revolutionary SAP HANA in-memory database and analytics engine.

Decision First Technologies
Decision First Technologies (DFT) is a professional services company specializing in delivering end-to-end business intelligence solutions to its customers. An SAP gold-channel partner and six-time SAP BusinessObjects Partner of the Year, DFT resells and offers certified consulting, training and technical support for all analytics as well as database and technology products in the SAP BusinessObjects portfolio. DFT’s comprehensive BI solutions allow users to access, analyze, and share information stored in multiple data sources, including SAP and non-SAP environments. The company’s data warehousing practice designs and implements enterprise solutions utilizing SAP Business Warehouse, appliances such as SAP HANA or traditional relational database technologies. With more than 10 years of experience, DFT has helped hundreds of companies make better business decisions, dramatically reducing costs, increasing revenues, and boosting profits. For more information on Decision First, visit
https://www.decisionfirst.com/ or follow on Twitter
@DecisionFirst.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.

Jonathan Haun
Jonathan Haun, director of data and analytics at Protiviti, has more than 15 years of information technology experience and has served as a manager, developer, and administrator covering a diverse set of technologies. Over the past 10 years, he has served as a full-time SAP BusinessObjects, SAP HANA, and SAP Data Services consulting manager for Decision First Technologies. He has gained valuable experience with SAP HANA based on numerous projects and his management of the Decision First Technologies SAP HANA lab in Atlanta, GA. He holds multiple SAP HANA certifications and is a lead contributing author to the book
Implementing SAP HANA. He also writes the All Things BOBJ BI blog at
https://bobj.sapbiblog.com. You can follow Jonathan on Twitter @jdh2n.
You may contact the author at
jonathan.haun@protiviti.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.

Christopher Hickman
Christopher Hickman is associate director, data and analytics, at Protiviti. Previously, he was a principal consultant at Decision First Technologies. He has experience in the SAP BusinessObjects suite of applications as well as ESRI's range of GIS applications (ArcGIS Desktop, Server, Business Analyst Desktop, BA Server, etc) and systems used to tie the two together (APOS, Centigon, Antivia), resulting in fully featured business and location intelligence systems. He is also heavily engaged in social media and the opportunities presented with the synergy generated from various social media utilities. You can follow Chris on Twitter
@chickman72.
You may contact the author at
chris.hickman@decisionfirst.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.

Don Loden
Don Loden is an information management and information governance professional with experience in multiple verticals. He is an SAP-certified application associate on SAP EIM products. He has more than 15 years of information technology experience in the following areas: ETL architecture, development, and tuning; logical and physical data modeling; and mentoring on data warehouse, data quality, information governance, and ETL concepts. Don speaks globally and mentors on information management, governance, and quality. He authored the book
SAP Information Steward: Monitoring Data in Real Time and is the co-author of two books:
Implementing SAP HANA, as well as
Creating SAP HANA Information Views. Don has also authored numerous articles for publications such as SAPinsider magazine, Tech Target, and Information Management magazine.
You may contact the author at
don.loden@protiviti.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.