/HANA
Gain an understanding of the key differences between SAP HANA and traditional relational database systems in an SAP BusinessObjects environment, and learn how BusinessObjects has been optimized for SAP HANA.
Key Concept
SAP HANA is a multipurpose, data-source-agonistic, in-memory appliance that combines SAP software components optimized on hardware provided by SAP partners. SAP HANA provides capabilities for real-time operational analytics and use as an Agile data mart.
This article was originally published on BusinessObjects Expert
Before I get into how SAP HANA works within SAP BusinessObjects environments, I want to take a brief moment to describe how traditional relational database management systems (RDBMS) work with BusinessObjects. The process is summarized through the following steps:
- Step 1. Go to the relational database system and build a table to store operational detailed data.
- Step 2. Load this table with operational data from a transactional system.
- Step 3. Create indexes on the table based on how you expect users to run queries against the table.
- Step 4. Create a summarized data mart table that pre-aggregates information based on how you expect users to report on the data.
- Step 5. Create indexes on this summarized data.
- Step 6. If you require multi-dimensional OLAP capabilities (e.g., dimensions, attributes, or hierarchies) then use a Multidimensional OLAP InfoCube-type environment (e.g., Essbase, Cognos BI, Microsoft Analysis Services).
- Step 7. Build a universe in BusinessObjects.
- Step 8. Run a report.
- Step 9. Go back and redo Steps 1 through 8 as required until performance has been optimized for the question you’re asking. If you change the question you want to ask, then go through Steps 3 through 6 again (and maybe again and again).
As you can see, this is typically a cumbersome process that involves a lot of IT personnel dedicated specifically to tuning and optimizing the database. SAP HANA approaches the problem of how users get information by providing a different method to managing information based on three core technologies: columnar storage, in-memory, and massive parallelization. Below are more details about these core concepts.
What’s Different with SAP HANA?
Let’s look at how SAP HANA works for BusinessObjects reporting.
Columnar Storage
RDBMS databases use row storage to store data. This storage was optimized specifically for transactional systems. For example, let’s look at some employee HR data that a company uses to store the income for its employees. A row storage table for this type of data is stored in a format shown in Figure 1.
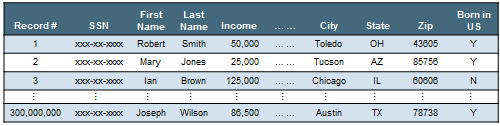
Figure 1
Example of employee data stored in a row table
This is great for scenarios involving new employees. If you have a new employee, you can just insert a record at the end of the table. However, suppose you want to calculate the average income of all your employees, which is a typical BI-type query. In this case, you have to read the entire table by doing a full table scan.
Indexes and other optimization techniques may speed up queries, but fundamentally, you have to perform significant optimizations in the row storage to get the data you want. You may decide you want to ask a different question (e.g., What are the top five salaries of employees in the state of Ohio?). Optimizing each one of these scenarios in a row store requires that you know what questions to ask before business users ask them.
In contrast to row storage, SAP HANA uses columnar storage to store data for analytical queries. In a columnar store, data is stored in the database in the format shown in Figure 2.

Figure 2
Example of employee data stored in a column table
In this column table, if you want to get the average income of the employees in the United States, the system can just look up the Income field and take an average of the employees without reading the whole table as in the row store. This type of storage reduces input/output (I/O) in database read times, and that is crucial for optimizing performance of BI queries.
In-Memory
In addition to the I/O improvements you get by storing the data in a columnar format, there are further I/O improvements from storing all the data in-memory. A read from memory is roughly 1 million times faster than a read from a disk.
Traditional RDBMS systems use memory as a caching layer. Even modern appliances in the market (e.g., Teradata appliances, Exadata appliances) use memory as a cache. The difference with SAP HANA is that all your data resides directly in-memory. This is a different approach than having data cached in-memory.
By having all data in-memory, SAP HANA ensures that users have consistent performance because I/O-based reads in-memory are significantly faster than disk-based reads. In traditional database systems, if the data exists in an in-memory cache, then performance is good. However, if a user asks a business question via a BI query and the data is not available in the cache, the user experiences sub-par performance. Combining the columnar storage with in-memory capabilities makes SAP HANA a more suitable environment for BusinessObjects than a traditional RDBMS — BusinessObjects customers who have implemented SAP HANA have seen from 10-times to 1,000-times performance improvement on typical queries.
You might be wondering, why now? Memory is not new. It’s been around forever. What’s new is that memory prices have dropped significantly and multi-terabyte memory systems are now affordable. SAP HANA relies on commodity appliances available from a variety of hardware vendors, such as IBM, HP, Dell, Cisco, Fujitsu, and Hitachi. As multi-terabyte memory systems have become commonplace, software needs to be engineered to take advantage of the ability to use all data in-memory. SAP HANA is built in this way.
Massive Parallel Processing
BI query performance is not just dependent on reading data; performance also relies on computation capabilities. The massive parallel processing (MPP) architecture of SAP HANA allows you to use parallel processing across nodes, datasets, and even central processing unit cores within SAP HANA. Therefore, complex calculations can be parallelized to use memory as well as compute power. Today, SAP HANA uses Intel Westmere processors, which are 10-core processors. A single 1 terabyte system typically has about 80 cores of processing power, and queries are distributed not just across memory, but also across the core.
Additionally, SAP HANA software is designed so that as data volumes grow, the infrastructure can scale through data distribution across numerous appliance nodes as shown in Figure 3. Nodes can either be RAC servers or blades as part of a blade server configuration. Whether RAC or blade servers are used depends on the hardware configurations customers choose.

Figure 3
Data stored across blades within an SAP HANA appliance
The benefit of an infrastructure that can scale is that companies can add more memory and compute power as their data grows. The core tenets of distributing the data are as follows:
- RAM locality – Data is spread out to all available cores
- MPP execution – Blades share nothing when crunching large data sets
- Failover - Individual blades may fail without causing problems
One tenet that is true for almost all companies is that the amount of data they have available in their enterprise continually grows. SAP HANA’s infrastructure can scale with data volume growth.
BusinessObjects Optimized for SAP HANA
BusinessObjects traditionally relies on the semantic layer for optimized data access with SAP HANA. With BusinessObjects 4.0, the semantic layer and the BI tools are optimized to connect to SAP HANA natively to get data. Each visualization within the BI portfolio has an optimized way of accessing data from SAP HANA (Figure 4).

Figure 4
Client interfaces accessing SAP HANA from BusinessObjects
These options show that the entire BusinessObjects 4.0 portfolio is supported for visualizing data within SAP HANA.
The Result: Simplification
The premise of SAP HANA technology is an overall reduction in the total cost of ownership (TCO) through simplification. For a data mart without SAP HANA, for example, companies have to replicate data into SAP HANA and have numerous tuning layers of indexes, aggregates, and data marts, just to get reports out through BusinessObjects. SAP HANA simplifies this approach as users can build logical views (analytical views) on top of their data that is replicated into SAP HANA from the transactional system in real time. This simplification allows users to report on real-time transactional data as it happens. The simplified approach is depicted in Figure 5.

Figure 5
The simplified approach of SAP HANA
Additionally, for data marts, companies have more flexibility in dealing with business change. In a traditional relational database environment, if users need to add or remove a field to their data model, it is expensive because you need to modify indexes, aggregates, and data marts throughout the whole Layered, Scalable Architecture. Within SAP HANA, as the data is typically stored once in a columnar format and layers on top are logical views, changes to hierarchies or fields are simple and not as expensive from a tuning and data model modification standpoint.
Note
The term Layered, Scalable Architecture refers to a method of structuring the data in your system such that you consider objects as being organized into layers, in which each layer performs a different task.
In conclusion, SAP HANA differs in five key ways from a traditional RDBMS:
- Data volume – SAP HANA compresses data via a columnar format and doesn’t duplicate data numerous times via a Layered, Scalable Architecture. Thus the size of the database to manage is significantly smaller than traditional database systems.
- Calculation speed – With all data in-memory and parallelized via the MPP approaches of SAP HANA, the calculation speed of SAP HANA is superior to traditional RDBMS systems.
- Information latency – Data can be replicated into SAP HANA in real time and visualized directly in BusinessObjects without pre-aggregation or materialization. This provides a “real” real-time experience to see data as it happens.
- Flexibility – Data model or hierarchy changes are less expensive in SAP HANA versus traditional databases because SAP HANA doesn’t rely on pre-materializing aggregates.
- Data governance – In traditional databases, IT spends time reconciling data as data is duplicated in the architecture numerous times. SAP HANA condenses the approach of managing data, such that data is not pre-aggregated numerous times, thus simplifying data governance.
Prakash Darji
Prakash Darji is an experienced professional with more than 10 years of end-to-end experience in enterprise software. He has a broad depth of experience including corporate strategy, sales, product management, architecture, and development. He has experience in product launch activities, including positioning, packaging, and pricing. He has delivered numerous product releases in a variety of capacities through his career. He thrives on building high-performing, scalable teams to achieve strategic deliverables, whether they close strategic sales deals, roll in product features, or roll out new releases. He is a recurring author for several publications and a speaker at SAP conferences around the world. Prakash is on LinkedIn at https://www.linkedin.com/in/prakashdarji.
You may contact the author at editor@BIexpertOnline.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.





