Poor data management can lead to many problems, from incorrect data, to a lack of integration, to bad analysis. Learn ways an effective data management strategy can help you in your efforts to optimize your system’s performance while increasing your compliance and reducing cost.
Key Concept
Data management is a critical component of running a highly effective business and must be considered in all phases of any major SAP implementation or transformation. Effectively employed, it should encompass all aspects of data creation, including establishing application master data, ascertaining data ownership, defining and enforcing data management policies, data cleansing and conversions, data governance, and the eventual storage of data that is no longer needed for daily business transactions.
It is becoming increasingly apparent to us that effective data management is critical to day-to-day business operations and a key component of a successful operating model. In reality, data affects every single business activity including product and service quality, profitability, business partner satisfaction, financial compliance, validity of business analytics, and end-user experience. Data management preparations should be paramount in all phases of an implementation life cycle and, therefore, are deserving of a closer look.
The Data Management Imperative
In recent years, the amount of data that many organizations need to manage has grown exponentially, especially with globalization efforts and an increase in mergers and acquisitions across business units. Regulatory trends, particularly in the areas of financial compliance and privacy protection of personally identifiable information, have increased the stakes for managing data effectively. In addition, the trend in packaged enterprise applications (e.g., SAP ERP) is for configuration and analytical responsibilities increasingly to shift to business process owners. The result is a dynamic business application, a software system that is:
- Representative of a business process
- Built for constant change
- Adaptable to business context
- Information rich
This is a positive development in terms of enabling business innovation, but it makes the management and control of data more complex. As a result, businesses need to handle many issues when dealing with the management of data. Typical issues to address include:
- No consolidated view of master data is available across the enterprise
- Inconsistent and duplicate master data exists across multiple applications
- Master data is distributed throughout the enterprise using custom interfaces or manual procedures
- The cost of master data ownership is unknown or unacceptably high
- Redundant data management processes increase the cost of regulatory compliance
- Each application has its own local data governance procedures
- Lack of data archiving causes production instances to grow, decreasing their performance and increasing IT maintenance and infrastructure costs
- The time and cost associated with performing backup, recovery, replication, and upgrades is extremely high
- Decisions are based on incorrect data
Data Management Maturity and Security
Effective data management promotes the establishment of quality foundational data, development of robust policies and standards geared towards data maintenance, and compliance with regulatory requirements. At the outset of any new system implementation, or a major change to an existing system (e.g., merging in a new business), design of both the data and the data management processes need to be performed with a view of the data life cycle (Figure 1).
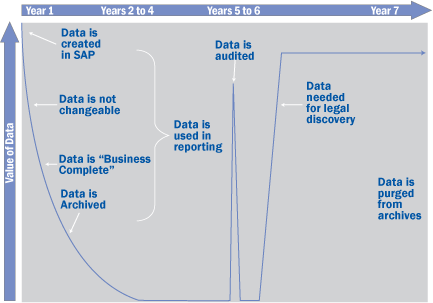
Figure 1
Value of data over its life cycle
When the proper attention is placed on data design, data quality, and data management processes during the implementation, the business is in a better position to benefit from a more focused and effective staff (as they should be spending less time chasing issues and resolving data quality problems) and enhanced system performance. Unfortunately, many organizations underestimate the amount of effort that is needed to prepare the data and data management processes. This usually results in lower business process capabilities and higher long-term costs. These implementations set the stage for operating reactively, the lowest level of data management maturity as shown in Figure 2.
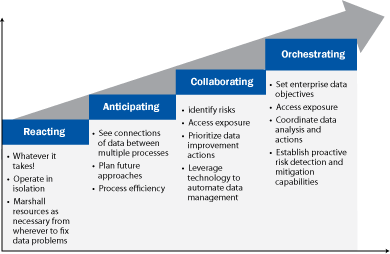
Figure 2
Level of data management maturity
Organizations that have a high level of data management maturity (in the Orchestrating box in Figure 2) set enterprise data objectives and coordinate data analysis and actions across businesses and business processes. Organizations at this level of maturity are in a much better position to gain substantial benefits in terms of business process capability and low-cost use and maintenance of data. As shown in Figure 2, there are intermediate levels of maturity, and, while it is most effective to orchestrate data management from the beginning of the implementation, some organizations mature their capabilities over time.
Orchestrating data management also includes establishing proactive risk detection and prevention capabilities to facilitate effective data security. Recently, widely publicized data loss events have reignited the focus on proactively managing data security risks. In fact, according to a recent Gartner study in Infrastructure Protection Research, the cost associated with data loss, data breaches, or unintentional disclosure of intellectual property more than justifies the need for a well-defined data security process, one that protects data where it is stored and while it is being used. [1]
To fully protect data, you must consider both internal and external threats. Data masking (i.e., the practice of obscuring data elements within a data store) and database monitoring technologies are common techniques to help protect an organization from internal threats. However, external threats can be mitigated by encryption technologies at database end points. Regardless of the source, threats to the system must be proactively managed and monitored. You need to make every possible effort to remediate data security weaknesses before they are exploited.
Set the Stage for a Successful MDM Approach During the Design Phase
Without a comprehensive data management strategy, the data that is fundamental to day-to-day business can be inaccurate and inconsistent, leading to end-user struggles and system inefficiencies for years after the implementation. Moreover, the cost of quality likely increases each time a decision is delayed to a subsequent phase of the project.
The value of an effective data management strategy increases with the volume of the data (e.g., master, transactional, and analytical data), the ranges of use for the data, and the complexity of the business processes. In fact, the more business units, systems, and functions that use the data, the more critical it is that the data be accurate and consistent. Knowing this, how does an organization design an effective master data management (MDM) strategy? A very effective answer is to use a multi-disciplinary approach that involves master data identification, a data maintenance organization, clearly defined data standards, data governance, and overall data ownership.
Determining what data should be managed as enterprise master data is a critical first step in the MDM approach. Criteria for identifying master data includes, but should not be not limited to, determining if data is: shared across systems and business processes, required for regulatory compliance, a source of competitive advantage, or considered high risk due to poor data quality. Performing this assessment and establishing the criteria for master data must be based on an understanding of the strategic goals of the business as well as a detailed understanding of the entire business model, including product creation, services rendered, financial processing techniques, customer and vendor identification, and human resource management. It is important to note that data management cannot be considered merely an IT issue. In fact, to achieve effective data management, you need to treat it as a business issue with proper visibility, functional support, and accountability for quality.
First, the master data, or data that is created once and used across the organization’s key operational business processes, must be defined. Master data is essentially the reference data for all key entities within an organization, including customers, employees, products, and suppliers. The goal should be to have master data fit for the purpose at time of its use, where:
- “Fit for the purpose…” means:
- Meets requirements of all processes that use it
- Enables flawless execution of those processes
- “…at time of its use” means:
- Timeliness and quality
- MDM can be measured on quality and service levels
After identifying data that is fundamental to operating the business in a multi-system landscape, the data definition must be created. This process begs the following questions:
- What are the global, regional, and local data elements?
- What is the data lineage?
- Where is the data accessed, maintained, or manipulated?
- Who is responsible for data maintenance?
When determining the global, regional, and local data elements, the business must have clarity on how the data is created and how it will be used. You need to maintain global data across the landscape, and therefore, the business must employ an architecture that can support tight integration. In fact, depending on the number of systems using the data and the downstream processes the master data affects, it may be necessary to create a central data repository. In an SAP environment, most master data objects are created and configured in SAP ERP Central Component (SAP ECC) with ample reference data for the key data entities. However, to provide seamless integration, you also need to maintain cross references for the data objects to other legacy systems in the central data repository. SAP NetWeaver enables this process integration in an SAP environment across multiple systems (including MDM and ERP) using service-oriented architecture (SOA) concepts.
Regional and local data elements may very well be equally important to an effectively run business, but they require less integration at the enterprise level. Though these objects often inherit various parameters from the established master data, they typically remain resident on a particular system within the landscape.
Understanding the multiple data elements is a foundational piece of designing the overall data architecture. Architecting the data landscape requires an understanding of how data is provided to the central repository, rate of growth, data query needs, and data quality management. Given the criticality of corporate data and the frequent interaction that undoubtedly takes place, the central repository must be highly integrated, consistent, and organized. Unfortunately, no one-size-fits-all approach exists to defining data architecture for an organization. Indeed, there are four common architectural styles that provide different capabilities depending on the needs of the business: consolidation, registry, coexistence, and transaction. See Table 1 for the key characteristics of each.

Table 1
Common data architecture approaches
Regardless of what data architecture style is selected as a best fit for an organization, a landscape must be capable of carrying out some common competencies. To effectively orchestrate data management throughout the data life cycle, the data repository must be:
- Scalable: Data inevitably grows over time. The repository should be able to extend existing profiles to new data sets with ease. It should also be able to house data from multiple systems under similar structures in a fashion that is transparent to the end user.
- Repeatable: A repository is of little value (and poorly maintained) if it returns seemingly random results when queried. Query results should be predictable and methodically defined to give users an accurate picture.
- Reusable: Data is often used by multiple stakeholders and should not be immediately consumed. The system must allow for seamless data manipulation and easy duplication.
- Readily available: In today’s business environment, users expect quick turnaround when transacting with data. The system must be able to provide more or less immediate feedback around the clock, while making considerations for issues such as conversion routing and system backups.
As the global data variables, the overall set of master data, and the data landscape are defined, the fine balance between operational efficiency and business process control must be considered. It is often assumed that implementing better data management practices leads to improved operating speed. Though you can realize a multitude of efficiencies, control does not necessarily equal speed. For example, a business may be processing thousands of documents at an acceptable rate, but the documents may not be inheriting the proper global data attributes. Implementing more stringent controls over global data undoubtedly makes the business more effective, but it is unlikely it will realize any time savings at the outset of a project. Therefore, you should conduct a comprehensive cost/benefit analysis when determining the master data elements.
Once the master data scope has been defined, the architect of the overall process design can begin. The design must have clearly defined inputs and outputs. It must detail the triggers for each major business process, how the data will move through the landscape, and the systems the data will touch. If the process is designed well, it should be rather easy to follow and should be able to be executed independently of automated programs. Each potential point of failure as the data moves from one system to another should be clearly defined and errors must be identified and resolved in a timely manner. Though the actions that need to take place vary in each business setting, the point remains the same: A well-constructed process design allows data to move throughout the landscape smoothly with any exceptions being immediately identified and corrected.
Establish MDM Processes and Standards
After gaining an understanding of the business processes, the MDM processes and standards can be created. The first step is to identify and understand the data, roles, systems, and end-to-end workflows that will be used to create, update, and eventually retire master data. This involves creating an enterprise-wide definition of master data entities, establishing the proper system of maintenance, creating a cross-system field map, and establishing clear data maintenance policies. Next, you need to identify the system users who will be involved with data maintenance and create applicable roles.
Effective data management in ERP implementations relies on an established ERP organization model. The ERP organization model affects the performance of business operations by exploring:
- How data is defined in the system (including master and transaction data)
- The complexity of data input (a driver of process efficiency)
- The size of master files and analytical data objects
- How ERP functionality meets the business requirements
- How cross-company processing takes place
- How reporting is accomplished (another driver of process efficiency)
Figure 3 provides a view of the major components of the ERP organization model and the relationships among them.
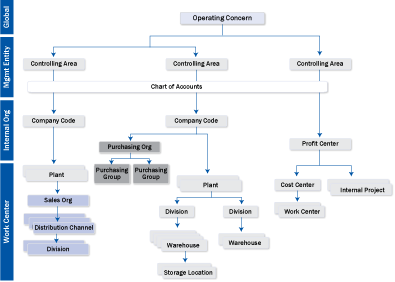
Figure 3
Components of an ERP organization model
Designing and preparing the master data for an ERP system tends to be a major challenge when merging multiple businesses. Identifying the level of data and design commonality is critical as it:
- Drives the more tactical implications of migrating processes to shared services
- Contributes to the ERP landscape decision (i.e., the decision on how many instances and how many systems in each instance)
- Contributes to shared services organization design
- Establishes clear and consistent data and design ownership
- Clarifies and quantifies the business and IT work efforts for the implementation projects
- Identifies key integration areas for all projects
After assisting in ERP implementations covering 15 years, we have found that every organization implementing ERP systems has at least one master data type that poses a significant challenge and drives a disproportionately high percentage of project costs. Often, one or more of the following statements about these projects are true:
- The ERP implementation project is the first time the organization has had to tightly integrate its data across business processes
- Going into the project, there was a lack of awareness, or misperception about the quality and consistency of existing data used in the enterprise
- The project sponsors and planners set objectives and milestones without sufficient analysis of the data design and preparation efforts
- The organization’s functional managers (e.g., finance, procurement, human resources) and business leaders are not accustomed to working together on data design and preparation
To illustrate this, we will consider the example of the customer organizational hierarchy and the customer master. The company wants to have a single definition for customer in its data warehouse to support marketing, sales, distribution, and customer service planning and reporting. The design of the customer hierarchy and customer master will set the foundation, but three different definitions are provided by well-respected business experts and are accurate within that business expert’s area.
A merged definition needs to be developed, using the information from all three business experts, and then design working sessions need to be conducted with all key stakeholders. Merged definition means that unique terms in each definition are identified and are incorporated into one definition.
If the right stakeholders are involved, the outcome of this effort should be a single, integrated definition of customer that can be used to define the customer hierarchy and customer master in the system. The next challenge is implementing that design. If machine-stored customer data already exists in one or more tables in each business area, then there is a dual problem of combining data (i.e., rows) as well as combining definitions (i.e., columns). This should lead to data cleansing and overall data governance activities.
Develop an Enterprise Data Governance Model
Developing a sound enterprise data governance model is possibly the most important component in an effective MDM strategy. In fact, without a strongly supported data governance model, it is likely the benefits of understanding the master data scope and defining the maintenance policies will never be realized. Data governance promotes the use of controls, policies, standards, and management practices to produce, consume, and manage information in a production environment. As such, the approach for defining a data governance model involves two major activities: establishing the standards, controls, and policies used for data management and operationalizing the data management roles, processes, and methods.
An important step in defining the design and controls is to establish the roles and responsibilities of the governance team. Data governance teams typically have five key participants who must be committed to their involvement with the program and understand the interactions that need to take place to make the governance model a success. Figure 4 captures the main responsibilities of the governance team and the interactions required between the key players to enable sound governance processes.

Figure 4
Data governance team’s roles and responsibilities
The data governance team must not only define policies and standards but also oversee the compliance in adhering to these standards over time throughout the organization. Given the number of users that typically interact with data on a regular basis, it is no surprise that defining appropriate and realistic data policies is no small task. The data governance team must make the following concepts a reality in its business landscape to be successful:
- Data standards must be enterprise wide: As we have mentioned, you need to establish and maintain a common definition for master data. Global data must use common nomenclature for free-entry attributes and have standardized value codes. This becomes increasingly important as the number of active applications interacting with master data grows.
- Data security must accommodate needs of multiple stakeholder groups: More often than not, multiple user groups need access to data and the team that owns the data creation might not be the same team that maintains it down the line.
- Data maintenance policies must tightly monitor the points of entry for data modification to eliminate data inconsistencies: This becomes especially important if data resides in multiple systems.
- Data quality processes must be consistent across the application landscape: All systems interacting with master data can contribute to its degradation and therefore, quality must extend into every arm of the business.
Once the data standards are established, the governance model and process provide an organized system to add new standards, resolve conflicts, and keep the standards refreshed on an ongoing basis. Ideally, this will enable the business to increase consistency across business applications and units, increase ownership and accountability for master data, bolster process efficiency and consistency in creating data, and improve conflict resolution in the application of data standards.
Sustain Effective Data Management with Governance Processes and Practices
To operationalize data governance practices, you need to capture requirements throughout the course of developing the design of critical business processes, data cleansing rules, and conversion and migration methods. This allows for the resulting data governance practices to be designed in accordance with the true realities of the business and should make it easier to comply with the governance policies that prevent the degradation of data after go-live. This begs the question of when data governance practices should be put in place. In a production environment, data degradation can happen almost immediately when active users are in the system. Therefore, data governance policies should be followed at all times. Executive level commitment can help keep instituting and sustaining data governance a top priority.
Once the data management structure has been defined, businesses still face a mammoth task of integrating business processes, performing actual data quality assessments, and beginning data cleansing activities. To implement an effective data quality process, efforts should be focused on the areas of highest risk to the business and on quality analysis for all business processes that create, maintain, and use data. This should lead to developing a data quality framework involving data assessment, remediation efforts, and a comprehensive data validation program.
Developing the framework begins with a comprehensive risk assessment to gain an understanding of the operational, compliance, and implementation risks that may affect various data objects and source systems. This should help the business better understand the extent of data remediation activities that need to take place. Next, you need to identify data quality issues according to not only the business rules defined by a particular organization, but also according to any industry or government standards that have been put in place. You need to consider several dimensions of data quality: data duplication, data correctness, data completeness, data format, business rule relevance, data definition consistency, and referential integrity.
After any issues have been identified, data remediation efforts must begin. Data remediation involves data cleansing (i.e., addressing specific data quality issues) and data enrichment (i.e., supplementing existing data with additional information to create a more complete data set). Remediation practices should be focused on understanding the root cause for quality issues and developing a sustainable solution rather than developing ad hoc solutions for individual issues. This is particularly true during an upgrade process, as data migration from one system to another can often lead to data quality concerns. In most cases, the data originating from legacy systems, or any system for that matter, are plagued with data issues resulting from poor data stewardship in past years. Before migrating data, you need to make sure you cleanse data and resolve potential quality and accuracy issues.
Finally, a comprehensive data validation effort must take place. To do this, an independent resource must validate that the conversion was accurately performed by comparing the source and target systems’ data. Following the initial conversion and remediation activities, how do you sustain data quality throughout the data life cycle? The business must be dedicated to creating an ongoing monitoring process that validates the data against the same business rules involved in the early data quality issue identification process. If the data quality efforts are not sustained, the initial benefits obtained from data cleansing and remediation are effectively reduced to nothing.
Information Life Cycle Management
Once a system has been fully operational and the business is satisfied with the data quality across the enterprise, does the need for effective data management diminish? Not at all – in fact, information life cycle management (ILM) is an important data storage strategy that should set specific policies around how data is stored, migrated, and retrieved at various points in the data life cycle. It should essentially balance the costs of accessing data and storing it away while also creating major IT efficiencies for the business.
At first glance, it may seem that a comprehensive and sustainable strategy is not warranted for accessing and protecting data that is no longer actively used in operational transactions. In reality, an ILM policy is critical to long-term business strategy and must be considered early on in an implementation life cycle. It can help make sure data is available when it is needed and at the proper cost, help maintain regulatory compliance, and can help increase overall system performance by freeing up critical capacity as the business expands. If the issue of data storage is simply ignored until system performance degrades or regulatory drivers force an upgrade, the business would be required to build a quick-fix solution that could significantly impact long-term application maintenance and support.
Data archiving is essential to an effective ILM strategy for performance, regulatory, and retention purposes. By definition, archiving involves the physical removal of transactional data from the production database and the eventual storage of that data in a non-production environment or data device. In some cases, the data removed during an archiving session may no longer need to be accessible, but in most cases, the majority of the data must remain available.
The archiving process involves creating archive files according to business-driven criteria, storing the data files in an offline system, and running a deletion program to remove the data from the production database. To archive the right data correctly, the business must identify statutory requirements related to the particular data set (e.g., for tax, government compliance, and audit purposes) as well as the critical success factors in their unique business environment. Success factors can vary widely depending on the organization and the industry. For example, a business in the health care industry may need to keep past customer records accessible, but may archive the transactional data around customer care after a five-year period. On the contrary, a business in the aeronautics and defense industry may have the most data growth around supplier records, but, due to the length of a typical contract, the archiving window may be greater than 25 years.
This raises the question: Is it ever appropriate to purge the data altogether? In some cases, full data purge (or the permanent deletion of transactional data from the production system) is appropriate. The process for purging data is essentially the same as data archiving with the exception that there is no actual writing and storing an archive file.
The purpose of archiving data is, of course, to allow future retrieval while not unnecessarily consuming system resources. Thus, the business must define a method to retrieve data as well as a sustainable strategy around data storage optimization as part of their overall ILM strategy. SAP, for example, provides some simple indexing and viewing tools for accessing archived data via ArchiveLink, but many businesses choose to use third-party solutions as well.
Data storage optimization uses a tiered data structure, where each tier is governed by specific policies as to how the data is stored and retrieved. To enable policy-based storage, the business must be able to classify data sets, understand the storage management systems, and maintain the metadata used to assign classification information. They also must be able to define the appropriate availability levels or service level agreements of the data at each data tier. Service level agreements are typically devised between the IT organization and the end user functional managers.
The question then becomes, what are the accessibility needs for certain data sets? In a typical ILM scenario, three main categories exist, all of which may require different technologies or storage mediums:
- The first tier of storage consists of data critical to the operation of standard business functions. This data must be online and active in your production system as it is used for everyday transactions that keep the business running.
- The next tier holds the near-line data, or data that is periodically used for reporting purposes or trending analysis, but is less critical to day-to-day operations.
- The third tier holds archived data that the business elected to extract from the production system and store on an offline system or device. Though this data is accessed rarely, it is critical that the business maintain it for regulatory and reference purposes.
Once a tiered data structure is put in place, the business must continually work to optimize data movements while striving to provide the necessary access at the lowest cost. This requires commitment from both the IT organization as well as the business management group. On the software side, IT managers should attempt to automate repetitive processes such as migration, backups, and archiving as much as possible to reduce overall costs. This allows for optimizing the storage space by having programs directly write the data to the proper platform. From a business perspective, managers must identify what data is truly needed and realize that some (allowable) compromise in data availability needs to occur to control costs.
Gerry Miller
Gerry Miller, a retired principal from Deloitte Consulting LLP, is a leader in the SAP technology sector and specializes in leading technology strategy and architecture and comprehensive shared services. He has 25 years of experience advising organizations on complex performance improvement initiatives, IT shared services, enterprise applications implementation and support, data management, and business intelligence. He has helped numerous organizations in their efforts to develop their data and IT strategies, improve their management effectiveness, complete business intelligence implementations, and implement shared services. Gerry holds a Ph.D in economics and holds CMA, CIRM, PMP, and Six Sigma green belt professional certifications.
You may contact the author at
gmiller@deloitteretired.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.

Darwin Deano
Darwin Deano is a senior manager with Deloitte Consulting LLP with more than 12 years of global systems integration experience in providing services in support of the implementation of SAP across North America, Europe, and Asia Pacific for manufacturing consumer products and financial services clients. He specializes in services that support integration leadership for global SAP projects, enterprise architecture, business process management, integration, and data management. He has broad experience, knowledge and skills with SAP technology and has a substantial process orientation in procurement, logistics, and sales. He has contributed thought leadership on service-oriented architecture and participated in the SAP Design Partner Council that helped to design and develop SAP NetWeaver business processes. You may contact Darwin via email at ddeano@deloitte.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.
Lindsey Berckman
Lindsey Berckman is a consultant with Deloitte Consulting LLP with specific experience in services that support ABAP development, SAP data archiving, and SAP Interactive Forms by Adobe. She has also provided services in support of supply chain strategy development, technical development for large SAP implementations, and research in data management for SAP ERP. Thus far, her project experience has been focused in manufacturing and aerospace & defense.
You may contact the author at
liberckman@deloitte.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.








