Akash Kumar reviews the tools and techniques that allow you to maximize the use of SAP NetWeaver Application Server for ABAP powered by SAP HANA.
Key Concept
ABAP code performs data-intensive operations at the application layer and stores data in rows for aggregation functions, which can slow processing. ABAP on SAP HANA offers the opportunity to develop new, faster processing and innovative business applications, and optimize existing ABAP applications for faster decision making or services.
SAP HANA allows you to store data in row and column formats, which results in tremendous performance for the SAP NetWeaver Application Server for ABAP. Tables used for aggregation functions such as sum can be stored in a column format in SAP HANA, which until now was not possible in a classic database.
The column store option provides advantages such as data partitioning in which column data is split up for parallel processing by multiple CPU cores. Both data partitioning and parallel processing increase execution speed.
Generally ABAP programmers fetch a lot of data from database tables and store it in internal tables for further business processing. Once the processing is complete the data is written back to database tables. This increases data transfers between the layers and hence reduces performance.
SAP HANA allows you to push data-intensive logic to the database layer, which in ABAP is handled in the application layer
(Figure 1). This helps to reduce the amount of data transferred between the layers.

Figure 1
Comparison of classic database and SAP HANA database (Source: SAP)
Initially the performance bottleneck was from disk to main memory but now it has shifted to CPU cache and main memory. ABAP on SAP HANA allows you to do things that are not possible in traditional databases.
With SAP HANA, developers should now first calculate and then take the results to the application layer. They can avoid the movement of a large volume of data. You can make use of the SAP HANA database for ABAP in the following ways (
Figure 2):
- SAP HANA as a primary database (new applications). With SAP NetWeaver Application Server ABAP 7.4, you can migrate or create new applications on SAP HANA as the primary database. The existing code can also be optimized for SAP HANA.
- SAP HANA as a secondary database (custom accelerators). Applications that are slow and performance-intensive can be moved to SAP HANA. SAP HANA stores massive amounts of data in both row and column formats for online transaction processing (OLTP) and online analytical processing (OLAP) applications. OLAP application data is stored in a column store whereas OLTP stores it in rows. This accelerates the execution of existing applications. Custom accelerators are available from SAP NetWeaver Application Server ABAP 7.0 onward.

Figure 2
SAP HANA database for ABAP applications (Source: SAP)
- Reduce time of background jobs by moving them to SAP HANA
- Move performance-intensive or complex calculation reports to SAP HANA
- Move background jobs to dialog processing as execution time is reduced
The movement of ABAP code in ABAP for SAP HANA occurs in two steps (
Figure 3):
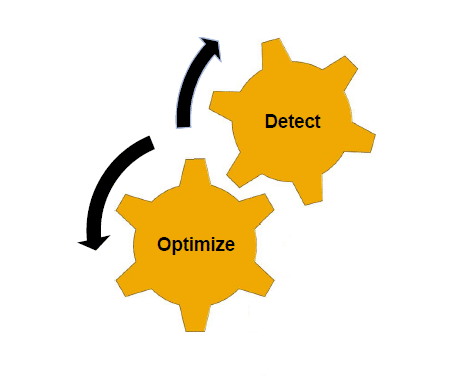
Figure 3
Steps to move ABAP code in ABAP for SAP HANA
Step 1. Detect
The main task for ABAP on SAP HANA developers is to identify the loopholes or code sections in the existing ABAP code. The identified code is then optimized for ABAP on SAP HANA. Migration to SAP HANA is just like any other database migration.
Some of the confirmed scenarios of code optimization are:
- If the existing code makes use of native SQL then the code has to be checked and adapted
- If the existing code has database hints then it has to be checked and adapted
- Nested select and loop statements in the code must be moved to the database layer
- Programs that have a high input/output (I/O) read (as data is not buffered for tables) have to be checked and adapted
- Check for secondary indexes in tables as they are now only required for highly selective queries on non-primary fields. The trivial secondary indexes can be removed.
- The majority of physical pool and cluster tables are changed to transparent tables in SAP HANA so the access and implicit sorting have to be checked and adapted
- Programs that access a large number of records using non-indexed fields have to be checked and adapted
- Programs that aggregate a large number of record for analysis can be pushed to the database for increased performance
There is a maximum probability that code snippets that work on classic ABAP also will work for ABAP on SAP HANA. However, if ABAP performance recommendations were not followed then code has to be rewritten for SAP HANA.
The tools that help to identify the code that needs to be rewritten for SAP HANA are as follows:
- ABAP Trace (SAT) helps to measure and compare run time consumption
- SQL Trace (ST05) helps to do in-depth analyses of database access. Some of the points to analyze are select queries that take a long time to fetch data, programs in which the same database table has been accessed multiple times from select queries, and queries for which all the important conditions are not mentioned and thus a large data volume is fetched from database.
- Code Inspector (SCI) and ABAP Test Cockpit help to locate performance leaks and identify possibilities for optimization. They perform a range of static performance checks.
- SQL monitor allows you to access the kernel logs that have information about database access. It can be executed in the production system for a defined period to identify the most used programs.
- SQL performance worklist combines SQL monitor run time data with ABAP code analysis to plan optimizations. The optimization planning is a process of creating a priority list based on the cost and benefit of optimization. The code changes that are more beneficial are taken as a priority. For example, a program that is executed daily and that requires code changes for SAP HANA is given priority over a program that is seldom executed.
You can find more details in SAP Note 1785057.
Step 2. Optimize
- Select as few fields as possible, especially from tables
- Minimize the amount of database access and transferred data
Code optimization can be done either by a bottom-up or top-down approach. Both concepts follow the code push-down mechanism. Code push-down means moving data-intensive operations to the database layer. SAP HANA can then make use of features such as parallelism, multicore processors, and optimized data storage. This also reduces the load on the application layer (
Figure 4).
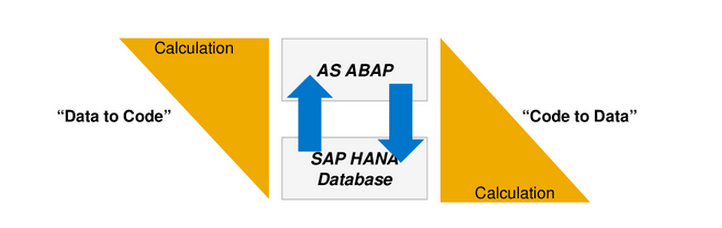
Figure 4
Code push-down mechanism
Bottom-Up Approach
In a bottom-up approach the objects of SAP HANA are consumed in SAP ABAP. The SAP HANA objects in ABAP are consumed using native SQL for SAP NetWeaver Application Server releases before 7.4 SP02 (
Figure 5). Consuming all the objects and their calculation logic by native SQL is complicated and code is also hard to maintain. This approach limits code reusability.
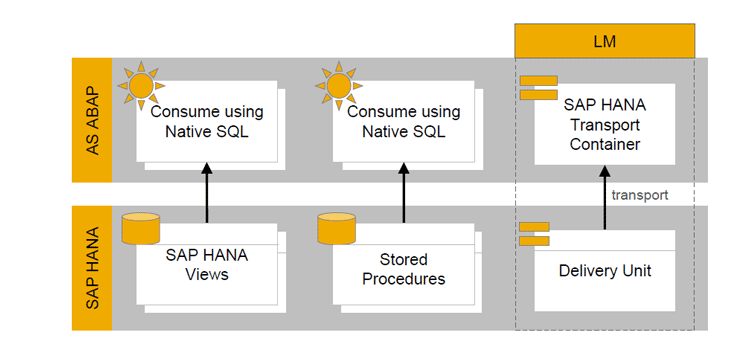
Figure 5
Bottom-up approach with ABAP<7.4>7.4>
An alternative approach was then implemented to overcome the limitation of SP02
(Figure 6). The SAP HANA objects such as views and stored procedures are consumed in ABAP by creating external views and a database proxy. Now objects are present both in SAP HANA and ABAP so extra care is taken while transporting them to follow-on systems.
Both the objects have to be present in the follow-up system for proper functioning. If one of the objects is not present then you get a dump. The solution to the problem is that SAP HANA objects can be transported to the follow-up system before or with the ABAP code. This life cycle management task is achieved using the SAP HANA Transport Container.
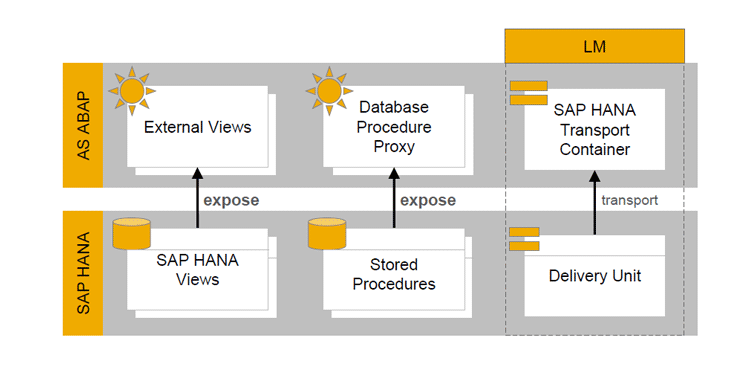
Figure 6
Bottom-up approach with ABAP 7.4> SP02
Transporting both SAP HANA and ABAP objects is cumbersome and requires a developer to have access to the database layer. To overcome the limitation mentioned above (e.g., transport failure), the top-down approach was released in SAP NetWeaver Application Server ABAP 7.4 SP05.
Top-Down Approach
In the top-down approach, all the objects are ABAP managed. There is no requirement for transport of SAP HANA objects. It removes the dependency of ABAP objects on SAP HANA objects.
Figure 7 shows the top-down approach with ABAP 7.4 SP05. LM is SAP HANA life cycle management. It enables developers to send objects from one system to another. Core Data Services (CDS) allows developers to define and consume views created in SAP HANA. The views are created in the SAP HANA database and not on the ABAP server.

Figure 7
Top-down approach with ABAP 7.4 SP05
Code Optimization with the Bottom-up Technique
Now that I have explained the two techniques I go into more detail about the bottom-up approach.
Secondary Database Connection
When SAP HANA is used as a secondary database then you have to explicitly mention the name of the secondary database connection. For example, the Basis team has connected SAP HANA as a secondary database by the name HANASECONDARY. The select query has the keyword connection to connect to the secondary database (
Figure 8). The select query in
Figure 8 shows how to fetch the data from table IT_employee when SAP HANA is used as secondary database.

Figure 8
Fetch data from SAP HANA as a secondary database (Open SQL)
Native SQL for SAP HANA
SAP released new syntax and features for Open SQL from SAP NetWeaver 7.4 SP05. This is also called Native SQL for SAP HANA. Native SQL is used to connect to SAP HANA views and procedures to ABAP. There is no syntax check for Native SQL and errors are found at run time. Some of the differences and new features present in Native SQL and not in standard open SQL are:
- The columns are separated by commas
- Client handling is not automatic
- Table buffering is not present
- There is no keyword “for all entries” and “into corresponding” field
- Supports conditional expressions (Figure 9)
- Supports arithmetic and string expressions such as (+, - , *, MOD, &&)
- The number of joins and sub queries are increased to 50
- Use of ABAP variables escaped with @

Figure 9
Fetch data from the SAP HANA database (Native SQL) with conditional expressions
ABAP Database Connectivity
Native SQL is used with ABAP database connectivity to connect to the SAP HANA database. ABAP database connectivity provides three main classes for connection (
Figure 10):
- CL_SQL_CONNECTION – Selects the database connection
- CL_SQL_STATEMENT – Creates a statement object for SQL query
- CL_SQL_RESULT_SET – Accesses the result set
The code works by the following process:
- Create a secondary database connection by calling method get_connection()
- Create a select query in text format
- Execute the native SQL query by calling method execute_query () and store the result set.
- Don’t forget to close the connection once the data is fetched from database table
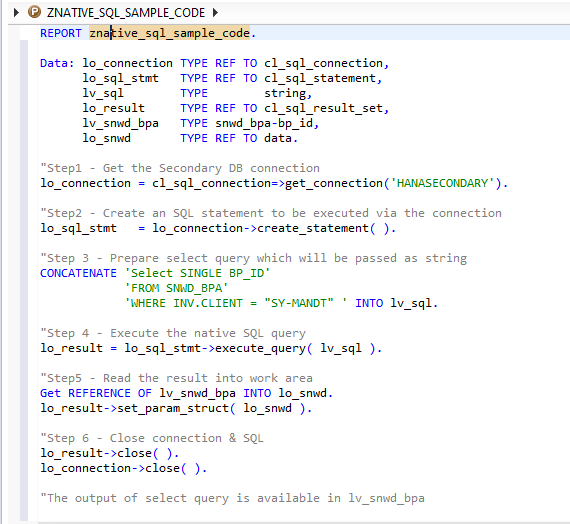
Figure 10
Code to fetch data from the SAP HANA database






