/Project Management/HANA
SAPexperts/Project Management
SAP HANA has a number of data provisioning tools. Step through the detail of SAP Landscape Transformation, Direct Extractor Connection, and SAP Data Services. Learn how these tools can be engaged to load HANA for different use cases and critical implementation steps.
Key Concept
SAP HANA is a data-source-agnostic tool. It can handle many different data provisioning tools that you can use to load data to be analyzed.
SAP HANA is a data-source-agnostic database that facilitates a large volume of data storage. The data-agnonstic capability presents the opportunity to engage a number of data provisioning tools seamlessly with a range of data transformation capabilities. A single HANA instance can simultaneously source more than one data provisioning tool and provide the ability to combine data from multiple sources into a single HANA view. The ability to merge large amounts of data in HANA provides a broader information capability and results in a more effective decision-making tool.
I have personal experience with many companies that have effectively engaged more than one data provisioning tool while maintaining a secured, synchronized, and robust SAP HANA environment. I’ll illustrate the technical architecture of three data provisioning tools and the criteria for selecting the right tool for your needs. I'll focus on three data provisioning tools:
- SAP Landscape Transformation (SLT)
- SAP Data Services
- Direct Extractor Connection (DXC)
Note
Other than these three widely used data provisioning tools, you can also consider loading flat files by SAP HANA Studio or through the operating system level using Python scripts and SQL script uploads. These two options can be used as one-time activities or for test data loads.
Let’s begin with an architecture diagram that provides an overview of the above-mentioned tools connecting with HANA (
Figure 1).
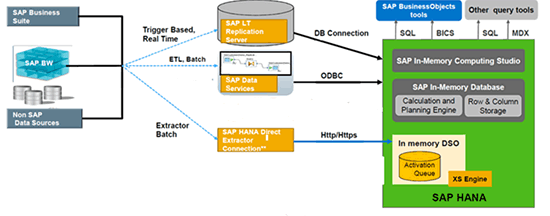
Figure 1
SAP HANA architecture (source: SAP)
The left side of this diagram shows possible source systems — SAP ERP, SAP NetWeaver Business Warehouse, and non-SAP systems — while the center of the diagram reflects the data provisioning tools SLT, SAP Data Services, and DXC. Each provisioning tool uses a different method to connect with HANA. SLT uses DBconnect because HANA is a database, Data Services uses an ODBC connection, and DXC uses an HTTP connection. DXC connects HANA via the XSEngine, which is the Web application component in HANA. I’ll discuss further details concerning the various connection types and the logic behind them later in this article.
SAP Landscape Transformation Server
SLT allows for real-time data replication from SAP and non-SAP sources into HANA. SLT also has the capability to load data in batch mode. The SLT batch mode can be set up for SAP and non-SAP source systems; this feature enables streamlining of data into HANA in a controlled manner. One of the added benefits of SLT is its transformation capability. You can configure SLT to handle transformations, such as masking of a file, adding or removing table structures, and skipping certain records. It can also be used for calculation.
Users with existing SAP enterprise systems tend to use the SLT as their primary data provisioning tool for HANA data loads. SLT is a native SAP tool that has been highly integrated with SAP systems, making SLT a favored option over other provisioning tools. Another reason for its high adoption is that the learning curve to adapt SLT is short. SLT is an SAP NetWeaver system and requires similar skills as any other SAP NetWeaver system.
You can configure SLT in three different ways:
- Add-on to source system
- Add-on to Solution Manager
- Standalone system
Option three (standalone system) is optimal for production instances. In addition, separate instances are beneficial for reasons of maintenance and hardware use. Options one and two can be used for non-production environments to reduce the system support and hardware considerations.
SLT has the flexibility to support single or multi-source and target systems. In other words, you can configure SLT to source more than one system and can set it up to load more than one HANA instance or schema without affecting the independent deltas.
Figure 2 shows different installation options. Option one is to configure SLTs within the source system. Option two is to have a mixed SLT scenario for a non-SAP source system. This requires a dedicated SLT, and for the SAP source system, SLT configured as a standalone system. The right side of
Figure 2 depicts a dedicated SLT configured to handle SAP and non-SAP source systems to load multiple HANA instances. Note that a single HANA instance could have more than one schema or multiple separate HANA instances; in both scenarios the SLT can load data in parallel.
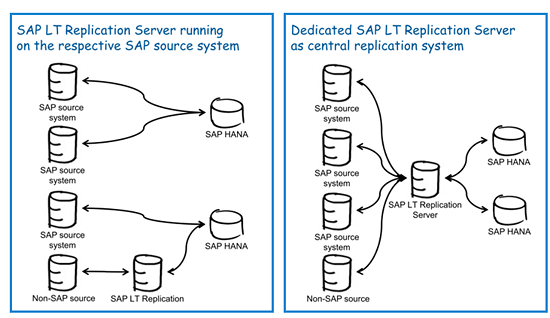
Figure 2
SLT installation options (source: SAP)
Figure 3 shows different ways to configure SLT with multiple HANA targets. Each target can have its own scheduler and delta handling methods without interfering with the loads. Excepting the third scenario, each load scenario has separate security and control parameters. Schemas in HANA are folder structures that store the data. You can create a schema in HANA either via a SQL statement from SLT configuration (transaction code LTR), or through a context menu in the HANA Studio. The schema is associated with a dedicated user ID that controls access to objects within the schema or the ability to grant access to other IDs. The system ID does not automatically inherit access to new schemas unless the schema owner explicitly grants such access. Schema owners also need to grant explicit access to the SYS_REPO user to be able to preview or see data from the tables. While configuring the SLT schema, the owner ID is generated in HANA. Along with the ID and schema, standard roles are created (prefixed with the schema name) with required privileges to load.

Figure 3
SLT schema mapping options (source: SAP)
SLT has been evolving in its transformation capabilities. With the current version of SLT the user can perform varied data transformations, for example, adding or removing a column or skipping certain records based on explicit conditions. The user can also perform calculations. These transformations can be accomplished with a user-friendly GUI on a specific table or can be achieved by calling an ABAP program at runtime. There are certain transformations (such as filtering certain types of records) that can be performed at a trigger level in the source system, which reduces the number of records transferred. However, this transformation is applied to delta records because it is related to triggers that are only called in with delta records. SLT’s evolution should be considered when implementing HANA. The HANA enterprise version of its license model includes SLT. Furthermore, SLT is an SAP NetWeaver platform. It requires only the same support as any other SAP NetWeaver-based platform, with minimal training.
SAP Data Services
Data Services is an ETL tool designed to support complex, batch-based ETL data. It can be adapted within the HANA landscape and connections can be configured from HANA Studio as a native provisioning tool. Data Services is positioned for batch load-based data replication from non-SAP sources and SAP sources (with complex ETL requirements). You can also use it as a scheduling tool for calling HANA's stored procedures. The newer version of Data Services, 4.1, is a highly integrated tool that enables schema and table data definition management within Data Services. It also eliminates certain setup procedures.
You can connect Data Services through:
- Remote Function Call (RFC) connection. An RFC connection is a relatively quick way to connect and extract data from the ERP system. Tables with a smaller data connection might be better options in terms of performance and usability. The RFC connection has a limit of 512 bytes per record.
- ABAP workflow. For tables that have large amounts of data, or when it is necessary to load multiple tables, SAP has developed ABAP workflow. ABAP workflow enables these bulk file-based extractions.
- Operational Data Provider — ODP DataSource. The ODP method enables the reuse of existing BW extractors. This method enables the extraction of complex data in highly denormalized forms of operational data, such as billing document details. You can enable ODP for custom extractors as well as for specific standard extractors.
- SAP NetWeaver BW: You can enable SAP NetWeaver BW InfoProviders as a source via the Open Hub method. To maintain integrity and consistency, InfoProvider tables cannot be accessed to Data Services directly. Open Hub does not require additional licensing as long as the data is sourced for HANA or any other SAP systems.
- Non-SAP systems: For non-SAP systems, the Data Services connection is made directly to the database via the appropriate driver.
With the recent release of Data Services, the integration with HANA has become tighter in terms of design and run-time activities. Aside from this, Data Services can use HANA as its own repository, therefore avoiding another database. With design-time integration, users can import tables from the source system and directly generate tables into HANA from the designer.
The runtime environment of Data Services has load monitors with visual graphs to compare load performance in HANA. In addition, the bulk load method enables Data Services to load large amounts of data quickly. The bulk load method inserts the records in a HANA staging table rather than into a target table, without comparing the existing records for delta. Once the staging load is complete, the data is migrated into a target table within the HANA environment using HANA speed.
This has resulted in significant performance improvement with high-volume data. Data Services also has the capability to push down database operations (such as table look-up) to HANA. This has also resulted in significant performance improvement. In an environment in which the only requirement is to have Data Services, then the trimmed-down version of BusinessObjects Information Platform Services (IPS) can be configured to support Data Services.
SAP HANA Direct Extractor Connection
DXC is another data acquisition tool designed to use standard and custom SAP extractors. BW extractors provide a quick solution for extracting complex data in normalized form, which in turn enables simpler HANA models and shortened development cycles. Unlike SLT, DXC provides the batch load option with minimal transformation capabilities. However, you can use custom user exits for additional transformations. DXC does not necessitate additional licensing requirements; therefore, it is a more cost-effective method than Data Services or SLT.
DXC Architecture
DXC uses the embedded BW system (which runs within the SAP NetWeaver applications) to enable extraction, which exists inside all SAP NetWeaver 7.0 or higher ABAP-based systems. Embedded BW is used as a data transference tool rather than as a data storage or transformation engine. DXC is used to create InfoPackages and process chains, as well as to monitor and schedule loads through embedded BW. It is not used for data storage. Access to embedded BW is given via transaction code RSA1. This transaction code should be limited to DXC administrators only to prevent a possible security breach. If there is a concern with using embedded BW within the same SAP NetWeaver instance, such as performance impact, you can configure DXC to work with an external BW system in the sidecar approach. The sidecar approach enables the DXC configuration and loads to be isolated from the operational source systems, reducing the risk of potential performance impact.
XSEngine, HANA’s built-in Web service engine, enables DXC for HANA. Therefore, the connection between the source system and HANA is made as an HTTP-type connection. Once the extractor is enabled for DXC, HANA-controlled tables are generated to handle the loads. These tables are called In-Memory DataStore Objects (IMDSOs).
Figures 4 and
5 show illustrations of an embedded BW and sidecar setup.

Figure 4
Embedded BW is being used as a pass-through. This method cannot be used for data transformation or data staging (source: SAP).

Figure 5
The sidecar option, in which an external BW system is being used for DXC pass-through (source: SAP)
The IMDSO is similar to a traditional BW DSO. This enables delta management and sequencing. The IMDSO also follows the same two-step process, namely, loading data into the activation queue table and transferring the activated data into an active version table. You can use the active version table with the HANA data models as a base table. The activation processing is instantaneous and does not require additional steps within HANA. As soon as the activation queue is loaded the activation processing is triggered and the data is transferred to the active version table for reporting. In the event of data failure, the active table has to be reversed prior to removing the entry in the Persistent Staging Area (PSA) table in BW. PSA does not host data, but it does maintain packet entries.
Critical Configuration Steps for DXC
You can find detailed configuration steps in the DXC configuration guide. Here are the major configuration steps that you need to perform prior to successfully using the DXC.
Step 1. Install the appropriate SAP Notes in the ABAP system and Java library in HANA. Both require enabling the DXC interface in ABAP and XSEngine in HANA.
Step 2. Create a schema to maintain and manage IMDSO tables in HANA. You can either use a schema named USER or a generic user for an HTTP connection.
Step 3. Create an HTTP connection between HANA and the ABAP system. Be sure to maintain the RFC connection between either the embedded or sidecar BW system with the ABAP system. The embedded BW requires an RFC connection as well, even though it is part of the ABAP instance.
Step 4. Maintain appropriate entries in table RSADMIN.
Step 5. In addition to the SXC, either embedded BW or the sidecar BW system can be used for multiple purposes. One of the critical entries in RSADMIN is PSA_TO_HDB, which determines how the BW system can be provisioned. You have three options:
- Global. Enables all the DataSources for DXC extracts and makes the DataSources unavailable for data staging within the BW system. In this configuration, the embedded BW or the sidecar becomes a DXC only purpose system.
- System. Only the specified client is restricted for DXC extracts. Others can be sourced for data staging and reporting in the same BW system. In this scenario, the BW is used as a DXC pass-through for client-specific data, and as a reporting system for certain client data.
- Data source. Only the specified DataSources are used for DXC and are not available for data staging. This configuration isolates certain DataSources that are strictly used for DXC.
Again, this setup affects only the BW system that is being used for DXC. Neither the source system nor the rest of the BW environment is affected. For companies with an existing BW system with nightly delta loads, introducing DXC does not affect their delta loads or their reporting BW systems.
Step 6. HANA IMDSOs require keys, and these keys are defined based on the data source. Therefore, prior to activating the data source, the user must set the key fields. This step is required for all data sources to be used as part of the DXC.
Step 7. Create an InfoPackage or process chain for load management.
DXC is a non-disruptive technology, which means it can be implemented without affecting existing BW data loads or the delta queues. Source systems are able to isolate the DXC loads from the rest of the existing BW loads by managing a separate delta queue for DXC. In the event of load failures, the user has to start from HANA by reviewing the log files, BW load monitors (RSMO), and the source system. For companies with SAP that want to increase agility in HANA, DXC may be an economically viable solution.
My experience has shown me that companies with SAP environments in which there is a need for real-time data with minimal transformation tend to use SLT. Companies that need complex transformation or work in a non-SAP landscape with no real-time reporting requirement choose Data Services. Finally, companies that want to avoid building complex HANA models and have the SAP system as the source system most often use DXC. I have also seen companies that have all three data provisioning tools for the same HANA instance feeding data into the same HANA instance, where HANA models are being developed with cross-system tables.
Haran Vinayagalingam
Haran Vinayagalingam is a Practice Lead with SAP’s HANA Services Center of Excellence team. He is a certified HANA architect with experience implementing SAP HANA and SAP BW on HANA for large-scale enterprises. Along with numerous SAP HANA implementation experiences, he is the North American solution-delivery owner for SAP HANA Live.
You may contact the author at
haran.vinayagalingam@sap.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.







