In this exclusive report by Hillary Bliss, take a walk into the world of the SAP suite of predictive tools with an in-depth tour of the new SAP Predictive Analytics 2.0 and how it ties into SAP HANA and SAP Lumira. Learn the importance of general predictive modeling concepts, and then apply those concepts as part of a bigger discussion about the architecture and features of SAP Predictive Analytics. Finally, get an early peek at what’s coming for SAP’s predictive tools in the near future.
Key Concept
A predictive model is an equation, algorithm, or set of rules used to predict an outcome based on input data. Predictive models can simply be a set of business rules based on past observations, but to develop more accurate and statistically rigorous predictions, statistical algorithms for developing the predictive equation are often used.
SAP Predictive Analysis, a precursor to SAP Predictive Analytics Expert Analytics, was introduced to the SAP BusinessObjects BI suite in 2012 and added new functionality to the existing BusinessObjects toolset. Expert Analytics extends the visual intelligence offerings of SAP Lumira to include new predictive functionality powered by both open source R and SAP-written algorithms. Automated Analytics (formerly known as KXEN) was acquired by SAP in September of 2013 and has a loyal user base for its user-friendly but powerful predictive tool.
In this detailed special report, I first provide an overview of the generic predictive modeling process before going into details about the SAP Predictive Analytics 2.0 modeling engines and the software’s features and functionality. I also look at how Expert Analytics integrates with SAP Lumira and SAP HANA and how these tools are expected to evolve and converge in 2015 and beyond.
Note
The next section of this article delves into the core elements behind predictive analytics and modeling. If you are familiar with these concepts, you can jump ahead to the section titled “Predictive Analytics Prerequisites and Skills.”
Predictive Modeling Overview
Predictive models are important because they allow businesses to forecast the outcomes of alternative strategies prior to implementation and help determine how to most effectively allocate scarce resources, such as marketing dollars or labor hours. Common applications for predictive models include:
- Response and uplift models predict which customers are most likely to respond (or incrementally respond) to a marketing prompt (e.g., email, direct mail, or promotion)
- Cross-sell and up-sell models predict which product suggestions are most likely to result in an additional or increased sale to a given customer
- Retention and attrition models predict which customers are most likely to leave or stop purchasing in the near future, and examine what interventions might reduce the likelihood of customers leaving
- Segmentation predicts which customers behave or transact similarly and might respond similarly to marketing or service offers
- Fraud models predict which transactions, claims, and interactions are most likely to be fraudulent or require further review
The common business problems addressed by predictive models are not to be confused with predictive algorithms. Each of the above problems can be solved using a number of different algorithms. Understanding the characteristics of a business problem and marrying data with the most appropriate predictive algorithm is the portion of statistical modeling that is often more art than science.
For example, if a firm wants to predict a simple binary outcome (e.g., will a customer accept an offer), the modeler can employ a decision tree, naive Bayes classifier, or logistic regression model. Each of these prediction methodologies has advantages and disadvantages in terms of ease of implementation, precision, accuracy, and development complexity.
While the value of predictive modeling varies from firm to firm, it is easy to quantify the value of better predicting outcomes. From a marketing perspective, allocating scarce marketing resources to the customers most likely to respond can increase response rates and cut expenses at the same time, often with a return on investment on the order of millions of dollars per year.
Predictive models also allow firms to test multiple proposals in a simulation-type environment to predict outcome revenue rather than relying on gut-feel management when deciding between alternatives. For financial services or insurance firms, better predicting which customers are likely to have a claim or default on a loan allows more accurate pricing of risk and a higher likelihood of attracting the most desirable customers. Similarly, having repeatable, quantifiable business rules for creating these models allows businesses to react to market changes more quickly and rebuild models to reflect changing business environments once a shift is identified.
Typically, firms start developing predictive models for one particular area or department, and quickly identify many opportunities to apply similar applications to other functional areas.
The Flow of Data in the Modeling Process
Figure 1 shows an overview of the flow of data in the modeling process.

Figure 1
The data flow behind predictive modeling
Modeled data from a data warehouse is extracted and often transformed for transfer to the predictive tool. This data transfer occurs through text file exports or direct database connections. In the best situations, the predictive modeling tool is able to access and write data directly back to the data warehouse. Often, the data transfer process is iterative, as the modeling data extract is adjusted and variables are added, deleted, or modified.
Although much emphasis is placed on the software used for prediction, running the predictive algorithms is actually only a small portion of the model-building process. In fact, in marketing materials for its predictive tools, SAP states that generating the predictive models accounts for only 20 percent of the time and effort in the modeling process. Data manipulation, exploration, and implementation take up more resource time than actually creating the model.
Therefore, selecting a modeling tool that incorporates data exploration and manipulation elements, facilitates implementation, and integrates with the original data source means fewer data transfers and faster implementation of the predictive insights.
At a high level, the predictive modeling process consists of the following steps:
Step 1. Identify goals for the predictive model
Step 2. Select an appropriate modeling tool
Step 3. Perform exploratory data analysis and investigate the available data
Step 4. Develop the model (including selecting a predictive algorithm and predictor variables to include in the model and evaluating model fit and accuracy)
Step 5. Implement the selected model
Step 6. Maintain and update the model as needed
Let’s look at these steps in more detail.
Step 1. Identify Goals for the Predictive Model
All business leaders have to face the issues that keep them up at night when considering the future of their company or industry. Identifying ways to turn predictive analytics’ insights into actionable business decisions is often a challenge, as analysts can become overwhelmed with summarizing and examining the available data and may miss opportunities to drive actions that can produce a return on investment to the organization. An analyst, with management support, must identify goals for the analysis and a desired outcome or deliverable. This might include identifying:
- Which customers are most likely to respond to a marketing trigger?
- Which customers might cancel their subscriptions or stop transacting soon?
- Which offers, environments, displays, or other inputs might trigger a higher purchase amount?
- Which customers might have life events that would trigger a purchase?
Answering these questions produces actionable results with a quantifiable return on investment.
Finally, in developing the goals of the analysis, the analytical and management teams must ensure that sufficient data is available to build the models. For example, a company that does not have a customer database can’t develop customer segments or determine which customers are most profitable. An insurance company that wants to build a model to detect fraudulent claims must be able to provide or identify a set of past fraudulent claims. A predictive model is not a magic wand that can pull insights out of thin air; it is simply a system of rules or equations that can synthesize past experiences to determine the most likely future outcomes.
Unfortunately, this part of the process is often ignored and time and effort are squandered when the modelers later determine there is insufficient data to complete the analysis.
While no one tool can select the best business strategy and communicate to the analytical teams the modeling requirements to implement the strategy, easy-to-use data visualization and BI tools can help identify trends and preliminary insights to direct predictive analysis. A healthy BI practice and user-friendly query tools can identify areas for improvement and quickly assess the sufficiency of data for modeling, expediting this first step in the modeling process.
The Data Source
In addition to considering the business goals, this first step must also include a plan for obtaining the data required for the analysis. The datasets used to generate predictive insights are critical to the analytic project’s success. The modeling dataset must not only be constructed carefully, but also be a collaborative effort between the subject-matter experts who understand the data, the technical team members who actually pull and build the datasets, and the analytics team members who consume the data and build models.
In the best situations, the organization has a data warehouse with data from all areas of the company loaded into a central location and in a standard format. Typically, the enterprise BI reporting system (e.g., BusinessObjects) lets business users facilitate reporting and data access. Sometimes, to ensure that data is at the level of detail required for modeling, the modeling extract must be pulled directly from the data warehouse rather than from pre-aggregated reporting marts.
Step 2. Select an Appropriate Modeling Tool
When evaluating predictive tools, modelers should consider several functional areas to ensure a tool meets their needs. The match between the modeling tool’s capabilities and the organizational requirements and budget determines which solution to select. This section summarizes key functional areas to consider during the selection process.
Data Access
As discussed previously, file creation is often the most time-consuming portion of modeling, so ensuring that the modeling tool can access the data is critical to expediting this process. Ask yourself these questions:
- How is modeling data imported into the tool?
- Can databases be accessed directly or must data be transferred exclusively though flat files?
- Can the tool write results or models back to the database?
Data Manipulation
Data manipulation includes binning, grouping, value changes, and calculations on existing data fields. If the model-development process involves evaluating and potentially modifying fields in the database, this functionality may expedite the modeling process rather than having to go back and create a new extract from the source system each time. However, if these modification rules cannot be exported or documented, they have to be re-created in any system that needs to score the model.
System Architecture and Processing Capacity
Some predictive algorithms require significant processing power, often iterating through the data many times to calculate optimal models. As more data becomes available and companies want to analyze big data, ensuring that the predictive tool can process large datasets is critical. Therefore, organizations need to decide between predictive tools that are installed on a user’s local machine and those that can process data on a server. Local client tools are easy to deploy and require no dedicated hardware, but are limited in the amount of data they can process. Server-based tools typically require dedicated hardware and are more complex to install and maintain, but can process Big Data and allow many users to share the same resources.
User Interfaces (UIs)
Predictive tools have vastly different interfaces, varying from user-friendly, drag-and-drop functionality to code-only interfaces. Some tools do not even have an interface and can only run via batch jobs submitted remotely. Tools that are fully code based often offer more functionality and more extensive predictive libraries, but can increase development time and require more technical resources to operate. Graphical user interface (GUI)-based solutions can sometimes be operated by less technical resources and can expedite the model-development process.
Predictive Algorithms
The library of predictive algorithms available in each tool varies. While numerous algorithms exist, most organizations can perform a wide range of analysis with a limited toolset that has a few algorithms for each classification, clustering, regression, and time-series analysis. However, it is important to define the goals or types of models the organization expects to build prior to selecting a tool to ensure that the selected tool has the appropriate functionality. For example, if an organization is purchasing a predictive tool exclusively to develop sales forecasts, it should buy a tool that specializes in that area with special features to accommodate seasonality and periodic events, whereas a company planning to perform customer analysis would want a variety of tools, such as clustering, decision trees, and possibly regression algorithms.
Model Evaluation Features
Evaluating models and comparing alternatives is key to selecting the final model. Tools that assist analysts in comparing alternatives speed the development and selection processes. Model evaluation tools include automated visualizations for things such as lift charts, residual analysis, and confidence intervals on the coefficients and predicted values.
See the sidebar “The Predictive Marketplace” for an overview of predictive tools.
Model Implementation and Maintenance Features
Once a model is selected, most organizations want to deploy it as quickly as possible. Depending on the organizational needs, this may simply be attaching the model score to a small set of data. However, in many instances the organization requires the ability to call the scoring model on demand, which requires writing the scoring algorithm (rather than just the score values) back to the database.
Predictive tools that can publish algorithms back to the database as a stored procedure or function call or be encapsulated in a callable block of code expedite this process. Depending on the complexity of the scoring algorithm, calculating the coefficients and programming the scoring function can be time consuming. Additionally, if the data has been manipulated within the modeling tool, being able to export those rules or include them in the scoring algorithm significantly expedites the implementation process.
The Predictive Marketplace
While the popularity of predictive tools is exploding, software providers are struggling to keep up with increased user demands for data-processing power and increased functionality while maintaining usability. Wikipedia maintains a relatively complete
comparison of statistical packages. Additionally, blogger Robert A. Muenchen has written an article on the
popularity of data analysis software that monitors the use of different tools in the marketplace. His research indicates that the R programming language is one of the top statistical packages used by those performing predictive analytics, and R’s use has been growing rapidly over the past several years.
Commercially available software is more frequently used by business organizations, while open-source software is often used by academics and researchers. However, with the licensing costs of some popular software packages increasing and the influx of recent graduates with experience in open-source languages, many organizations are moving to open-source tools, such as R. I have more to say about R later in this article.
The following is a list of characteristics an organization should consider when selecting a tool for a new analytics venture. Once it
identifies the analytic goals, the organization should determine which tool provides the best match to the project’s needs and the long-term goals of the organization.
Algorithm-Specific Tools
While many tools try to have a full suite of algorithms available, there are several tools available with a narrow focus that attempt to perform one algorithm or one subset of algorithms very well. These tools often offer usability and visualization features that surpass full-function tools, but are only used for one type of algorithm, such as decision trees.
Full-Function Code-Based Tools
The most comprehensive tools, which offer access to the largest range of diagnostic tools and modeling algorithms, generally require users to have in-depth knowledge of both statistics and coding. These tools are often also fully-functional coding languages and, therefore, can be used for all the required data processing and manipulation, and for programming any algorithms that are not already included in the code library. These tools offer significant flexibility in terms of data preparation, predictive algorithms, and model evaluation, but suffer from a lack of usability. They have a high learning curve and it is
difficult to generate visualizations.
Cloud Solutions
The most recent market entrants are offering predictive-in-the-cloud solutions with web-based modeling interfaces, cloud-based data storage and processing, and a pay-per-byte or pay-per-score model for data storage, model building, and prediction.
Step 3. Perform Exploratory Data Analysis and Investigate the Available Data
The data-exploration process involves evaluating all the data elements available for modeling and determining which elements to include in the analysis. This includes examining the distribution of values within an attribute, learning how they relate to the response variable, and evaluating the quality of each attribute. For example, do values look reasonably accurate? For what percentage of the observations is this variable populated? Is the data spread across possible values?
This work may involve building new variables or changing the definitions of existing variables. This exploration process should result in a short list of high-quality predictor variables.
Step 4. Develop the Model
A modeling dataset is often structured differently from the way data is typically stored in a data warehouse or reporting mart. Therefore, much of the time and effort in the modeling process is spent designing, calculating, and testing the data extract. In marketing materials for its predictive tools, SAP indicates that data access and preparation steps account for 36 percent of the total time spent on model development.
In reality, pulling the modeling dataset is an iterative process, and the timeline of the modeling process can be extended significantly if a new file must be imported each time a change needs to be made to a predictor field. Tools that have direct connections to the source data or allow manipulation of the input file within the modeling tool can significantly cut down on the data-preparation portion of the modeling process.
The format of the modeling dataset depends on the desired outcome and the input requirements for the modeling algorithm used. For example, if the goal is to forecast daily sales for Store A, the data must be aggregated to the daily level for only Store A prior to being fed into the predictive algorithm. Similarly, to predict a customer’s likelihood to purchase, the data must be at the customer level—for example, one row per customer, with separate attributes to describe things such as demographic characteristics and the dollar amount of purchases in the last six, 12, and 18 months.
Developing the modeling dataset and determining which variables to include in the model is often an iterative process. For example, does grouping customers ages 15 to 30 together yield as good a prediction as grouping ages 15 to 20, 21 to 25, and 25 to 30? Fitting and re-evaluating the results is much faster if the data changes are performed within the modeling tool, rather than having to return to the database and pull another modeling extract with new variables and then re-import it into the modeling tool.
The model-development process involves iterating through predictor sets, modeling algorithms, and input datasets until an acceptable result is reached. This involves a carefully selected balance between model complexity and accuracy. Model versions are evaluated and compared by scoring the independent validation data, evaluating fit and accuracy metrics compared to the training dataset, and comparing accuracy between predictor sets or modeling algorithms.
Step 5. Implement the Selected Model
Once the analyst and management teams select the final model based on validation performance, business requirements, and industry knowledge, they must make the model form or results available to production applications. The implementation of a model may just involve scoring a fixed set of customers or writing back the sales forecast for next year to the budget database. More commonly, the resultant model scoring algorithm needs to be implemented in the database or a real-time scoring application is needed to determine the predicted result for any data on demand. An example of this is a customer segmentation model in which all new customers need to be assigned to a segment as they are added to the database.
Step 6. Maintain and Update the Model as Needed
Just like any other business rules and targets, predictive models must be maintained and monitored for relevancy and accuracy. Models may degrade over time due to environmental changes, such as shifts in the economy, product changes, or consumer trends. Procedural or data model changes may cause models to become inadequate if a specific piece of data that is used as a predictor is no longer available or becomes less accurate. Therefore, even after a model is implemented and working as expected, it must be monitored regularly to ensure that it is still predicting outcomes accurately and the input data remains relevant.
Also, models periodically need to be re-fit (coefficients re-calculated based on new data) or re-built (re-considering the list of predictors included, changing the definition of input variables, or even using different predictive algorithms). For example, if a company operating only in one state suddenly expands to a new region, a model built on one state’s data may not accurately predict reactions of customers from other states. The model should be re-fit or a new model built on the new region’s data as soon as it is available.
Predictive Analytics Prerequisites and Skills
SAP developed the Expert Analytics tool as an extension of the SAP Lumira code line. Expert Analytics includes all the functionality of SAP Lumira (e.g., data acquisition, manipulation, formulas, visualization tools, and metadata enrichment) with the addition of the Predict tab, which is an additional tab that appears between the Prepare and the Visualize tabs that are part of the standard SAP Lumira installation. The Predict tab holds all the Expert Analytics functionality, and includes predictive algorithms, results visualization analytics, and model management tools.
SAP envisions SAP Lumira and Expert Analytics as a visualization and analysis suite. These tools provide an enterprise solution in which business analytics users and data scientists who use Expert Analytics to develop and build models can share files in the SAP proprietary *.lums format with business users and executives. (These users and executives may have access just to the Lumira portions of the tool.) This solution suite allows these groups to exchange insights, information, and results with each other—and quickly and easily deploy the actionable insights and models to other tools within the SAP and BusinessObjects suites.
Expert Analytics is designed to complement SAP HANA. However, you can use Expert Analytics without SAP HANA. Expert Analytics is installed locally on the user’s machine and accesses data for processing on the workstation (from a CSV, Microsoft Excel, or Java Database Connectivity (JDBC) connection to a database) or on SAP HANA. For offline processing, Expert Analytics relies on a local installation of SAP Sybase IQ (also a columnar, in-memory database) to store and process the data for prediction. Predictive Analysis is available both as part of the SAP Predictive Analytics desktop and client-only installation packages, both of which install in minutes. Expert Analytics includes an installation tool to load the required R components for SAP HANA offline processing. Expert Analytics can be run on Windows 7 or 8 computers, and does not require any other SAP tools.
The target user for Predictive Analysis is a team member who needs to extract predictive insights from data. This person might be a professional data scientist who typically works with a code-based statistical tool on a daily basis or a business analyst who is familiar with front-end BusinessObjects tools. While SAP has previously promoted Expert Analytics as a predictive tool for the masses, users will find themselves better able to understand and interact with the results if they have at least a cursory background in predictive techniques and statistical terms. Future updates to the tool will likely increase the target audience on both ends of the spectrum; as additional features and algorithms are added, more data scientists will be able to switch from their code-based statistical tools to Expert Analytics for all analysis. SAP also expects to integrate more guided analysis paths, which will make the tool more usable for business users with no statistical background.
Modeling Engines
Expert Analytics relies on several modeling engines. When developing the precursor Predictive Analysis, SAP decided to use a combination of internally developed modeling algorithms and open-source R algorithms as the core predictive engine.
Our Language
R is an open-source programming language and run-time environment that is heavily used by statisticians and mathematicians, and is particularly popular in the academic and research communities due to its low cost. R is available for free via the Comprehensive R Archive Network (CRAN) at
https://CRAN.R-project.org/ under a general public license. R stores all data, objects, and definitions in memory and performs its own memory management to ensure that a work space is appropriately sized. R is generally accessed via a command-line interface. However, several editors and integrated development environments, such as R Studio, are available.
R is gaining popularity in the business world as new employees who used R in school want to continue to use a familiar tool once they join the workforce. However, because R is a programming language, it requires a technical statistician with significant programming skills in order to perform predictive analysis.
Figure 2 shows R’s built-in GUI, which consists of an interactive command-line area on the left and a script window on the right.

Figure 2
The GUI of R
The bulk of R’s extensive predictive functionality is available through packages submitted by the worldwide network of R users and developers to the CRAN. While packages on the CRAN are subject to some pre-submission review and testing, much of the functionality is largely user tested, and fixes and enhancements are made by concerned power users rather than a formal development team. This results in relatively robust and reliable code for commonly used algorithms, but potentially less reliable code for more obscure algorithms. As is common with open-source, user-developed software, no formal support is available.
In addition to being freely available and open source, the main benefit of R is the flexibility it provides. As it is a programming language, a skilled programmer can implement virtually any algorithm in R. R was a natural choice for SAP to select as an engine for Expert Analytics; not only does it complement the in-memory SAP HANA architecture, but also, as an open-source programming language, R will never be acquired by a competitor, thus never cutting off SAP’s access to the critical predictive engine. However, since R is free, SAP must add significant value beyond the available R algorithms to justify the licensing cost of Expert Analytics.
As of release 2.0, Expert Analytics uses 13 R algorithms in each of the offline and SAP HANA online modes. The R algorithms are available in offline mode once the user installs R on a local machine, including the required packages that Expert Analytics uses. R algorithms are also intended to be used for online SAP HANA processing, for which R is installed on a separate host that interacts with the SAP HANA server directly. Expert Analytics is compatible with any version of R 3.1 or higher; the latest available version of R is 3.1.2.
SAP HANA Predictive Analysis Library (PAL)
The SAP HANA PAL is a set of predictive algorithms in the SAP HANA Application Function Library (AFL). It was developed specifically so that SAP HANA can execute complex predictive algorithms by maximizing database processing rather than bringing all the data to the application server.
The SAP HANA PAL is available with any SAP HANA implementation — Service Pack (SP) 05 or higher — after installation of the AFL. The SAP HANA PAL makes predictive functions available that can be called from SQLScript code on SAP HANA. As of SPS09 (November 2014), nine categories of algorithms were available in the SAP HANA PAL with 57 total algorithms represented (36 predictive algorithms). The nine categories are described in
Table 1.
| Algorithm category |
Description |
| Clustering |
Unsupervised learning algorithms for grouping similar observations or detecting anomalies. These algorithms accept only numerical data. |
| Classification |
Supervised learning algorithms for categorical or binary data predictions, including decision trees, neural networks, logistic regression, self-organizing maps, and K-Nearest Neighbor classification. |
| Regression |
Supervised learning algorithms for numeric data predictions, including geometric, logarithmic, exponential, linear, and polynomial regression. |
| Association |
Algorithms to determine correlations, patterns, and commonalities within sets of items, including the Apriori, frequent pattern (FP)-Growth, and KORD algorithms. |
| Preprocessing |
Data preparation algorithms to evaluate and manipulate data, including binning, sampling, normalization, and outlier detection. |
| Time series |
Various algorithms for forecasting time-dependent data, with the ability to compensate for trends and seasonality. |
| Statistics |
Basic descriptive statistical algorithms to understand distribution shape and variance properties of a dataset. |
| Social network analysis algorithms |
Link prediction algorithm to predict “missing links” (next most likely contacts) within a network. |
| Miscellaneous |
Grouping algorithms with weighting elements. It includes ABC Analysis (classification with value weighting) and the Weighted Score Table algorithm, which evaluates alternatives when the importance of each criterion differs. |
Table 1
Algorithm categories in the SAP HANA PAL
Expert Analytics Local Algorithms
While Expert Analytics relies most heavily on the R predictive engine and the SAP HANA PAL in SAP HANA online mode, seven algorithms are available for local (offline) processing that are not sourced from R. Most of these duplicate available local, R-based algorithms (triple exponential smoothing time series models, and five varieties of regression), but these local algorithms are the only source for the outlier detection algorithms. The local predictive algorithms allow Expert Analytics to have somewhat similar functionality in offline mode that the SAP HANA PAL provides in the SAP HANA online mode, but the bulk of the predictive-modeling functionality is available via the R predictive algorithms in offline mode.
In addition to the pre-processing algorithms in the offline version, SAP has added two algorithms to mimic the functionality from Automated Analytics: Auto Classification and Auto Clustering, both of which do not use the R predictive engine.
A Detailed Look at Expert Analytics
Expert Analytics is built on the same codeline as SAP Lumira, encompasses all the functionality of SAP Lumira, and adds a predictive tool. The UI for both SAP Lumira and Expert Analytics is being updated frequently as new features are added, and underwent a drastic UI shift with the late 2013 conversion to HTML5.
Upon opening a new Expert Analytics document, five views are available from a selection bar at the top:
- The Prepare tab includes all the SAP Lumira data manipulation functionality
- The Predict tab (Figure 3) holds all the predictive functionality, including data preparation, modeling, and data writer tools (and is not available when viewed in a Lumira-only installation)
- The Visualize tab includes all the SAP Lumira visualization functionality
- The Compose tab allows users to create storyboards and infographics, which produce stories that weave together multiple visualizations targeted towards an analysis consumer
- The Share tab, which allows users of Expert Analytics and SAP Lumira to share documents and objects (this tab appears in both SAP Lumira and Expert Analytics) and upload content to SAP Lumira Cloud
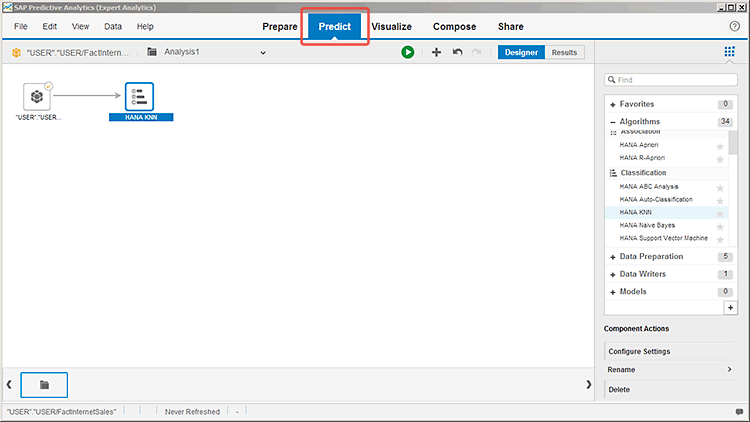
Figure 3
Expert Analytics features appear on the Predict tab
- SAP Lumira functionality
- Expert Analytics architecture
- Expert Analytics functionality
SAP Lumira Functionality
Upon opening SAP Lumira or Expert Analytics, users are greeted by a welcome screen where they can create a new document or open previously created documents, datasets, and visualizations (
Figure 4).

Figure 4
The home page of Expert Analytics
To create a new document, click File > New from the top toolbar or My Items > Documents in the left navigation pane and then on the screen that opens click New Document above the list of existing documents.
Figure 5 lists the selections for data sources that are available for the new document.

Figure 5
Select a source for a new document
Expert Analytics operates in two modes: online with data on SAP HANA or offline with downloaded data. Clicking the Connect to SAP HANA data source link activates the SAP HANA online processing mode. All other selections on the screen transfer the selected data to the user’s local machine and activate offline mode. The mode determines whether or not data manipulation features are enabled and which predictive algorithms are available.
The fastest way to get data into Expert Analytics is to import a plain text or Microsoft Excel file. Like many other modeling tools, Expert Analytics can also pull data directly from a variety of databases via open database connectivity (ODBC) connections. With the appropriate data access driver, Expert Analytics can access data on most popular database platforms via freehand SQL queries.
In addition to downloading data via freehand SQL queries, users can extract data from existing SAP BusinessObjects universes (either *.unv or *.unx files) rather than re-building this infrastructure in a file extract or freehand SQL query. After you select the universe data source and enter connection information for the BusinessObjects server, Expert Analytics shows the list of universes available and allows the user to select which fields to include in the imported dataset.
Expert Analytics allows users to perform some basic dataset manipulations within the tool. This is helpful for the experimentation and discovery stage of the predictive analysis process. Once at least two datasets have been added to the document, you can merge the new and old datasets together on a common field, with automated suggestions for which fields might be best to join on (
Figure 6).

Figure 6
Merging datasets in Expert Analytics
The biggest advantage of Expert Analytics’s direct integration with universes and databases is that the data extract definition (i.e., the universe query or freehand SQL query statement) is stored within the Expert Analytics document, and an updated dataset can be accessed on demand. When manual queries are written to extract data to text files for importing into modeling software, the field calculations and selection criteria might be lost or not well documented and, thus, be very time consuming to re-create.
Expert Analytics works well with SAP HANA. See the sidebar, “Accessing Data Online with SAP HANA,” for further details.
Accessing Data Online with SAP HANA
In addition to downloading data and running it locally on the client
machine, Expert Analytics can also work in conjunction with an SAP HANA
server and Linux host to run the SAP HANA PAL and R algorithms. You can
access SAP HANA online data from SAP HANA tables, calculation views, and
analytic views. In SAP HANA online mode, there are no data manipulation
features available in Expert Analytics, but you can still use all the
visualization tools.
In addition, accessing data that resides in SAP HANA increases the
capacity of Expert Analytics, as it is no longer limited by the
processing power of the client machine. After specifying the SAP HANA
connection information, the user can select from a list of all SAP HANA
objects available (
Figure A). Once the source object is selected, the user can further trim the analysis set by taking the follow actions:
- Mark the box for Preview and select data, which is available after you select the source object
- Choose only a subset of the fields to be available in Expert
Analytics, which is available when you click the Next button after
selecting the source object

Figure A
Navigate SAP HANA objects in Expert Analtyics
For organizations with an existing SAP HANA infrastructure (e.g.,
attribute views, calculation views, analytic views, and other database
elements), attributes and metrics used in existing BI documents can be
examined directly through Expert Analytics rather than being recreated
via a freehand SQL query or a manual extract. Even when new SAP HANA
information views must be created for modeling, these objects are
persistent on the SAP HANA server, allowing the Expert Analytics data to
refresh at the click of a button. The modeling datasets and metrics are
also available to other users to analyze in BI documents, reports,
dashboards, and visualization tools.
Data Manipulation
Once the data has been loaded from one or more sources, data manipulation components allow analysts to modify and create data elements quickly. Grouping and transforming data is particularly important to the model building process. Many modeling tools allow for minimal data manipulation, requiring the analyst to generate an entirely new modeling extract to change age groupings, for example. Expert Analytics facilitates calculations and manipulations on existing columns and adds further lookup data sources to avoid the need to manipulate data outside the tool.
Note
Documents accessing SAP HANA online data sources have data manipulation,
enrichment, addition, and merge features disabled. All data
manipulation for SAP HANA online data must be performed in the
information views sourced for the Expert Analytics document.
For example, the dataset in
Figure 7 has a birth year column, but age is more appropriate as a modeling variable because it is not time dependent. A model can predict the behavior of 20-year-olds today, next year, and five years from now, and will always be predicting the behavior of incoming 20-year-old people based on the experience data. Therefore, age must be calculated before modeling.
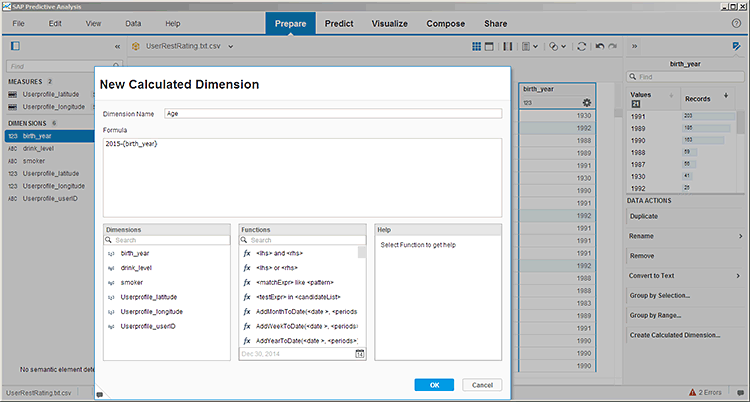
Figure 7
Preparation of a modeling dataset with the birth_year column
In the Prepare tab, right-clicking the birth_year column and clicking the Create Calculated Dimension… option brings up the dialog box with formulas and field picklists to create the logic required for the new field.
In addition to simple formulas to create new measures or dimensions, data can be cleansed to convert data types or replace bad values, or grouped to create meaningful segments for visualization or prediction.
Data Enrichment
Once data is imported into Expert Analytics, the software automatically detects potential enrichments to the attribute fields. Enrichments provide additional functionality for specific types of attributes. For example, date fields enriched as time hierarchies have automatic subtotals for year, quarter, month, and other intervals. Expert Analytics can enrich data for both time and geographic hierarchies, based on the presence of date fields and location fields (city/state/country or lat/long) respectively.
Note
For SAP HANA online data, only geographic hierarchies can be enriched
within Expert Analytics. Measures and time hierarchies must be defined
in the SAP HANA information views prior to import into Expert Analytics.
While measures are not required for using predictive algorithms, they
are required for creating any visualizations in Expert Analytics.
Figure 8
Figure 8
Expert Analytics indicates it has detected possible enrichments
Expert Analytics automatically detects numeric fields to be measures (including key fields and numeric attributes) and partial date hierarchies (day or month). It also detects any fields with a date format as a date hierarchy.
The geographic hierarchy enrichment allows a user to assign an attribute column to represent one of four geographic divisions: country, region, sub-region, and city. Alternatively, users can define a geographic hierarchy based on latitude and longitude. Right-click any field in the attribute list to manually select an enrichment for that field, which then opens the screen in
Figure 9.
>

Figure 9
Geographic enrichment options
Once the geographic hierarchy has been defined, Expert Analytics automatically detects the appropriate geographic object based on text and verifies this with the user. It prioritizes elements that cannot be matched or were inconclusively matched to the geographical reference shipped with SAP Lumira so the user can review them (
Figure 10).

Figure 10
Inconclusively matched elements
After the user accepts or updates the automatically detected geography by selecting an alternative geographic assignment for any unmatched or inconclusive assignments, one or more geographic elements are available for inclusion in charts or geographic charts. Expert Analytics automatically fills in all levels of the geographic hierarchy above the level used to map the geography. For example, if the user provides the city and state, Expert Analytics fills in county, state, and country and the user can use any level within the automatically generated hierarchy in geographic visualizations.
Expert Analytics includes the following chart types in the geographic visualizations menu, indicated by the red circle in
Figure 11: choropleth chart (i.e., a map with different shades based on measurements, such as shown in
Figure 11), bubble chart, and pie chart. The user has a drop-down selection of all the available hierarchy elements, shown under the Dimensions selection in
Figure 11.

Figure 11
A choropleth chart showing states in different shades
With offline data, users can create measures whenever necessary by clicking the Settings gear button for any attribute in the left side select pane and clicking the Create Calculated Measure option. Or you can select the drop-down list on the measure and change the aggregation method (
Figure 12). (Hovering over any object on the left side of the pane reveals a button with a gear shape. Clicking that displays the drop-down menu where you can change the aggregation method or create a calculated measure.) Users can also create calculated measures by clicking the Create a new Measure button and using the SAP Lumira formula library.

Figure 12
Change the aggregation method for a measure
In offline mode, Expert Analytics automatically creates all numeric variables as measures in the document with the Sum aggregation, so users must determine which measures should actually be used within the document and the appropriate aggregation methodology. In SAP HANA online mode, measures must be designated in the SAP HANA information view and cannot be created within Expert Analytics. Without one or more measures in the document, it is impossible to create any visualization of the data, so users should create at least a count measure to visualize the data. The count measure allows users to view frequencies of records within each dimension.
Data Visualization
Expert Analytics has an easy-to-use data discovery tool available under the Visualize tab. The point-and-click interface lets users perform pre-modeling data exploration tasks more quickly than writing code or summarizing the data and exporting the results to a visual tool, such as Excel.
Several types of charts are available by clicking the visualize modeon the Prepare tab, including bar charts, line charts, pie charts, geographic charts, tree and heat maps, tabular view, and others (
Figure 13).
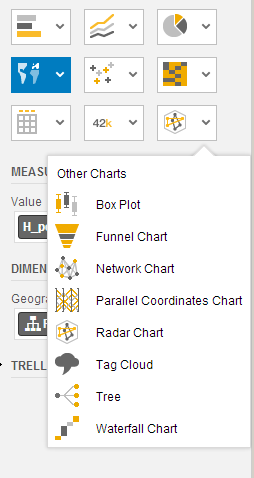
Figure 13
Chart options available in visualize mode
Switching between visualization types (e.g., from bar chart to pie chart to time-series chart) takes only a few clicks using the icons on the right-side chart control panel. This encourages investigation into patterns in the data. Expert Analytics also automatically saves the current visualization. Users can create a new visualization by clicking the plus icon on the bottom library ribbon, shown at the bottom of
Figure 11.
You can share these saved visualizations, along with the modified datasets, by clicking the Share tab at the top. Once the Share tab is open (
Figure 14), you can send items from the document to others via email, upload visualizations to SAP StreamWork, publish analysis sets to BusinessObjects Explorer and SAP Lumira Cloud, export them as a text files, or write them to an SAP HANA table.

Fiugre 14
Options to share saved visualizations
Sharing Data Visualizations and Insights
SAP has been rapidly expanding the publication and sharing aspects of SAP Lumira and Expert Analytics tools. To enhance the ability to present visualizations created under the Visualize tab, SAP has recently added the Compose tab, shown in
Figure 15, which allows analyst authors to create storyboards or infographics. They combine saved visualizations, text, pictures, and other graphics to assist the audience in understanding and immediately drawing insights from visualizations.

Figure 15
Compose tab
Another key component to the communication strategy is the SAP Lumira Cloud application, which is a web-based interface that allows you to interact with a dataset, build visualizations, and view and create storyboards and infographics. In addition, visualizations, storyboards, infographics (shown in
Figure 16), and datasets created using the desktop tool can be uploaded to SAP Lumira Cloud and shared with other users (or made public for anyone to view).

Figure 16
SAP Lumira Cloud infographic
SAP’s Lumira Cloud environment is open and anyone can sign up for a free account with limited storage (enterprise accounts allow organizations to create their own security groups within the shared corporate workspace), or organizations can host their own on-premises SAP Lumira Cloud environment using their local SAP HANA server. Another benefit of the SAP Lumira Cloud environment is that no installations are required. Any user with a web browser can use it. The SAP Lumira Cloud environment includes all the functionality from the desktop tool contained in the Visualize and Compose tabs (as shown in
Figure 17), but does not support any of the data manipulation (Prepare tab) or predictive (Predict tab) functionality found in the Expert Analytics desktop tool.

Figure 17
SAP Lumira Cloud Visualize tab
Expert Analytics Architecture
Expert Analytics is installed and run locally on the client machine and is currently only compatible with Windows operating systems. It has a small library of built-in predictive functions for linear regression, time-series analysis, and outlier detection. The software largely relies on the local R, SAP HANA PAL, and SAP HANA-R predictive libraries for most of its predictive functionality.
Figure 18 shows the full Expert Analytics architecture and interaction with data sources.
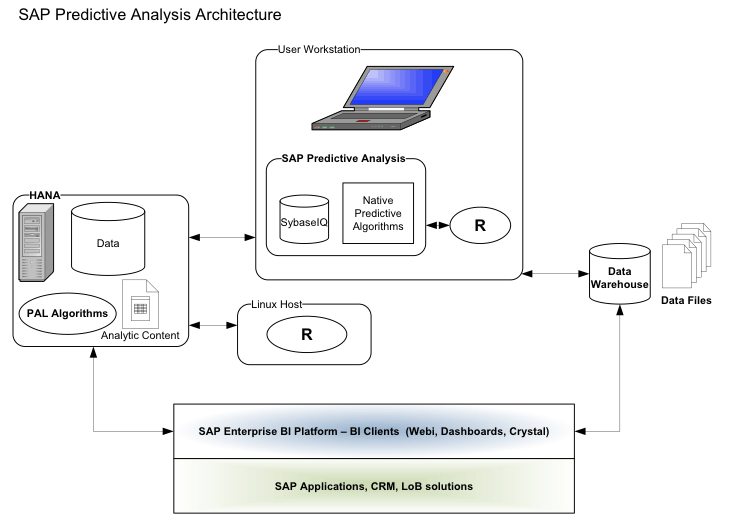
Figure 18
Expert Analytics architecture
Expert Analytics operates in two modes:
- SAP HANA online mode, in which data is stored on SAP HANA and predictive algorithms are run on either SAP HANA or an affiliated R Linux host
- Offline mode, in which data from a text file or database is downloaded to the user’s workstation and processed using only the client system resources
Each Expert Analytics document operates either in SAP HANA online mode or in offline mode and cannot be changed. In SAP HANA online mode, local R algorithms are not available, and in offline mode, the SAP HANA PAL and SAP HANA R algorithms are not available, even if the data was originally sourced from SAP HANA.
SAP HANA Online Mode
In SAP HANA online mode, the data remains on the SAP HANA system, and all visualization queries, predictive algorithms, and resulting data are also stored on SAP HANA. This enables larger volumes of data to be processed through predictive algorithms than would be possible on the desktop client alone.
Figure 19 shows the architecture of Expert Analytics for SAP HANA online data sources.
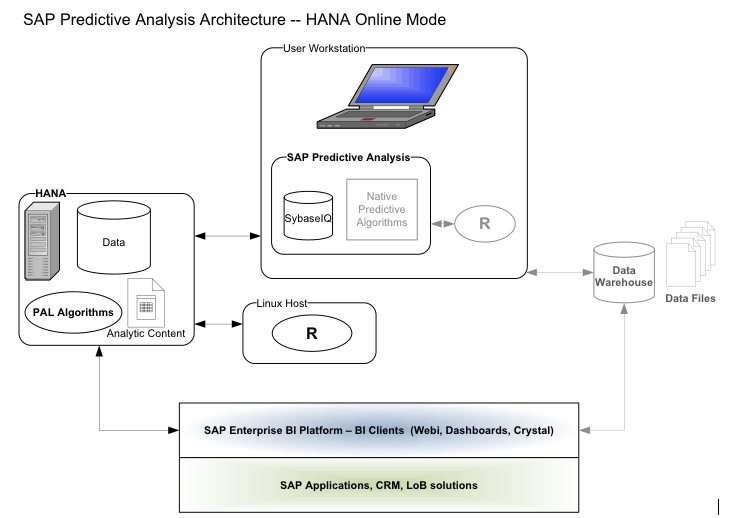
Figure 19
The architecture of Expert Analytics in SAP HANA online mode
SAP HANA supports the R scripting language and SQLScript language. R is supported on SAP HANA by including an R client in the SAP HANA calculation engine. The R client on SAP HANA connects to an Rserve instance on an affiliated Linux host.
Rserve is a TCP/IP server that supports remote connection, authentication, and file transfer and allows access to any functionality of R to be integrated into other applications. Rserve is called by an R client, versions of which are available for Java, C++, R, Python, .NET/CLI, C#, and Ruby. Rserve is supported on most operating systems. However, the SAP HANA-R implementation currently only officially supports R running on a SUSE Linux host.
Because the R algorithms are running on a separate machine, there is some cost to marshaling data between systems; however, since this process does not involve writing data to disk, the effect on predictive algorithm run time is minimal. Additionally, the SAP HANA calculation engine’s matrix primitives are relatively close in structure to Rserve’s data frame structure, so the marshaling cost of moving the data between the SAP HANA calculation engine and Rserve is limited primarily by network bandwidth.
In an optimal implementation, the SAP HANA and Rserve boxes are co-located with sufficient bandwidth to support large datasets. The data transfer between R and SAP HANA is in a binary form, which further increases speed and reduces the quantity of data transferred across the network.
Each concurrent R call requires a separate connection to the R host, so if there is a high number of Expert Analytics users frequently running lengthy modeling routines, SAP HANA administrators may need to configure multiple ports or have multiple R hosts available to ensure high availability.
In SAP HANA online mode, there is little data manipulation functionality available in Expert Analytics. Therefore, all data modeling, calculations, cleansing, and value grouping must be done in SAP HANA. The example in
Figure 20 shows an analytic view used for Expert Analytics; the value lookups into the attribute views must be performed in SAP HANA and cannot be imported as separate text files and joined within Expert Analytics.

Figure 20
An analytic view for Expert Analytics
These limits may require a Expert Analytics user to be well versed in one of the following:
- An extract, transform, and load (ETL) tool to build datasets
- SAP HANA data modeling
Alternatively, the user could partner with a team member who can implement these changes during the modeling process. Although it may require more work up front, building the modeling datasets in SAP HANA is a best practice, since this ensures that the modeling dataset definition is preserved within SAP HANA and updated data is available instantly. This also facilitates scoring of the model later within the SAP HANA database, as the fields required for the model are already defined within the SAP HANA database. One possible implementation scenario is to perform initial exploratory analysis and data manipulation in offline mode, in which the business user can manipulate and re-group variables, and then implement the final required variables in a SAP HANA analytic view once the model has been approved.
As a part of running the predictive algorithms in SAP HANA online mode, Expert Analytics stores records of the predictive modules called in the user’s schema on SAP HANA.
Figure 21 shows tables that have been created by running predictive algorithms in a SAP HANA online Expert Analytics document. The last table in the list, pas_esr_state, shows a list of all executions for which the logged-in user was associated with that schema and the time (GMT) in milliseconds since January 1, 1970, that each one was executed. This approach may be useful for monitoring use of the Expert Analytics tool on SAP HANA by each user. Assuming most of these require R algorithms, this also helps monitor the use of the Rserve box.

Figure 21
Table created by running predictive algorithms in SAP HANA online
The rest of the tables include result information for the actual models run in Expert Analytics. Each of the pas##_X_MODEL_TAB tables holds the printed output displayed in the text results window in Expert Analytics and the Predictive Model Markup Language (PMML) model output. In addition to tables like the ones above, several stored procedures are created with each run, and column stores are also created for saved visualizations and other intermediary data manipulation steps.
This content is not particularly useful to users, but it does appear to persist significantly after the Expert Analytics session is closed, even if the document it was created under is not saved. While these items are typically quite small and shouldn’t take up major space in SAP HANA, the volume of content that can be created through normal use of Expert Analytics could quickly make it difficult to navigate any SAP HANA schemas used with Expert Analytics. Therefore, SAP HANA administration teams must be aware that this content is being created and periodically clean out some or all of it in any user schemas that log into Expert Analytics.
Tip!
Organizations may want to run Expert Analytics using only a few
designated user logins to minimize the spread of auto-generated content.
With the introduction of version 1.0.10, Expert Analytics began calling SAP HANA PAL functions using a new API, which requires the creation of the AFL_WRAPPER_GENERATOR(SYSTEM) procedure and granting any Expert Analytics user accounts execute privilege on this procedure. This new API supports only a limited range of field types. All datasets used for SAP HANA PAL algorithms must have only Integer, Double, VarChar, or nVarChar data types in independent columns. The presence of any other field types causes a live cache error when the SAP HANA PAL algorithm is called.
Offline Mode
Expert Analytics is less complex in offline mode. Data is imported via the configured database connectors via freehand SQL or a text file.
Figure 22 shows the system interaction for Expert Analytics operating in offline mode.
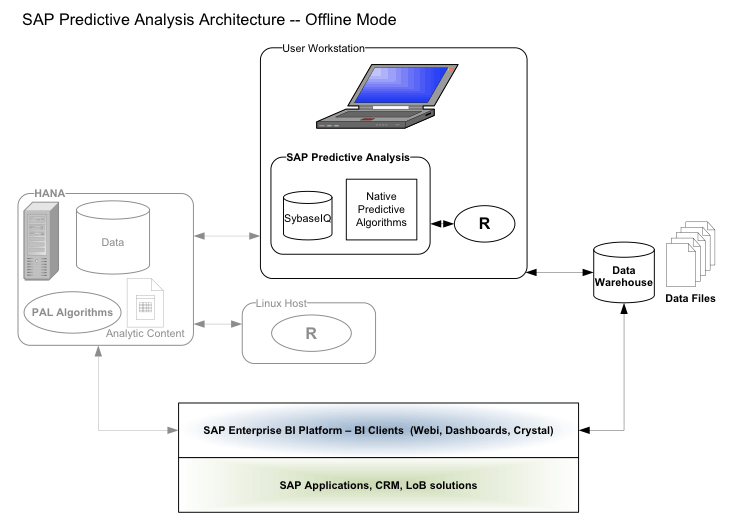
Figure 22
The architecture of Expert Analytics in offline mode
The imported data is saved in the Expert Analytics document within Sybase IQ. Therefore, when an Expert Analytics document is shared among users of SAP Lumira and Expert Analytics, the shared document is fully functional and includes all the original data. While the document is open, the data is stored in memory on the user’s workstation. For this reason, very large datasets can cause slow performance not only during prediction, but also for visualization.
Once the data is imported and manipulated in Expert Analytics, most of the predictive algorithms on the Predict tab are actually calling functions in the locally installed version of R. All the data processing in the local R engine is performed on the user’s workstation and is limited by the dataset size in R and the available memory in R and on the workstation.
Installation Notes
SAP released the first version of SAP Predictive Analytics 2.0 in early February 2015, which is the first release to include both the former Infinite Insight and Predictive Analysis tools in the same installation. There are two versions of SAP Predictive Analytics that can be installed: the desktop version, which includes the local version of Advanced Analytics, and the client/server version of Advanced Analytics. Both versions include identical copies of the Expert Analytics component.
Installing the local or “desktop” version of Predictive Analytics 2.0 is a simple installation of an executable file. Once this is installed, R must also be installed locally on the user’s workstation. SAP has included a built-in R installation utility available under the File menu within Expert Analytics, which enables R algorithms and starts a download of the R application and required packages, as shown in
Figure 23. If this download does not work, the user must manually install the R application (I recommend version 3.1 or later) and the required R packages and then point Expert Analytics to the directory in which R is installed.
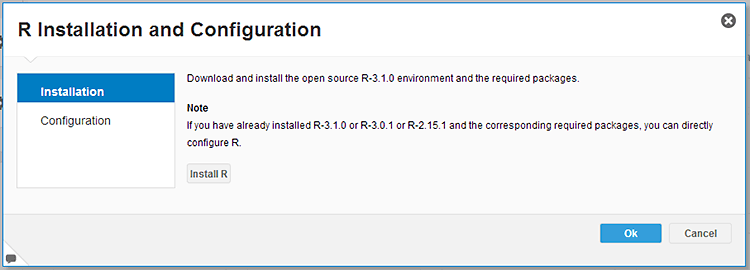
Figure 23
The R Installation and Configuration utility
To access the SAP HANA PAL through Expert Analytics, you need to upgrade SAP HANA to Support Package 05 or higher and install the AFLs. In addition, you need to enable the scripting server, per SAP Note 1650957. More information on the installation of the AFL is available in SAP HANA Installation Guide section 6.
R is neither supported nor shipped by SAP because R is open source and protected under a general public license. The SAP HANA administrative team or R-host administrator must install and configure Java, R, and the required R packages for Expert Analytics on the R host, and configure and enable the R client in the SAP HANA calculation engine. For further details, refer to the SAP HANA R Integration Guide. If the Linux host is running SUSE with an active support agreement, you can download and install R and Rserve via the update repository. In this situation, there is no need to compile the R code.
Additional information and test cases for the installation process are available in this installation guide posted on
Decision First Technologies’ SAP BI Blog. Because SAP Lumira and Expert Analytics have been combined, a user can only have one of the two applications installed on a workstation at one time. Users with SAP Lumira or a previous version of Visual Intelligence must uninstall the visualization-only version of the application before they can install Expert Analytics.
Expert Analytics Functionality
Most of the functionality unique to Expert Analytics is found on the Predict tab (
Figure 24), which is only available to users who have licensed the Predictive Analytics tools; otherwise, users see only the Prepare, Visualize, Compose, and Share tabs that appear in SAP Lumira.
The Predictive Workflow
The Predict tab features a predictive workflow design area, which allows users to string together data sources, data manipulation modules, algorithms, models, and data writers to build predictive analyses. These predictive workflows can be linear, like the example in
Figure 24, or branched to create separate analyses for comparison between alternatives or to run separate modules, like in the example in
Figure 25.

Figure 25
A branched predictive workflow
Branching the transforms allows only a portion of the analysis to run. Clicking the green-arrow icon above the predictive workflow runs the entire workflow. However, hovering over a module within the workflow and clicking the Run up to Here option (which also provides a message of Run Till Here) allows users to run only the predictive workflow steps prior to and including the selected step. Doing so reduces run time and processing resources and allows a user to verify that the intermediate steps provide the expected results prior to running the entire analysis.
Predictive algorithms can also run sequentially, and you can use the results of one model as an input into a second modeling algorithm. In the example in
Figure 26, you can use the predicted customer cluster from the SAP HANA R-K-Means algorithm as an input variable in the SAP HANA R-CNR Tree model.
Figure 26
You can use the results of one model as an input into another model
You must configure properties for all elements in a predictive workflow except the source object prior to running. When a module is first brought into a workflow, such as the R-K-Means element in
Figure 26, a single yellow checkmark in the upper right corner indicates that it is configured. The configuration check prior to execution only ensures that required fields are populated, and is not a guarantee that the predictive workflow will execute without errors.
Once the object has been successfully executed, a shadowed green checkmark appears in the upper right corner of the object. Before it runs, there is just a yellow checkmark.
Data Preparation Modules
In addition to the data manipulation functionality in the Prepare tab, there are several modeling-related data preparation modules available in the algorithm library, which appears in the top half of the Predict tab.
Figure 27 shows the available data preparation functions available in offline mode.

Figure 27
Data preparation functions in offline mode
Let’s look at these data preparation functions further. Filter and Sample are used to reduce records or fields (e.g., randomly, systematically, or logically) going into the modeling transforms. Filter can remove records that should not be considered in a model (e.g., outliers or missing data).
Data Type Definition and Formula allow for manipulation of the input or output data. Data Type Definition changes the name of a column or the format of a date field. Formula allows for basic manipulation of the data and aggregate calculation.
Formula includes date manipulation formulas, string manipulation formulas, and logical expressions. There are also several aggregating mathematical functions that calculate the maximum, minimum, sum, average, and count within the entire column. These functions cannot be nested within one another in the same function block, but the same result can be achieved with sequential function blocks.
The data manipulation formulas @REPLACE and @BLANK can replace specific or blank values. This duplicates functionality that exists already in the Prepare tab, but explicitly programming these rules as formulas means that the manipulation rules are documented and are part of the predictive workflow. Thus, when new data files in the old format are imported into the project, the rules can be automatically applied rather than going back through the manipulation steps in the Prepare tab.
The Normalization algorithm is a data transformation commonly used prior to modeling. Normalization adjusts the scale of the variables. There are a variety of methods of normalization. The most popular are min-max normalization, which scales values between 0 and 1 by subtracting the minimum value and dividing by the range of the dataset, and standardization or z-score normalization. This re-centers the values and divides by the variance to make the data comparable to a standard normal (N(0,1)) distribution.
Predictive Algorithms
The library of predictive algorithms is found in the top half of the Predict tab. The list of included algorithms available in Expert Analytics is one aspect of the tool that is changing quickly. With every release, SAP adds algorithms. As an example,
Figure 28 shows the full list of algorithms available in offline mode as of release 1.21, while
Figure 29 shows algorithms available in online mode for the same version.

Figure 28
Predictive algorithms available in offline mode

Figure 29
Predictive algorithms available in SAP HANA online mode
Within each predictive algorithm, there are typically one or two main fields that must be configured by clicking the Configure Settings button prior to running. There are three ways to get to the screen shown in
Figure 30. You can double-click the algorithm object in the predictive workflow in the Designer view on the Predict tab. You can click the Configure Settings option after hovering over the algorithm object in the predictive workflow and clicking the gear icon. You can select the component in the predictive workflow and click Configure Settings under Component Actions in
Figure 24.
Most models require one or more predictors (often called independent columns) to be selected from the available fields in the document. The supervised learning algorithms (including decision trees and regression models) further require the result or dependent variable to be defined (
Figure 30).

Figure 30
Predictors for the SAP HANA R-CNR Tree
Most of the other options default to commonly selected values. For example, the clustering algorithm defaults to five clusters, but this may not be appropriate depending on the dimensionality of the input data and the business needs of the organization. Users should carefully review settings for things such as Output Mode, Missing Values, and Method options, and understand the effect of keeping the default settings. Some information on the details of each configuration option is found in the Expert Analytics documentation (follow menu path Help > Help). However, users may need to have a statistical background, such as understanding the meaning and effect of changing prior probabilities or fitting methodologies, to fully understand all the settings.
There are additional options that users may want to consider changing as well. Examples include renaming output columns, saving the predictive model, and updating optional model properties that may help the model conform to more realistic business expectations (e.g., limiting the complexity of a decision tree).
One of the most important features of Expert Analytics is the automated model fit visualizations and diagnostics. With SAP Lumira’s visualization tools, Expert Analytics offers some impressive model visualizations. The quality, usefulness, and readability of visualizations vary greatly by algorithm. Visualization samples for algorithms with graphical output are included in
Figures 31 through
34. They show clustering (
Figure 31), decision tree (
Figures 32-33), and association algorithms (
Figure 34) respectively.
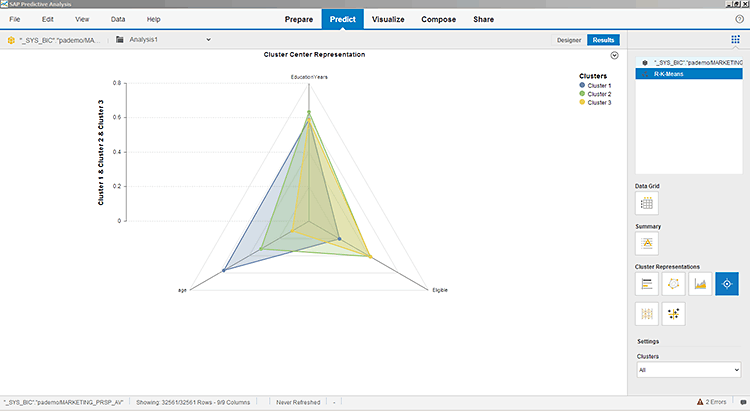
Figure 31
The results visualization for an R-K-Means clustering algorithm
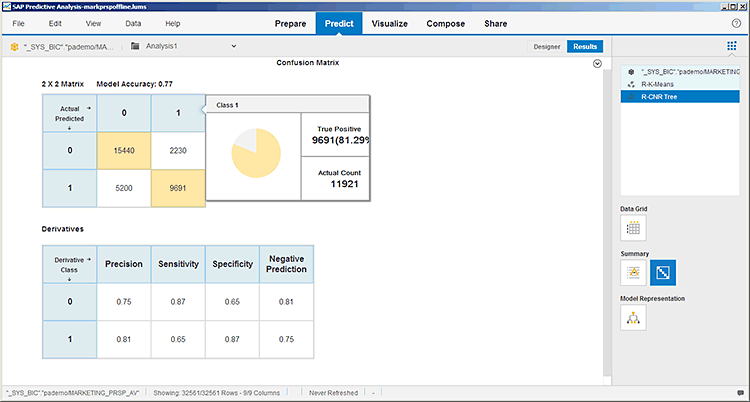
Figure 32
Confusion matrix visualization for the R-CNR decision tree algorithm

Figure 33
The results visualization for an R-CNR decision tree algorithm
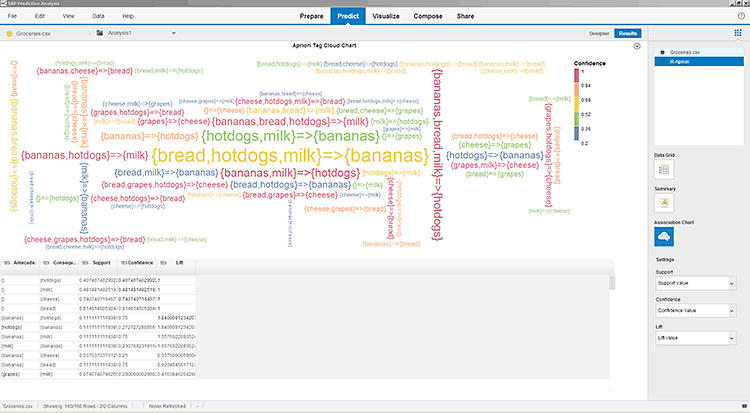
Figure 34
The results visualization for an R-Apriori association algorithm
In addition to the graphical visualizations, typically the standard algorithm output from the R algorithm is printed in the text results output visualization. While the R summary output often has valuable information — such as coefficient values, fit statistics, and predictor significance — the output may be illegible due to poor text formatting. An example of the text output for multiple linear regression is shown in the Algorithm Summary in
Figure 35. This text output information is valuable not only to data scientists evaluating the fit of models, but also to the business units that must implement predictive models in other systems.

Figure 35
The text ouptut for multiple linear regression
A point to be aware of in Expert Analytics: The resulting visualizations for some algorithms are limited in the number of observations that can be displayed. For example, the regression algorithm visualization displays each observation compared to the predicted value. For a small dataset, this is valuable, but for a dataset with several thousand observations, Expert Analytics cannot display any graphical output. In this case, the user is left with only the text output and predicted values in the resulting dataset to determine the fit and significance of the model.
Typical visualizations for regression output include outlier distributions, residual analysis, and one-way correlations and relationships between predictors. Currently, none of these default visualizations are automatically available for regression models in Expert Analytics, although I expect SAP to address this issue in future enhancements.
Exporting Predictive Data
Let’s start by reviewing how to export predictive data in offline mode. Datasets and predictive workflow results can be written to a database system via a JDBC connection, which requires some configuration within the predictive workflow. The user must configure the connection options shown in
Figure 36.
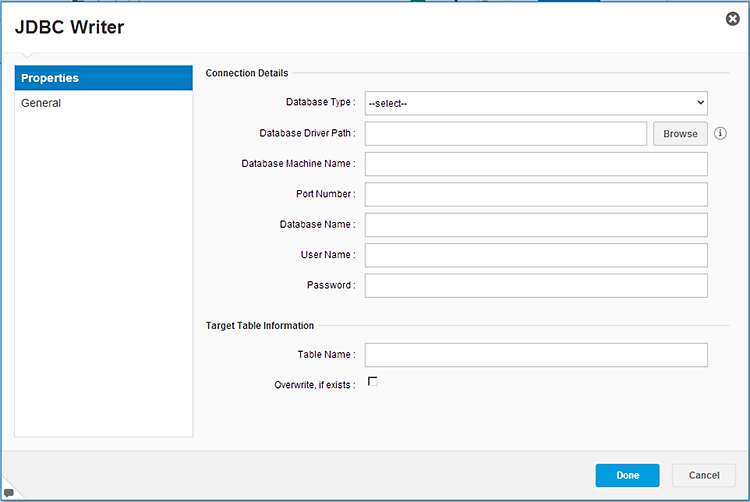
Figure 36
JDBC Writer module options for exporting predictive workflow data back to a database
Alternatively, the predictive workflow can write to delimited text files. Text files from Expert Analytics can be picked up by an ETL process and loaded into the database.
In SAP HANA online mode, the only output source to include in a predictive workflow is an SAP HANA Writer module, which writes the output dataset to a table in SAP HANA. This has the option of overwriting an existing table, but it does replace the entire table even if not all the columns are brought into Expert Analytics.
Custom R Components
In addition to the built-in algorithms, with version 1.11, SAP introduced the ability to create user-defined components that run any R Script the author defines. Once the module is created with the custom R script and the inputs are set properly, the resulting Custom-R Component has the same look and feel as the built-in algorithms, with drop-down or check-box type data inputs.
This is an especially useful feature for organizations that use sophisticated algorithms that are not in the stock algorithm library, but want to deploy predictive algorithms to a wide range of users. In this type of scenario, a technical data scientist who develops a complex algorithm specific to the industry or organization can create the Custom-R Component, and then share the created component with other business analysts who use it without knowing the underlying technical details.
To create a Custom-R Component, you enter the R Script in the configuration screen shown in
Figure 37, specifying the name of the function that should be used to drive the component, and even allowing configuration options for saving a fitted model from the Custom-R Component and showing visualizations from the R Script.
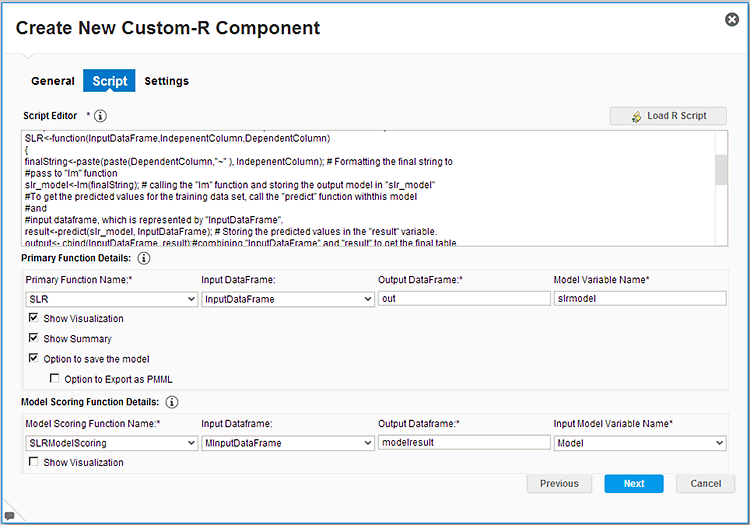
Figure 37
Custom-R Component configuration
After the R Script has been entered, the second configuration screen, pictured in
Figure 38, allows the author to configure the inputs the user sees – for example, whether independent column inputs should allow one or multiple columns and if there should be a free text input or a selection from a list of values.
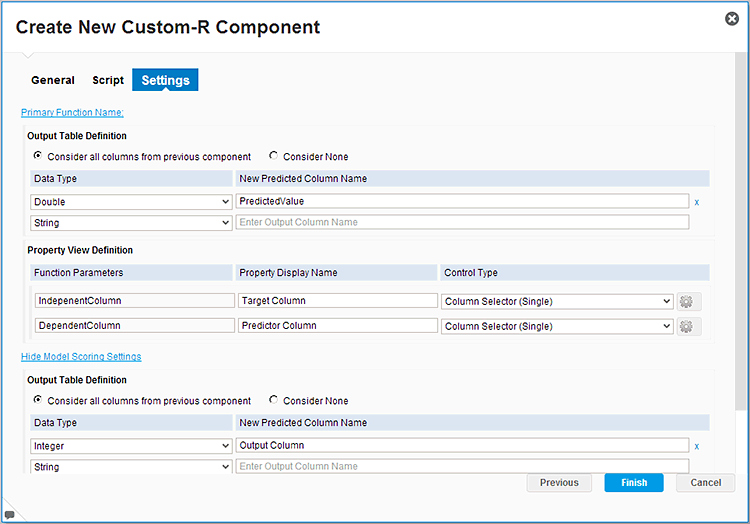
Figure 38
Custom-R Component input output settings
Once the Custom-R Component has been configured, it appears in the list of Custom R Components under Algorithms, as shown in
Figure 39. It is available to be implemented in a predictive workflow, as shown in
Figure 40, with configuration inputs that are as usable as the native components.
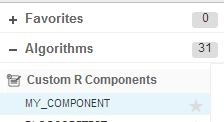
Figure 39
Custom R Components configuration

Figure 40
Using a Custom-R Component in a predictive workflow
While Custom-R Components offers users freedom to leverage any of the 5,000+ algorithms in the R library, all aspects of the algorithm must be tested and developed using R, including model-fitting diagnostics graphics. It is currently not possible to leverage any SAP Lumira visualizations as automated output for Custom-R Components.
For more information on developing and using a Custom-R Component, see this walkthrough on Decision First Technologies’
SAP BI Blog.
Exporting Predictive Models
Once models are developed within Expert Analytics, users can export the model-scoring algorithm in either *.SPAR (SAP Predictive Analysis Archive) or *.PMML (Predictive Model Markup Language) formats. The SVID, which is Expert Analytics’s proprietary predictive model file format, is unique to Expert Analytics. It allows users to exchange models and import previously built models into new Expert Analytics documents.
In SAP HANA online mode, models built using algorithms from the SAP HANA PAL can also be exported directly to the SAP HANA server where the data is located as a stored procedure that can be called within the database without having to access Expert Analytics.
PMML is an XML-based markup language that was developed by data-mining industry groups to provide an industry-standard way to represent predictive models. PMML defines modeling and limited preprocessing structures for the most common predictive models, including clustering, association, regression, time series, and trees.
Most predictive modeling tools can export PMML modeling formats; however, it is somewhat uncommon for databases or applications to be able to consume PMML models natively. There are commercially available scoring engines that you can deploy in the cloud to score PMML models via a web service, on a batch basis, or even using plug-ins to Excel. Alternatively, there are database plug-ins for several common databases—including Teradata, EMC Greenplum, Netezza, and Sybase—which allow scoring models to be called as a function once PMML models have been imported.
One of the benefits of integrating a PMML plug-in into an existing database is that the database can then consume predictive models from virtually any predictive-modeling tool, and organizations can use multiple tools or switch tools with little effect on the deployment timeline.
You can use these same methods to integrate predictive algorithms with other applications. While it is relatively unlikely that applications will automatically be equipped to accept PMML model objects, incorporating these objects into a web service or creating a stored procedure to run the algorithm equation allows a model algorithm to be called by many applications within an organization. Alternatively, the algorithm equation could be programmed directly into the application for calculation. Select the implementation method based on the algorithm complexity.
Automated Analytics
SAP announced the acquisition of KXEN in September 2013. KXEN’s flagship product is the Infinite Insight Modeler, which is best known as a user-friendly highly automated predictive-modeling tool. Over the course of 2014, SAP re-branded KXEN’s tool to be known as SAP Infinite Insight, which includes the KXEN suite of tools used for data preparation, modeling, deployment, and maintenance. In February 2015, SAP re-branded its analytics toolset as SAP Predictive Analytics with the former SAP Infinite Insight tools now called Automated Analytics and the former SAP Predictive Analysis tool re-named to Expert Analytics.
There are several components to the Automated Analytics suite, which are described in the list below:
- Data Manager (previously Infinite Insight Explorer): Data Manager is a GUI-based data-preparation tool with which users can create derived columns and compound variables to transform a source dataset into a modeling dataset. Data Manager can also create modeling datasets out of time-stamped transactional files, significantly reducing the data-preparation step for many common types of models.
- Modeler: Modeler is the core mining and modeling tool, which includes the most common modeling algorithms and the automated modeling workflow that Infinite Insight was known for. Modeler also includes a thorough battery of graphical model diagnostics.
- Social: Social is an advanced modeling component that allows decision-making based on the structural relationships within the data. It is useful for evaluating not only social network-related data, but any dataset that involves complex relationships between observations, such as phone or sensor networks.
- Recommendation: Recommendation is an advanced modeling component to build sophisticated recommendation rules (such as for a product, ad, or content item) based on not only prior purchase patterns of other observed patterns, but also based on the recommendations of the target’s social network group.
- Scorer: Scorer includes several components to facilitate the use of previously built predictive models, including the option to score a new dataset within the Infinite Insight application, but perhaps more importantly, it also includes the option to export predictive scoring rules in many different languages that can easily be deployed within applications or databases where the scoring needs to be performed.
- Model Manager (Previously Infinite Insight Factory): Model Manager is a web-deployed interface that handles versioning and scheduling of model runs and even re-builds, and enables enterprise-level model maintenance and deployment. Model Manager also includes a secured platform with Rights & Responsibilities administration to secure model deployment and revisions.
For the purposes of this article, I’ll focus primarily on the components of Automated Analytics that are most related to creating predictive models and most likely to persist into future versions of the SAP predictive platform, namely the Modeler and Scorer features, as well as the Social and Recommendation algorithms.
Upon opening Automated Analytics, the main screen (pictured in
Figure 41) offers navigation to several of the key components listed previously.
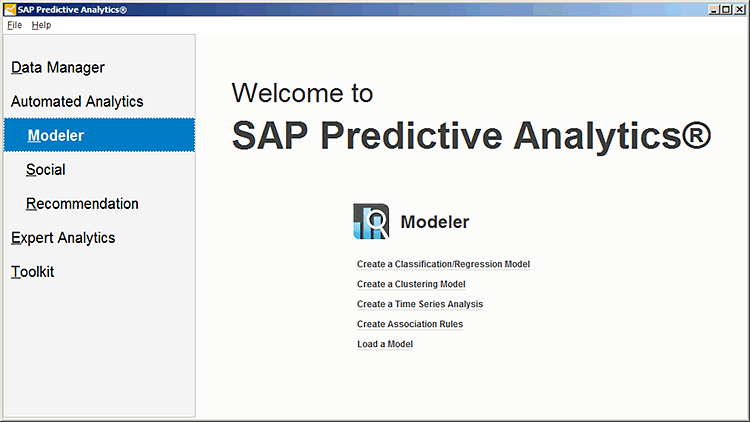
Figure 41
Automated Analytics Modeler screen
Data Sources
Automated Analytics can source data from four main sources:
- Flat files (such as csv or text)
- Relational databases (via an ODBC connection)
- SAS data files
- Data prepared by the Data Manager tool
There is also an API option in which you can develop conduits to accept proprietary data sources. Currently, Automated Analytics downloads data onto the machine on which Automated Analytics is installed for predictive processing. No remote processing within the source database is possible—there is no equivalent to Expert Analytics SAP HANA online mode for Automated Analytics. In this way, the tool’s performance is consistent regardless of the source of the data, but there is an I/O cost to accessing large datasets.
Automated Analytics also cannot access data from SAP BusinessObjects Universes and has no special access conduits for SAP ERP data or SAP Business Warehouse.
Algorithms Available
Automated Analytics supports a short list of supervised algorithms that cover a variety of use cases. As shown in
Figure 41, when entering Modeler, the user selects one of four algorithms, listed and described below:
- ClassificationRegression: For predicting categorical or continuous responses (for example, sales and marketing responses)
- Clustering: For creating groups of customers most likely to have similar response values
- Time Series: For projecting forward data that is measured over time at fixed, consistent intervals
- Association Rules: Create sets of association rules that create relations between two events that imply that when X occurs then Y is present also
In addition to the four algorithms listed above, which all come with the base Automated Analytics licensing, there are optional advanced extensions called Social and Recommendation, which both work to analyze network-based data, visualized in
Figure 42. In network-type data, the main data elements are the linkages (represented by the lines between the individuals represented by blue dots in
Figure 42), but, optionally, there can also be additional descriptive attributes about the individuals that can also be incorporated into the model. Network-based models take into account graph-based attributes to determine which nodes might be more influential in attracting others (Social) or to assist in determining which products, offers, or messaging might be most effective based on experience with other closely related individuals (Recommendation).

Figure 42
Illustration of network-type data
While the core algorithms Automated Analytics provides are relatively simple to understand, the implementation of these algorithms is really quite sophisticated. Automated Analytics leverages a proprietary algorithm for regression that leverages Vapnik’s Structural Risk Minimization technique. That technique attempts to balance model accuracy with its ability to generalize to other scenarios. Put more simply, it ensures that the model is not over-fitting itself to have high accuracy on one particular dataset, and ensures that the results remain consistent when run on new, independent samples. The chart in
Figure 43 illustrates the trade-off between under- and over-fitting and highlights the point of error minimization.

Figure 43
Structural risk minimization illustration
This algorithm essentially runs many iterations of the model, testing different predictor sets and coefficients to determine the optimal mix of accuracy and reliability. For users, this translates to a highly automated modeling process in which the software is responsible for all variable selections and weighting. The user has very little input and avoids the repetitive trial-and-error process common to most modeling processes.
Modeling Workflow
One of the most popular features of Automated Analytics Modeler is its simplistic wizard-like modeling workflow. It requires users to interact with only two screens after identifying their dataset before a battery of automated model diagnostics are returned.
Figure 44 shows the dataset identification process, where the user simply points to a text file or database table.
Figure 45 shows Modeler’s automated analysis of the modeling variables and allows the user to revise any incorrectly identified data types.
Figure 46 is the only real-model configuration screen, on which the user identifies the correct target variable (if not properly auto-detected by Modeler) and any variables that should be excluded as predictors (most commonly these would be keys or other variables that would only be known after the target is determined).

Figure 44
Automated Analytics Modeler dataset import
Figure 45
Imported Data Description

Figure 46
Model candidate variable identification
The user does not even have to designate whether the response is categorical or continuous. Modeler automatically detects this and runs the proper algorithm. At this point, Modeler displays the model configuration and allows the user to launch the modeling process from the screen shown in
Figure 47.

Figure 47
Pre-launch screen
During this modeling process, Modeler runs multiple iterations of the model to not only fit weights to the predictors like other predictive tools, but also to select which predictors should be included in the model and to transform those predictors by automatically selecting optimal binning for continuous predictors. Most other modeling tools require the user to manually set binning cutoffs or, at most, to offer an algorithm for heuristically determining cutoffs prior to the predictive modeling algorithm. However, Modeler rolls all this functionality into a single algorithm module and is able to create a predictive model with little or no additional input or transformation by the user.
After the modeling process completes, Modeler displays the screen shown in
Figure 48, with a brief overview of the model run time, consideration set, and a high-level description of the accuracy. At this point, you can either explore the model diagnostic reports further or proceed to
Figure 49, where the model can be run on a new dataset, saved for later use, or exported, as discussed in later sections.
Figure 48
Model results overview
Figure 49
Using the Model
Model Diagnostics
Another popular feature of Automated Analytics Modeler is the comprehensive model diagnostic report that is automatically generated after the model runs.
Figure 50 shows one of the most common model diagnostic tools: the profit curve chart, which shows the profit curve for a perfect model (pictured in green), which would result if the model were able to perfectly predict every occurrence. The blue curve represents the best model that Automated Analytics Modeler was able to build. The red line represents a completely random model, or the point at which the model provides no benefit. The closer the blue curve gets to the green curve and the further away the blue curve is from the red curve, the better the model.

Figure 50
Profit curve diagnostic chart, showing perfect (green), estimated (blue), and random (red) profit curves
Modeler also has built-in exhibits that help explain which predictors are most indicative of the desired outcome.
Figure 51 shows the Maximum Smart Variable Contributions chart, which is an explanatory graphic to help decision makers and non-statisticians understand the weight of individual model variables. In this case, the chart shows that Job Type is the most explanatory factor in the model, followed by Empl(oyer) Type and age. There are additional versions of this chart that break down each of the levels within a predictor to show the direction and magnitude of the impact of each predictor level on the response.

Figure 51
Maximum Smart Variable Contributions model diagnostic chart
In addition to the diagnostic and explanatory exhibits discussed previously, Modeler also has some what-if type tools to help quickly develop a cost-benefit analysis for specific proposals.
Figure 52 shows a tool for a binary target model that shows the Confusion Matrix and a slider bar that allows the user to simulate different cutoff points for the model scores and evaluate the Type I (false positive) and Type II (false negative) error percentages.

Figure 52
Confusion Matrix and what-if scenario profit-estimation tools
In addition, the Cost Matrix portion allows the user to enter profit and loss estimates for each of the categories to estimate the overall profit improvement due to the model. The example scenario shown in
Figure 52 simulates a marketing campaign in which there is the opportunity for a $200 profit for a customer that accepts the offer, but a $15 cost for each prospective customer that is contacted.
In this scenario, a prospect that is predicted to respond and actually does respond (Predicted = 1, True = 1) yields a profit of $185 ($200 – $15 cost to contact), while a false-positive response (Predicted = 1, True = 0) yields a $15 loss due to the cost to contact. With these cost assumptions, using the model to determine which prospects to contact yields a gain of $402,000 on the total population of 8,335 prospects. There is also the option to Maximize Profit, in which the Modeler Confusion Matrix tool identifies the cutoff score that maximizes profit based on the cost matrix provided.
All these diagnostic tools are built in and instantly available to modelers. Most of the charts can be exported to PDF, PowerPoint, or Excel, which allows the modeling team to share model diagnostics with others quickly and easily. These built-in standard model reports are a major differentiator between Automated Analytics and many other common modeling tools.
Model Implementation
Once you have developed an Automated Analytics model that meets your needs, there are several options for implementation, shown in
Figure 53. Firstly and perhaps most importantly, it is possible to save the entire modeling process, which allows you to review fit exhibits, run the model on new data, or re-fit the model on an updated dataset at a later date. This would facilitate manual re-scoring of new datasets in the future.

Figure 53
Model Save/Export options screen
Another perhaps more useful feature is the ability to export the scoring algorithm in a variety of different coding languages, as shown in
Figure 54.
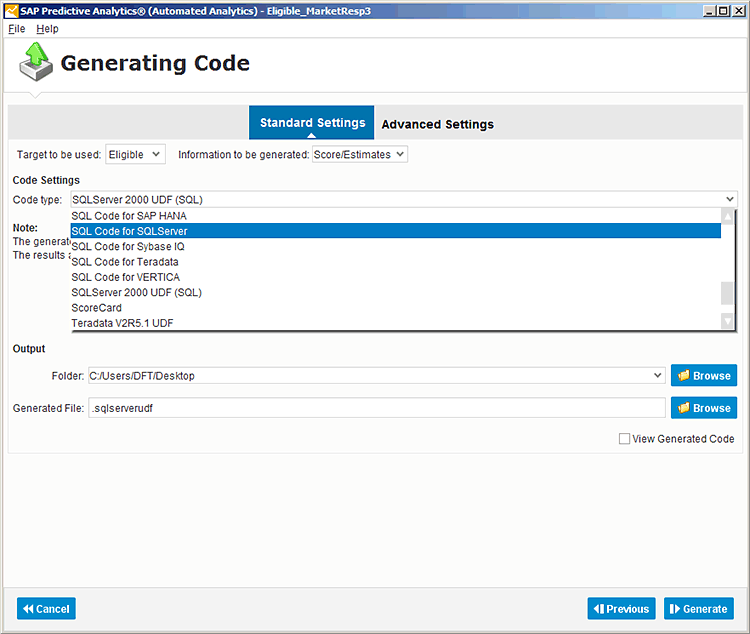
Figure 54
Partial list of scoring-code export options
The list of compatible languages is quite extensive and includes many variants of SQL (one example is shown in
Figure 55), Java code, C code, Visual Basic, and SAS code.

Figure 55
Model scoring-code output examples
There is also the option to export the scoring model to a JavaScript HTML widget, shown in
Figure 56, which can be used as an interactive-scoring tool for users to manipulate easily. With this easy code export, it is possible to quickly create a stored procedure within a database or a function within an application that can generate model scores within the application or database. Since this code is generated by Automated Analytics on demand, when the model is updated, new code can quickly be generated to update the external applications, minimizing the cost and effort when the model is revised.

Figure 56
JavaScript HTML scoring tool example
In addition to the export code and manual scoring option within the tool, it is also possible to export Automated Analytics models as script objects that can be called outside of the GUI interface via a command-line call. This is also the functionality used by Automated Analytics Model Manager to automatically run and re-fit models on a schedule. This offers an additional integration option with other applications that could interact with Automated Analytics directly via command-line calls without requiring human interaction through the GUI interface.
The Future for the SAP Predictive Analytics Toolset
Since the acquisition of KXEN’s Infinite Insight in September 2013, SAP has been working hard towards combining the Infinite Insight and SAP Predictive Analysis functionalities into a single predictive application. In February of 2015, SAP made the first release of its planned SAP Predictive Analytics 2.0 solution that will serve both the business analyst and data scientist roles within a single application. Ultimately, SAP Predictive Analytics 2.0 is expected to integrate the best of Infinite Insight and SAP Predictive Analysis offerings, both with the Infinite Insight algorithms and the ability to leverage R and Hadoop integration, while of course being optimized for SAP HANA. With the first release, Predictive Analytics 2.0 simply combines the installation packages for the former Infinite Insight and Predictive Analysis tools into a single package and re-brands both tools as sub-components under a single product line.
From a licensing perspective, the Predictive Analytics 2.0 product is licensed separately from any SAP HANA content, as it is part of the BusinessObjects suite. A license for Predictive Analytics 2.0 includes both the Automated and Expert modeling tools, and additional optional licenses for the Social, Recommendation, and data access drivers are available. SAP HANA integration is automatically available for Expert Analytics, although the SAP HANA system must be licensed separately from Predictive Analytics 2.0. The SAP HANA PAL and the automated predictive library (APL) algorithm engines are included with SAP HANA licenses, but the SAP HANA license alone only gives access to those engines via SAP HANA studio SQL code window or the Application Function Modeler (AFM), unless the Predictive Analytics 2.0 product is also licensed.
Architecture
The architecture for the future 2.0 solution is largely unknown, but SAP has announced the transfer of Infinite Insight algorithms into native SAP HANA functions as being a top priority. The APL was released as part of the AFL, which also houses the SAP HANA PAL algorithms. Like the SAP HANA PAL algorithms, the new APL algorithms allow in-database processing of the algorithms included in the Automated Analytics tool. Therefore, it is safe to say that SAP HANA will be the preferred solution for server processing, where users can leverage both Infinite Insight algorithms as well as SAP HANA PAL algorithms in a database. This also facilitates the use of R integration for a highly flexible and extensible solution.
A scenario that SAP has said is unlikely to occur is the ability to use an external R host in offline mode—in other words, rather than pointing the predictive client application to a local installation of R, using a higher-caliber server R instance for running predictive algorithms, even when not connected to SAP HANA. If SAP does not support an external R server, shifts all the Automated Analytics algorithm processing to SAP HANA, and does not maintain the existing Automated Analytics server architecture, organizations that do not have SAP HANA will be very limited in terms of processing power and potentially algorithm selection.
Another feature that SAP has announced as a priority is making the new generation of predictive tools cloud ready. This could potentially facilitate predictive solutions that are easier than ever to integrate into on-site and cloud applications, and promises faster deployment of predictive models.
Visualizations and Model Evaluation
SAP will most likely leverage the visualization components from SAP Lumira within the new predictive application, as the current Automated Analytics application lacks any user-driven visualization functionality. SAP Lumira’s varied charts and usable interface then can combine with the algorithms in Automated Analytics. Currently, Automated Analytics has a battery of pre-canned model-output visualizations that can be exported to Excel, PowerPoint, or a PDF and provide a full accounting of the modeling data and performance. Look for these to leverage SAP Lumira visualization tools to improve their look and feel, and potentially also facilitate sharing these visualizations through SAP Lumira or SAP Lumira Cloud.
Model Deployment
While Expert Analytics already supports exporting scoring models as *.SPAR or *.PMML documents and exporting SAP HANA PAL-stored procedures directly to SAP HANA in SAP HANA online mode, expect SAP to leverage and potentially expand the existing model-export process in Automated Analytics Modeler in future predictive applications.
SAP should also support model management and versioning features, some of which are found today in Automated Analytics Model Manager, across algorithms to facilitate enterprise-level model deployment cycles.
Usability and Strategic Integration
One of the strategic plans for the predictive platform team is to integrate predictive and visualization features from SAP Lumira, Expert Analytics, and Automated Analytics with SAP line-of-business applications. This would provide baked-in enhancements for the application user without having to develop custom predictive models or understand complex statistical algorithms. These integrated solutions will provide line-of-business application users with value-add analytics focused on their particular use case. This is a more focused way for SAP to build value rather than trying to develop a full-function analytical tool that competes with market leaders that have been refining their toolsets for more than 20 years.
SAP has also announced its intentions to develop predefined analytic dialogs within the tool for common business needs in select vertical markets. This is a long-range planned enhancement, so no specifics have been announced, but this would most likely include guided, wizard-like configuration processes for common analyses such as customer segmentation, churn analysis, market-based analysis, or next-most-likely purchase rules. This is a strategic move to make the tool more accessible to non-data scientists and further expedite the predictive process.
SAP is pursuing both ends of the technical spectrum for Predictive Analytics, extending both the technical features with the generic R-code support, which can be used by coders and data scientists to run customized and unsupported algorithms, and also facilitating use by the less-technical business users through more automated visualizations and predictive dialogs.
For more information, go to the following sources:
CRAN:
https://cran.us.r-project.org/
Rserve on Rforge.net:
https://www.rforge.net/Rserve/
PMML:
https://journal.r-project.org/2009-1/RJournal_2009-1_Guazzelli+et+al.pdf
SAP Predictive Analysis Community:
https://scn.sap.com/community/predictive-analysis
PAL on SAP HANA:
https://help.sap.com/hana/SAP_HANA_Predictive_Analysis_Library_PAL_en.pdf
R installation on SAP HANA:
https://help.sap.com/hana/hana_dev_r_emb_en.pdf
DFT Predictive Analysis installation guide:
https://sapbiblog.com/2013/04/15/sap-predictive-analysis-installation/
SAP HANA to support PMML import soon:
https://www.saphana.com/community/blogs/blog/2013/04/04/the-latest-announcements-about-sap-hana-platform-capabilities-understand-the-broad-scope-of-sap-hana
https://websmp209.sap-ag.de/~sapidb/011000358700001160102012E.pdf
Hillary Bliss
Hillary Bliss is the analytics practice lead at Decision First Technologies and specializes in data warehouse design, ETL development, statistical analysis, and predictive modeling. She works with clients and vendors to integrate business analysis and predictive modeling solutions into the organizational data warehouse and business intelligence environments based on their specific operational and strategic business needs. She has a master’s degree in statistics and an MBA from Georgia Tech. You can follow here on Twitter
@HillaryBlissDFT.
Hillary will be presenting at the upcoming SAPinsider Customer Engagement & Commerce 2017 conference, June 14-16, 2017, in Amsterdam. For information on the event, click
here.
You may contact the author at
Hillary.Bliss@decisionfirst.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.









