/IT/HANA
Get a first-person account of an SAP HANA installation, including initial impressions with the software’s features, challenges encountered during the implementation, and lessons on SAP HANA’s integration with SAP BusinessObjects BI tools.
Key Concept
SAP HANA Studio is the primary client tool used to manage SAP HANA and to create analytic views. It contains database administration tools, security management tools, and developer tools.
I have been working with an SAP HANA instance now for about three months. As you can imagine, I was eager to get the system set up, explore all the moving parts, and build content to test its capabilities. For the past year, SAP marketers and evangelists have been touting SAP HANA and painting pictures of its capabilities and features, but now it was my turn to test drive the system of the future.
Given that the technology was developed under the leadership of SAP, some of you might have the misconception that SAP HANA is only for companies that have SAP ERP or SAP NetWeaver BW systems. Given that I have devoted the last 10 years to using SAP Crystal Reports and SAP BusinessObjects outside the sphere of SAP’s existing products, I wanted prove that SAP HANA could be used by companies that have not invested in SAP systems.
With that said, those that plan to use SAP HANA with their SAP systems can also gain insight into how to use SAP HANA with SAP BusinessObjects Data Services and SAP BusinessObjects BI 4.0. This article chronicles my experiences and first impressions of SAP HANA. I guide you through an end-to-end process during which I installed and configured SAP HANA, loaded data into SAP HANA using SAP BusinessObjects Data Services 4.0, and used SAP BusinessObjects Enterprise 4.0 to visualize SAP HANA’s analytic capabilities.
Based on my initial impressions, SAP HANA is an impressive mix of software and hardware. After spending a few hours racking the massive 8U SAP HANA server, I booted the SUSE Linux OS and explored the file system. I quickly located the 640 GB PCI-X flash IO Accelerator card mount point and the mount point for the 3.5 TB persistent storage array. The mount points for these storage devices are critical to the installation of SAP HANA software. The log files had to be processed at 200k+ IOPS on the IO Accelerator card, and the persistent storage had to be processed on the 4k IOPS 3.5 TB array. Outside of identifying these mount points, the installation of SAP HANA was a breeze. In comparison to my past experiences installing Oracle and IBM DB2 databases, there was little post-installation configuration required.
The SAP HANA Studio Is Your Starting Point
After completing the SAP HANA database software installation, I installed SAP HANA Studio on my laptop. I also installed both the 32-bit and 64-bit ODBC drivers. However, these are not required to run SAP HANA Studio. Once I completed the driver and studio installations, I had no problem connecting to my newly installed SAP HANA instance over the network.
I am impressed with how easy and intuitive SAP HANA Studio is to navigate. Within minutes, I had created a new user and schema to store my data. I then made a second connection to SAP HANA, using my new user, to reset the initial password. I invested a few hours looking around SAP HANA Studio at all the different options and tools contained within. SAP HANA Studio is similar to many of the database management tools on the market today and as a result, I had no problems identifying the numerous options available within the GUI.
SAP HANA Studio helps you manage users and security, review key system metrics, execute SQL statements, develop data views, model data, and take other actions. The tool itself appears to be based on Java Eclipse, which makes it possible to run on Windows and Linux operating systems. There are several perspectives that provide access to different actions and views within SAP HANA Studio. In general, perspectives provide access to the components and tools within SAP HANA Studio. The Administration Console is the perspective in which database administrators will spend most of their time (Figure 1). It also provides an interface for executing SQL statements.
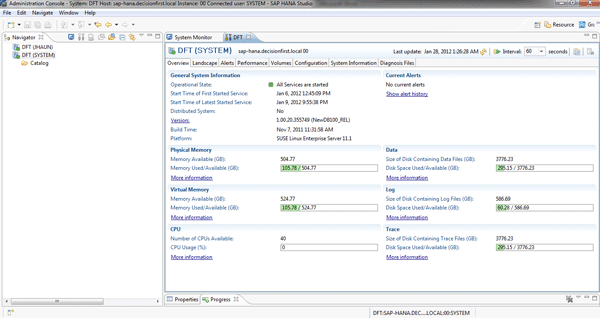
Figure 1
SAP HANA Studio Administrative Console
The Modeler perspective provides tools for developers to create OLAP-style views for data access by many of the SAP BI tools (Figure 2). There are other perspectives available, but they did not appear to be relevant to how I planned to use SAP HANA.
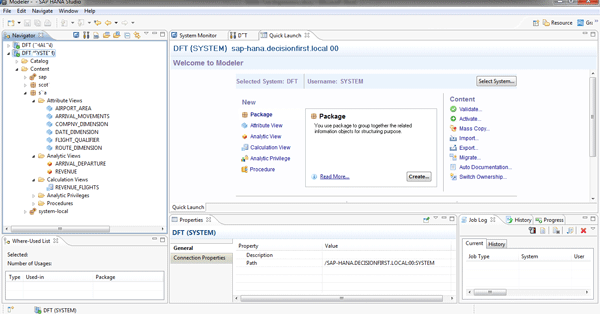
Figure 2
SAP HANA Studio Modeler
I then turned my attention to loading data into my schema using SAP BusinessObjects Data Services 4.0. The 4.0 version included the native SAP HANA DataStore connections that I needed to easily and quickly bulk load data into my schema. To fully enable SAP HANA support, I installed the 64-bit ODBC SAP HANA driver on the SAP BusinessObjects Data Services Job Server and configured the ODBC DSN (Figure 3). I also installed the 32-bit driver to support my 32-bit SAP BusinessObjects Data Services designer client. Within a few minutes, I had successfully configured a DataStore connection to my SAP HANA schema. The goal was to load a real-world, big data set to SAP HANA. I chose to use a dataset that had a 500-million-row table that was approximately 55 GB uncompressed and about 15 GB with SAP HANA compression enabled.
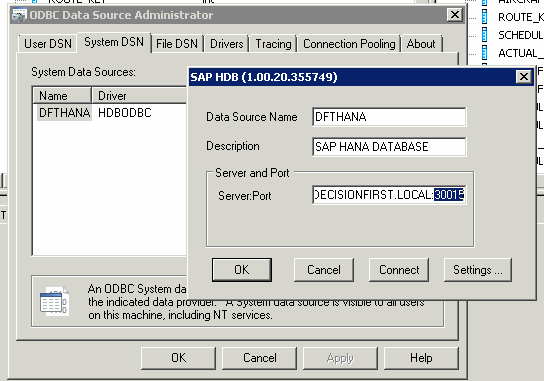
Figure 3
The ODBC connection configuration
The data flow that I used to load my big data table was based on an MS SQL server source and an SAP HANA target (Figure 4). I configured the target as a column store table, and I enabled bulk load. I must admit that I made several attempts to load the 500-million-row table. This was not due to any issues with SAP HANA or SAP BusinessObjects Data Services, but rather due to my insistence that the data load at around 10 million rows every two minutes. My initial bulk load settings were configured to commit the records every 10,000 rows. This proved to be problematic on a column store table. There were long pauses between each batch commit, and I was also only using a single SAP BusinessObjects Data Services loader.
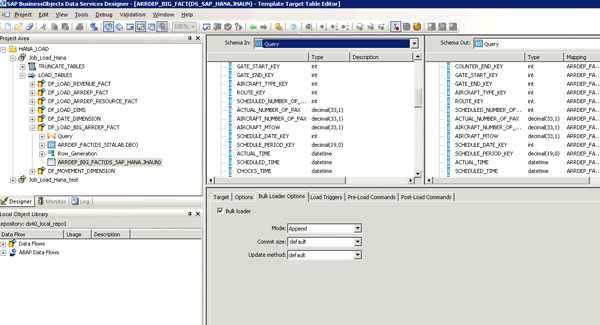
Figure 4
SAP BusinessObjects Data Services extraction, transformation, and loading flow
Based on my experience with other columnar database appliances, I knew that the database needed to recalculate the table with each commit. As each 10,000-row batch was committed, the delay increased almost exponentially. To work around this, I incorporated two techniques:
- Increase the batch commit size from 10,000 to 1,000,000
- Increase the number of parallel loaders that SAP BusinessObjects Data Services uses when bulk loading data to SAP HANA from one to five
I was now loading 5,000,000 rows concurrently to SAP HANA and reducing the delay associated with each commit cycle. After about one hour, the data was fully loaded for the large fact table. I then loaded several smaller dimension and fact tables to complete the load of the datamart.
Developing Attribute Views and Analytic Views
Now that I had a relatively big set of data, it was time to develop content that would calculate, aggregate, and slice and dice the data. SAP HANA offers an interface that not only provides light data modeling, but an OLAP-style interface that does not actually require that data be loaded a second time into an InfoCube.
This is a profound feature of SAP HANA. Most of the OLAP tools on the market suggest that data be processed and stored in an OLAP InfoCube after it has been loaded to star schema relational tables. Because SAP HANA stores data in-memory — compressed and in a columnar table store — there is no need to re-process the data into an InfoCube to gain superior performance. The OLAP of SAP HANA is simply metadata.
My first development task within SAP HANA Studio was to develop attribute views (Figure 5). Attribute view are the dimensions of SAP HANA’s analytic views. When developing attribute views, you have the option of joining one or more SAP HANA tables, choosing attribute columns, creating attribute calculations, and defining hierarchies. Once activated, you can then join attribute views to analytic views. After creating several attribute views and hierarchies, I was ready to move on to the analytic views.
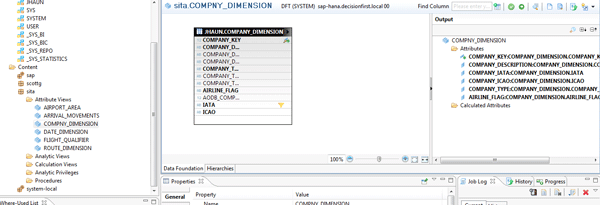
Figure 5
Attribute views
Analytic views are a mixture of measures and attribute views. At the heart of an analytic view are its measures. These are the values that exist in the fact or transaction table that must be summed, counted, and totaled. Analytic views are defined by joining the source table of the measures with active attribute views (Figure 6). Developers can create calculated measures within analytic views as well.
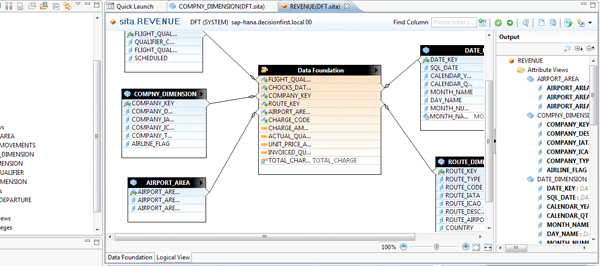
Figure 6
An analytic view joining a source table with active attribute views
It was at this point that I ran into another challenge. After activating my analytic view, I was unable to preview any data. The error indicated that the analytic view was not found in the database.
After hours of trial and error, it finally dawned on me that this might be a security issue. When analytic views are published, their metadata is stored in a system schema named _SYS_BIC. To allow this schema to access the underlying tables, you have to grant the _SYS_BIC schema access to the schema that stores your data.
I researched the SQL guide for SAP HANA and found the syntax for the command. After granting select access as required, I then ran into another issue. The key columns I was using to join my tables were defined as a decimal (23,0) within the DDL of my SAP HANA tables. This was due to the way that my source table was defined in the SQL server. Apparently SAP HANA analytic views and attribute views cannot be joined together on columns defined as the decimal type. More research on these issues is warranted, but I worked around the issue to avoid any delays. To resolve the issue, I updated the SAP BusinessObjects Data Services 4.0 dataflow to convert these values from decimal to integer. After making the changes and reloading the data, my analytic views started working.
Creating Analytics with BusinessObjects Universes
Now that my content within SAP HANA was fully functional, I turned to the various front-end tools within SAP BusinessObjects BI 4.0 to create analytics and to test the power of SAP HANA. To kick things off, I installed the 32-bit ODBC driver on my desktop to support SAP HANA connectivity within SAP BusinessObjects Information Design Tool (IDT), the replacement for the old Universe Designer. The IDT creates universes in SAP BusinessObjects BI 4.0. Universes are semantic layers that allow organizations to deliver data in an intuitive, graphical format. When universes are combined with the SAP BusinessObjects reporting tools, users are empowered to create and analyze data without needing to know how to write complex SQL statements. Many of the tools within SAP BusinessObjects BI 4.0 require the use of universes.
Connecting to SAP HANA with the IDT was straightforward. I installed both the 32-bit and 64-bit ODBC client on the SAP BusinessObjects BI 4.0 server. The server needs the 64-bit driver to support the 64-bit services. I installed the 32-bit driver just in case it was needed, too. Within the IDT, I created a connection based on the 32-bit ODBC DSN on my desktop. I then started a new IDT project, created a relational connection shortcut, and built my first SAP HANA-based foundation. Within the IDT foundation, I found that I had two options for connecting to my SAP HANA data:
The analytic views were located under the schema _SYS_BIC (Figure 7), while the base tables were located under the schema of the user I used to load the data into SAP HANA.
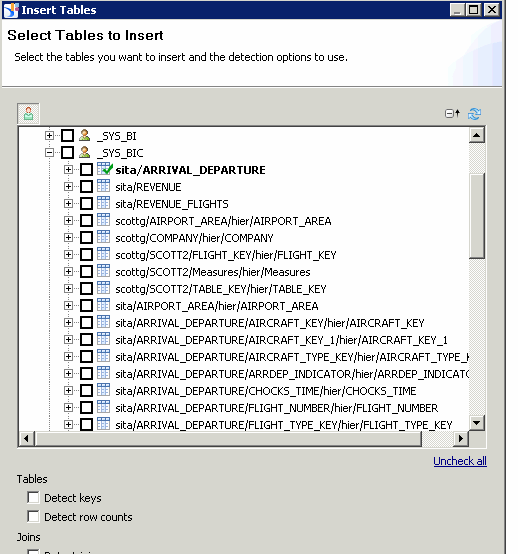
Figure 7
Analytic views within the _SYS_BIC schema
Given that I had two options, I decided that I would create two different universes: one based directly on the analytic views (Figure 8) and another based on the raw tables (Figure 9).
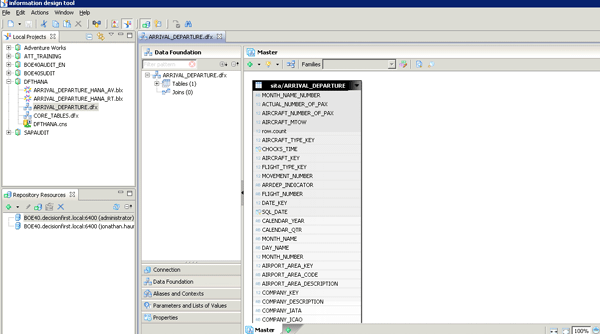
Figure 8
An IDT universe based on SAP HANA analytic views
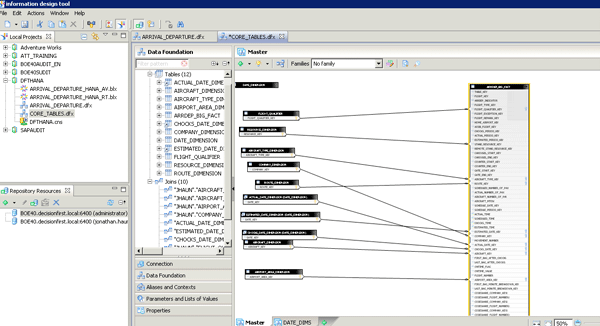
Figure 9
An IDT universe based on SAP HANA raw tables
The universe foundation and universe business layer, based on the SAP HANA analytic views, were simple to set up. The simplicity was a result of the modeling work I conducted within SAP HANA Studio. Effectively, the technical business logic was pre-built into the analytic views stored on SAP HANA, and the universe was able to leverage this. I only needed to make a few changes to my measures in the business layer and organize the dimensions into classes to make for a more intuitive ad hoc universe (Figure 10).
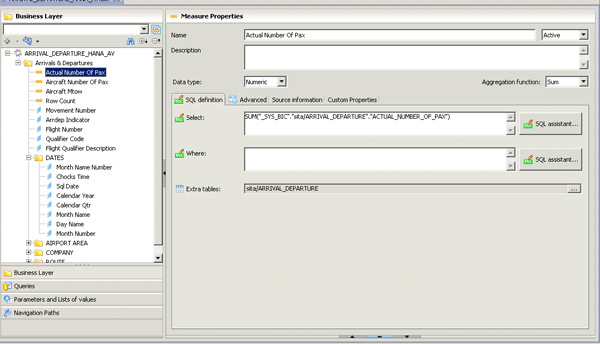
Figure 10
A universe business layer based on analytic views
The foundation based on the base tables required a bit more work (Figure 11). As with any traditional universe, I had to join the tables, define the cardinality, and identify the key fields. I did not add any prompts or filters at this layer to speed up the process. After defining the base table foundation, I created a standard business layer with classes, measures, and dimensions.
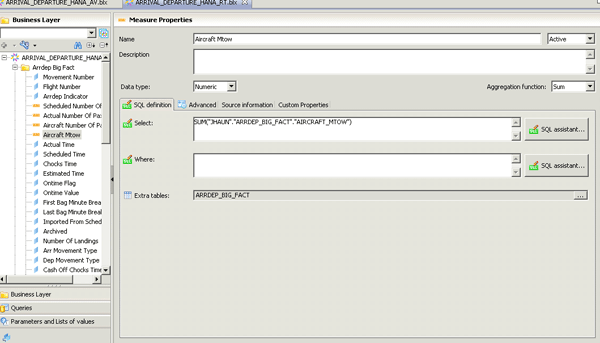
Figure 11
Universe business layer based on base tables
My reasoning for creating two universes was based on my desire to discover if there was any difference in performance when choosing to use analytic views or base tables in universe design. As I will describe later, there was no difference in performance. However, I can see how both options have pros and cons. After I have implemented several universes based on SAP HANA, I will provide SAPexperts with a more detailed list of recommendations, but for now I will only state that there is no observed difference in performance using either method.
Using BusinessObjects 4.0 to Develop Reports Against SAP HANA
With two sets of working universes completed, I was ready to start developing reports. Because I was accessing SAP HANA through a universe, I could choose from any reporting tool that supports a universe. My first choice was to test the ad hoc capabilities of SAP BusinessObjects Web Intelligence reports based on SAP HANA base tables and analytic views.
I developed two types of reports against each universe. The first Web Intelligence report was operational in nature. It listed details from the main 100-million-row fact table for a span of 10 days. I develop a standard report filter of start date and end date. As expected, the report refreshed in less than one second and listed about 60,000 rows of data. This proves that SAP HANA can quickly return detailed information to a report based on a big data table. SAP HANA is marketed as an analytic engine, but after working with hundreds of clients over the past six years, I know that operational data is also a need for end users.
The next report was developed with a more analytic approach. The report incorporated charts and summary tables at several levels of granularity to showcase how SAP HANA aggregates big data (Figure 12). The Web Intelligence report query was defined at the granularity of month, year, and company, and contained measures to count and sum the key metrics of the data I used. I did not incorporate any filters in the report because I wanted to see how quickly SAP HANA could power through unfiltered big data.

Figure 12
With Web Intelligence reports, SAP HANA aggregates big data
On other database technologies, querying data at this size would result in a 10-minute-plus query. To my amazement, SAP HANA returned the results in under two seconds. That was impressive considering that 15 years of data was aggregated faster than it takes most databases to crunch through six months of data. With the query execution complete and data in my data provider, I developed a few charts and tables to complete my analytical reporting test. The performance of SAP HANA was impressive. I saw no noticeable differences between the analytic views and base table universes. Given that the analytic views are nothing more than metadata, it was no surprise that analytic views performed as well as the base tables.
With the ad hoc reporting test complete, I created a few SAP Crystal Reports using the new SAP Crystal Reports for Enterprise client tool (Figure 13). The new client was able to connect directly to the IDT universes I had created. The experience with Crystal Reports was exactly the same as with Web Intelligence. The reports were able to return data quickly in both the operational and analytical tests. Given the charting capabilities of Crystal Reports, it is nice to know that there was no discernible difference in performance between Web Intelligence reports and Crystal Reports based on a universe.
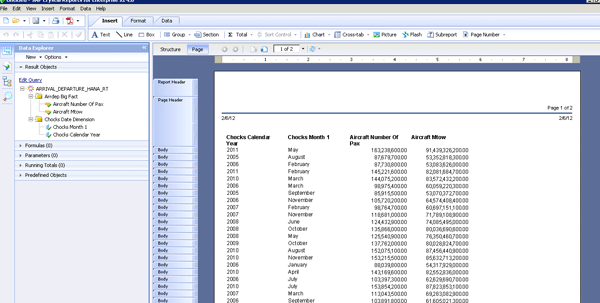
Figure 13
A Crystal Report based on SAP HANA base tables
How HANA Affects BusinessObjects Explorer Information Spaces
My final test was based on using SAP HANA to power an SAP BusinessObjects Explorer 4.0 information space. SAP BusinessObjects Explorer 4.0 allows users to quickly and effortlessly investigate and analyze datasets. The standard process for creating an information space involves the creation of a query based on an IDT universe. Once the query is finalized, an SAP BusinessObjects Explorer administrator then schedules the query to execute and cache the data on the SAP BusinessObjects Explorer server. When the data is fully indexed and cached, users can access the results with an intuitive UI that supports PC Internet browsers, iPads, and iPhones.
During the build process, data is copied from the source database, cached on the SAP BusinessObjects Explorer server disk drive, and then indexed to provide fast response time. While this might seem like a sound approach, most companies find that analyzing the information is not possible or practical when big data is involved. The process of caching and subsequently accessing the data is disk input/output and CPU intensive. The problem is largely due to standard enterprise disk drives being configured on the Explorer server. Most enterprise-class magnetic drives simply do not produce enough inputs and outputs per second to process big data in real time. This is true even if your storage is based on high-end SAN technologies.
SAP appears to have overcome this limitation by integrating SAP BusinessObjects Explorer with SAP HANA. When SAP HANA powers an Explorer information space, the back-end processes are executed very differently. For starters, I did not connect to an IDT universe within the BusinessObjects Explorer Manager (Figure 14). If an SAP HANA relational connection exists in the repository, a new option appears when managing SAP BusinessObjects Explorer spaces. Once expanded, the option reveals the list of analytic views I created in SAP HANA Studio. With an analytic view selected, I then developed a query to configure my Explorer facets and measures.
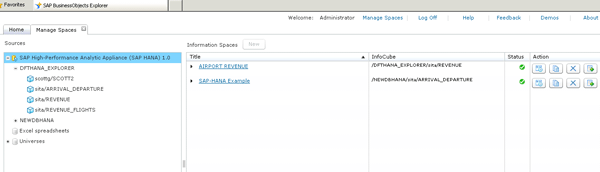
Figure 14
Connecting SAP BusinessObjects Explorer to SAP HANA
I saved the query and returned to the interface to schedule an index build. I executed the index build and within seconds, the results were ready for me to explore. When SAP HANA is integrated with SAP BusinessObjects Explorer, the data is not copied to the Explorer server. Instead, it remains on the SAP HANA server in RAM.
Because the data is processed in memory, the big data bottlenecks of traditional SAP BusinessObjects Explorer information spaces are eliminated, and users are now able to explore information spaces with hundreds of millions of rows. In my opinion, this is a powerful combination of SAP technologies. Companies can benefit from this ability to analyze detailed data to objectively identify the variables that impact their business.
The SAP BusinessObjects Explorer setup process was not without problems, however. Given that my information spaces contained more than 100 million rows of data and some of my facets only contained a Yes or No value, you would expect a return of big numbers when it is not highly filtered. My first attempt at viewing my SAP HANA-based information space returned an error. The error indicated that there was a numeric overflow in my measure calculation.
At first glance, I thought there was a problem with my setup, but I was not able to identify any issues. I then returned to SAP HANA Studio to run a few SQL statements that mirrored my SAP BusinessObjects Explorer dataset. In the studio, I received an error that provided more information. It was now clear what the problem was. One of the columns I had defined as a measure was defined as database type decimal (14,2). This effectively means I can store 14 numbers to the left of the decimal and two numbers to the right of the decimal. While this is more than sufficient for storing the value in each row, when this column is aggregated across 100 million rows, the result is larger than the allowable storage. To fix this issue, I updated my SAP HANA table DDL by increasing the size of all my decimal columns from (14,2) to (34,2). After making the change, I returned to SAP BusinessObjects Explorer, re-indexed the data, and viewed my information space without any errors (Figure 15).
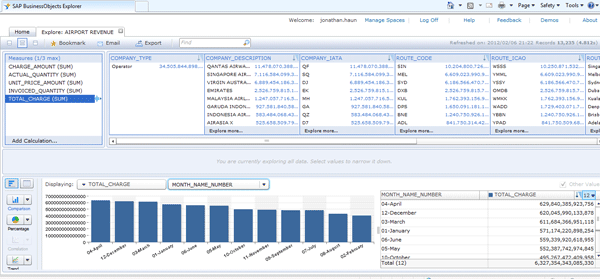
Figure 15
An end user’s error-free view of an information space
Final Thoughts
I had now finished all the tasks that I had started out to complete. My understanding of SAP HANA and its capabilities has moved beyond the marketing buzz and into hands of experience. I proved that SAP HANA, in cooperation with SAP BusinessObjects tools, can be used by companies that have never invested in an SAP ERP or SAP NetWeaver BW product.
The performance was beyond all expectations when I began analyzing my datasets. I was able to change measures, facets, filters, pivots, and rankings with sub-second response times. Given the size of the underlying data, this was an impressive experience.
Jonathan Haun
Jonathan Haun, director of data and analytics at Protiviti, has more than 15 years of information technology experience and has served as a manager, developer, and administrator covering a diverse set of technologies. Over the past 10 years, he has served as a full-time SAP BusinessObjects, SAP HANA, and SAP Data Services consulting manager for Decision First Technologies. He has gained valuable experience with SAP HANA based on numerous projects and his management of the Decision First Technologies SAP HANA lab in Atlanta, GA. He holds multiple SAP HANA certifications and is a lead contributing author to the book Implementing SAP HANA. He also writes the All Things BOBJ BI blog at https://bobj.sapbiblog.com. You can follow Jonathan on Twitter @jdh2n.
You may contact the author at jonathan.haun@protiviti.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.





