Explore critical topics shaping today’s SAP landscape—from digital transformation and cloud migration to cybersecurity and business intelligence. Each topic is curated to provide in-depth insights, best practices, and the latest trends that help SAP professionals lead with confidence.
Discover how SAP strategies and implementations vary across global markets. Our regional content brings localized insights, regulations, and case studies to help you navigate the unique demands of your geography.
Get industry-specific insights into how SAP is transforming sectors like manufacturing, retail, energy, and healthcare. From supply chain optimization to real-time analytics, discover what’s working in your vertical.
Dive into the most talked-about themes shaping the SAP ecosystem right now. From cross-industry innovations to region-spanning initiatives, explore curated collections that spotlight what’s trending and driving transformation across the SAP community.
Explore critical topics shaping today’s SAP landscape—from digital transformation and cloud migration to cybersecurity and business intelligence. Each topic is curated to provide in-depth insights, best practices, and the latest trends that help SAP professionals lead with confidence.
Discover how SAP strategies and implementations vary across global markets. Our regional content brings localized insights, regulations, and case studies to help you navigate the unique demands of your geography.
Get industry-specific insights into how SAP is transforming sectors like manufacturing, retail, energy, and healthcare. From supply chain optimization to real-time analytics, discover what’s working in your vertical.
Dive into the most talked-about themes shaping the SAP ecosystem right now. From cross-industry innovations to region-spanning initiatives, explore curated collections that spotlight what’s trending and driving transformation across the SAP community.
Drawing on his personal experience, the author clarifies how the R/3 system determines which summarization level to use. He then gives tips on how to use that information to design efficient summarization levels, and thus improve your system's report performance.
Summarization level is one of the most popular techniques for improving report performance in CO-PA. It was introduced with the 3.0C release and improved in recent releases. Summarization levels, which are presummarized data for specific characteristics, can improve performance dramatically if they are properly defined. However, improperly defined, summarization levels can burden a system to the extent that performance is considerably degraded.
One of the most frequently asked questions about summarization levels is how the R/3 system determines which level to use. You may think the system is going to use summarization level “X,” but it uses summarization level “Y” instead.
This article clarifies how the system determines the most suitable summarization level. It then will show you how to use that information to define the optimum summarization level and thus improve your report performance. This information, which comes from my personal experience, is not well documented elsewhere. If you need a refresher on summarization levels, see the sidebar “What Are Summarization Levels?” on page 13.
System Logic Determines the Summarization Level
When you execute a CO-PA report, the system displays an informational message at the bottom of the screen. The message indicates whether the system found a suitable summarization level. You have probably observed messages such as Read data from summarization level 310. So how does the system know which summarization level to use? R/3 follows these five steps to find the most suitable summarization level.
Step 1. The system finds all the characteristics that are required for aggregation in the report: characteristics from general data selection, characteristics used in report row/column definitions, and drill-down characteristics. These form the basis for further selection and requirements.
Step 2. The system finds all summarization levels that have at least all the characteristics listed in step 1, although the summarization levels can have more characteristics. The system marks these summarization levels as suitable. If a characteristic of the summarization level is defined as a fixed value (not as “*”), then that characteristic has to be explicitly defined in the report the same way. Otherwise, the summarization level is deemed not suitable to meet the requirements. For example, if a summarization level is created for customer group 01 and general data selection is for customer group 02, this summarization level is marked as not suitable.
Step 3. For each suitable summarization level identified, the system finds how many characteristics it has to summarize to get aggregated data, the total number of summary table records, and the last timestamp. The idea is to find which of these suitable summarization levels is optimal, as shown in Table 1.
Table 1
. The blank columns do not represent anything. They are included for comparison purposes only.Transactions stored in CE4, CE3, and CE1 tables
Step 4. Possible summarization levels are sorted by the number of characters needed to summarize (ascending), the number of records in the summary table (ascending), and the timestamp (descending), as shown in Table 2.
Table 2
Summarization level for customer
Step 5. Once the summarization levels are sorted, the system chooses the first summarization level, which is optimal for the required characteristics. In simple terms, the system tries to find the summarization level with the least number of “extra” characteristics (i.e., not required for display) and the fewest summary records. Let’s say your report requires customer group drill-down and you have two summarization levels, one with the customer group and another with a combination of the customer group and the product group. Although both can give data summarized by customer group, the first is the fastest.
If not defined properly, summarization levels may degrade system performance. With insight on how the system determines the optimal summarization level, you can design efficient summarization levels. The following are 10 best practices for designing summarization levels.
1. Include dependent characteristics in summarization levels. When you include a characteristic in a summarization level, you should include all the characteristics that are dependent on it. Adding dependent characteristics does not increase the size of the level, but may extend its useability. If you use the system proposal Extras>Proposal for>Reports, include dependent characteristics in the definition of summarization level.
For example, if you have included the characteristic “customer” in the summarization level, you should also include all characteristics that are derived from the customer master record (e.g., customer group). If the summarization level contains characteristics from the Sales and Distribution (SD) table KNVV of the customer master, the level should also contain the fields that make up the sales area (fields VKORG, VTWEG, and SPART). These fields are part of the key for the customer master.
If the key table has 1,000 unique customer records, even after you add the customer group in the definition of the summarization level, the key table still has 1,000 records. Summary table records also do not increase. On the other hand, the summarization level is more useable — for example, if you have a report with the customer group only as a drill-down characteristic, it could use the summarization level.
2. Do not include constant characteristic values in summarization levels. If a characteristic is a constant — i.e., it has only one possible value — you should either exclude this characteristic or include it with an asterisk (*) to indicate “all possible values.”
If the summarization level is defined for company code 0001, for example, then this company code must be defined in the report definition. Otherwise, the system thinks that this summarization level is not suitable. The rule is that if any constants (hard-coding) are in the definition, then these constant values must be defined in the report.
An exception to this practice is for the characteristic “controlling area.” In this case, you should not exclude it from the definition of summarization level if it is used in cost center assessment. For cost center assessment cycles, the controlling area is implicitly defined.
3. Avoid fixed characteristic values in summarization levels. In normal circumstances, do not include fixed values for characteristics in summarization levels. There is no advantage in defining four separate summarization levels for four separate company codes such as 0001, 0002, 0003, and 0004 (with the same definitions except for company code).
However, an exception occurs when one of the company codes (0001) is very large in comparison to the others, and you do not need a summarization level to analyze all company codes together. In this case, it may make sense to create one summarization level each for company codes 0001, 0002, 0003, and 0004.
Avoiding fixed characteristic values has a technical advantage, too, especially on Oracle databases. It is often difficult to build summarization levels, and the system causes terminations with error message ORA-1555 – snapshot too old. To avoid terminations, the system breaks down a SELECT statement on the CE4 table into multiple smaller SELECT statements. As a result, applications don’t keep the cursor open for long, and terminations are avoided. However, the statements are broken only if no conditions are specified for the CE4 table — i.e., fixed values are not used in the definition of summarization levels.
4. Maintain a moderate number of summarization levels (eight to 20 will suffice). Extensive use of summarization levels improves report performance dramatically. However, in their enthusiasm, customers may create too many. Eight to 20 summarization levels are always sufficient. For a simpler setup (e.g., one company code, one controlling area, one plant, one sales organization), four to six summarization levels should suffice. For more complex scenarios (e.g., a conglomerate with multiple legal entities and a resulting complex organization), it is not uncommon to have more than 20. This is not a hard and fast rule. The basic idea is not to overdo it because summarization levels occupy data space, and they have overheads, too.
5. Avoid redundant summarization levels. If one summarization level contains another, make sure the two are not too close to each other. Let’s say you have summarization level 0002, which contains all the characteristics of summarization level 0001. Typically, it does not make sense that summarization level 0002 would have only one or two characteristics more than SL 0001, and with very few extra records. In this case, summarization level 0001 is not very useful. Also, you should avoid a summarization level with nearly as many records as the segment level.
6. Build all summarization levels to have the same timestamp. It is advisable for all the summarization levels to have the same timestamp so that all have “current” status for consistency. If you have many summarization levels, it is advisable to build all the smaller summarization levels together in the first run and then build the larger ones. Once all the summarization levels have been built, update them again in one final run so that they all have the same timestamp. When you update all the levels together, you achieve the same time frame for all levels so that any two reports always have consistent data, even when they read it from different levels.
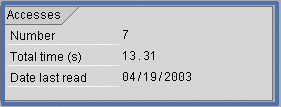
7. Delete older summarization levels. This sounds obvious, but you should delete older summarization levels that are not being used. In a dynamically changing environment, some of the summarization levels that were required in the previous year may now not be used at all. With the use of transaction code KEDV; check the Date last read status of the summarization level, as shown in Figure 1.
Figure 1
Checking when data was last read
8. Update summarization levels daily. It is usually sufficient to rebuild a summarization level once and to update it periodically. Do not update summarization levels more often than necessary. Usually once each night is sufficient.
9. Keep 30 minutes distance from mass data postings when updating summarization levels. To maintain consistency, the system does not include data records created in the last 30 minutes (this is termed a “safety delta”) when updating summarization levels. In that sense, the summarization level doesn’t include the exact totals. However, when the report is executed, the system adds these so-called “missing” records to show the correct result.
So that the report does not have to read many of these missing records, it is advisable to run the update job at least 30 minutes later than a typical mass update job (e.g., invoices creation). For example, let’s say your company has a periodic job of creating invoices at 10 p.m. daily and updating the summarization levels at 10:15 p.m. The summarization level keeps a safety delta of 30 minutes and includes only those records created before 9:45 p.m. The invoice records created at 10 p.m. are excluded, and every time you run a CO-PA report, the report has to read these missing lines. This affects report performance. In this case, it is advisable to run the summarization update job after 10:30 p.m. daily.
10: Periodically fine-tune your summarization levels. Periodically review the definitions of summarization levels and adapt the definitions to suit the recent changes in your organization. If you are changing the definition of summarization levels, make sure that the earlier reports are still able to use the new summarization level. When you change a summarization level expecting improvement, make sure nothing has fallen through the cracks. You can quickly execute earlier CO-PA reports to make sure R/3 displays the message that it is using a summarization level in the status screen. Also, it is a good idea to periodically check how the summarization tables are growing.
What Are Summarization Levels?
The primary purpose of a CO-PA report is to display information in aggregated (summarized) form. If the report has to read the CO-PA data from transaction tables and presummarize it in memory before displaying the data, it takes much longer. The CO-PA module is notorious for having a huge volume of transactions. The report performance can be improved if the presummarized data already exists, so that the system does not have to read transaction data. In short, summarization levels are presummarized data for selected characteristics. (For more information on summarization levels, see the article by Tony Rogan, “Improve Your CO-PA Response Speeds by Summarizing Your Users’ Data,” published in the April 2002 issue of FI/CO Expert.)
Note!
Although CO-PA reports are the primary candidates for using summarization levels, R/3 uses summarization levels in other functions also: cost center assessments to CO-PA, planning functionalities, and LIS-to-CO-PA interfaces.
Technical Structure
Transaction data in CO-PA is stored primarily in CE1xxxx, CE3xxxx, and CE4xxxx tables (where xxxx is the name of the operating concern).
• CE4 Segment table (profitability segments)
• CE3 Segment level (period totals for the profitability segments)
• CE1 Line items — actuals
Table 1 shows the CE1, CE3, and CE4 tables.
Table 1
. The blank columns do not represent anything. They are included for comparison purposes only.Transactions stored in CE4, CE3, and CE1 tables
If no suitable presummarized data is available, the system reads data from the CE3 and CE4 tables. It is easier to understand the CE4 table as a key table, and the CE3 table as a summary table.
Summarization Levels — Data Structure
Summarization levels are further summarizations of CE3 and CE4 tables. Similar to the CE4 (segment table) and CE3 (segment level) tables, a summarization level consists of two tables: a key table and a summary table. The key table corresponds to the segment table and contains the characteristics that are defined for the summarization level. The summary table contains totals of value and quantity fields. The summary table also contains the characteristics period (PERIO), fiscal year, and record type (VRGAR).
Table 2 shows how summarization levels further summarize the CE3/CE4 data. Therefore, when the CO-PA report accesses summarization levels, it needs to access fewer records to display the aggregated information.
Table 2
Summarization level for customer
Summarization levels for costing-based CO-PA are storedin tables K81nnnn, where nnnn is a four-digit running number. Key tables have an odd nnnn and totals tables have the next even number.
Table 2 shows the data in CE3 and CE4 tables. Even if the report is required to show data for the customer only, it still needs to read data for products too. The key table and summary table show the summarization level created for the characteristic “customer.” Now, with the help of the summarization level, the same CO-PA report has to read many fewer records to display customer information.
How to Build Summarization Levels
Unlike CE3 and CE4 tables, which are automatically populated by the source transactions, summarization levels need to be defined and updated manually. You can define summarization levels based on your requirements by transaction code KEDV, as shown in Figure 1. It is always easier to let the system propose the summarization level
Figure 1
Checking when data was last read
(if the option is available) and then fine-tune it. Once it is defined, you need to update the new summarization level with program RKETRERU (option Build new levels). Periodically, you also need to update summarization levels with program RKETRERU (option Update).
Drawing on his personal experience, the author clarifies how the R/3 system determines which summarization level to use. He then gives tips on how to use that information to design efficient summarization levels, and thus improve your system’s report performance.
Access exclusive SAP insights, expert marketing strategies, and high-value services including research reports, webinars, and buyers' guides, all designed to boost your campaign ROI by up to 50% within the SAP ecosystem.
Always have access to the latest insights with articles, Q&As, whitepapers, webinars, and podcasts. Gain the inside edge. The SAPinsider Weekly helps you stay SAP savvy. Access exclusive bonus materials, discounts, and more.