
Pitney Bowes Tracks 800M+ Parcels in Real Time with Fivetran

“When we introduced Fivetran to our facilities’ data processing, it revolutionized the flow and we were able to achieve near real-time data from all 16 sites at the same time. I can now understand all the site operational metrics in one single pane of glass and track an individual package to find out where it is currently.”
– Vishal Shah, Data Architect Manager at Pitney Bowes
Key results
- Gained near real-time visibility and analytics for 16 global distribution centers and 800M+ packages per day
- Achieved a 93 percent delivery estimate accuracy after a period of missed delivery SLAs, leading to new revenue-generating delivery guarantee program
- Reduced batch load times by 94 percent from 31 hours to under two hours
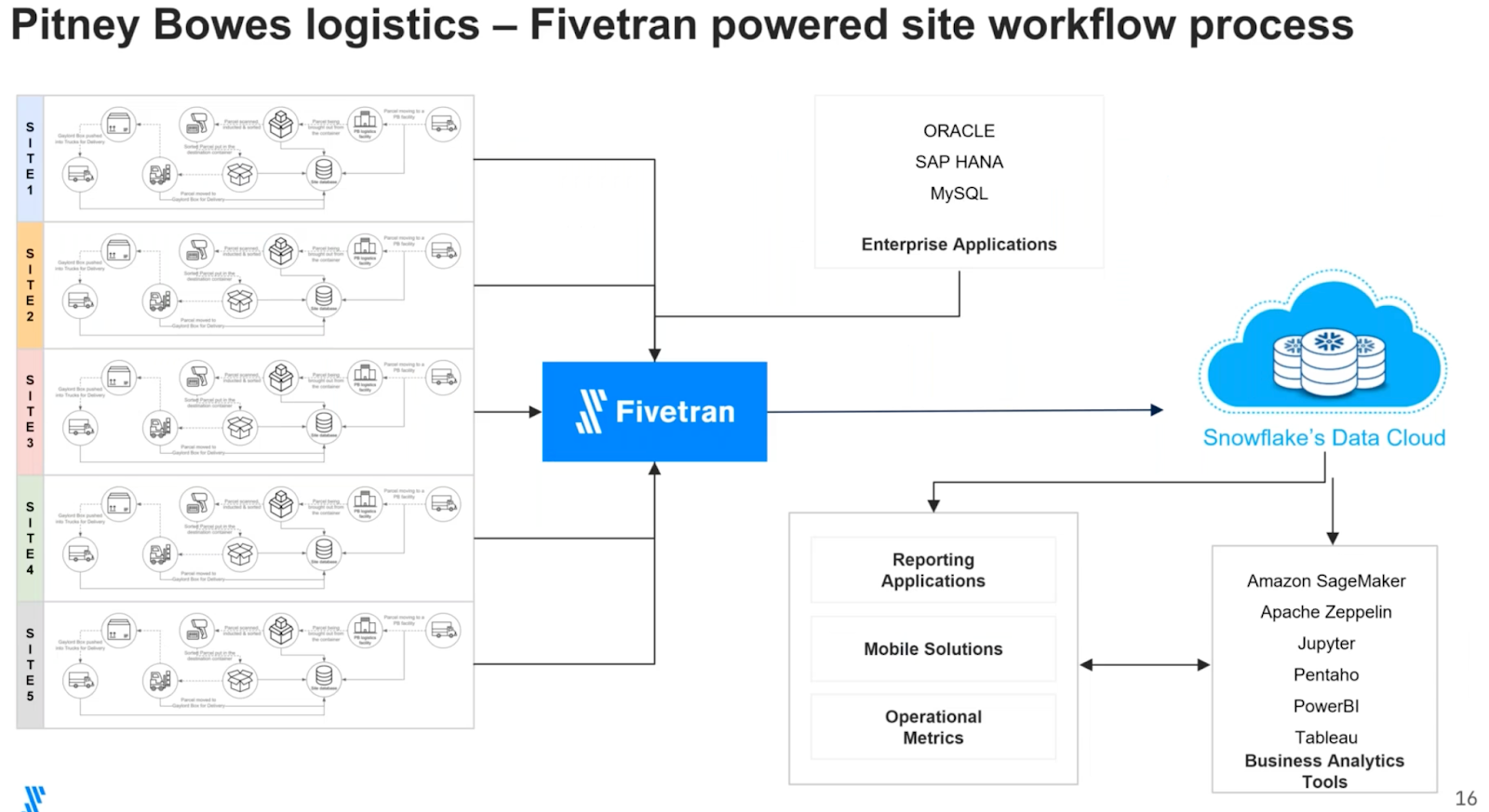
Pitney Bowes’ data stack
- Pipeline: Fivetran
- Destination: Snowflake
- Data sources: Oracle, MSSQL, SAP, MySQL, Kafka, Salesforce and dozens of SaaS apps
Pitney Bowes is a global technology company that simplifies the complexities of e-commerce, shipping and mailing. With over 11,000 employees, they manage 400 million mail parcels annually across 16 distribution facilities and serve 750,000 businesses worldwide.
Explore related questions
Thanks to their recent data stack modernization, Pitney Bowes can track every individual parcel and predict changes in mail volumes and therefore forecast labor needs on a per-facility basis. Its data forecasting helps its teams meet their shipping SLAs and provide up-to-date detailed visualizations that power their business decisions. To get here would have taken them years of hard work, but with the help of Fivetran and Snowflake they accelerated their modernization initiative
Unlocking valuable and transformative business data
Pitney Bowes lacked high-quality, real-time data they needed to make critical business decisions. Its Enterprise Information Management [EIM] team faced three challenges: siloed data, lack of scalability and inefficient tech spending. Employees tried to work around these constraints by pasting data into Excel spreadsheets for executive reporting and analytics — which often exacerbated the issues.
Data limitations were also causing downstream problems, like late-arriving packages that impacted SLA targets. They lacked the sophistication to detect delays and notify customers in time, causing reputational risk. The COVID pandemic magnified data challenges when online shopping increased tenfold — which meant a tenfold increase in parcel volume.
Event- and email-based data operations for 800 million packages per day were simply too much for Pitney Bowes’ legacy data infrastructure. The data captured was critical, but aggregating and consolidating it to the central analytics warehouse took days. By the time it reached the leadership team, the critical decision-making window had passed.
The EIM team built custom solutions but lacked the resources to eliminate cascading performance consequences. They tried to speed things up with expensive data center hardware and software to handle the load, but it wasn’t scalable, efficient or cost-effective. Vishal Shah, Data Architect Manager at Pitney Bowes, saw an opportunity to automate their data pipelines with Fivetran, centralize on Snowflake and leverage the ease and scalability of infinite cloud resources.
Goodbye constraints, hello real-time data
Moving to a cloud-based platform on Snowflake and Fivetran paid off quickly and eliminated multiple constraints.
Fivetran replaced all of its custom batch scripts and extract, transform, load (ETL) processes. Shah’s team used Fivetran’s out-of-the-box connectors to quickly build pipelines for several business-critical apps like SAP, Salesforce, Facebook, Kafka and Kinesis. Fivetran was working so well, the team decided to tackle the days-long data aggregation jobs.
Fivetran decreased one batch load from 31 hours to under two hours (a 94 percent reduction in time), and another from days to under one hour. This brand-new data flow efficiently collected and aggregated data from 700,000 IoT devices at 16 facilities. Even better, the custom script performance issues disappeared. Instead of querying databases directly and adding to the overall data processing load, Fivetran’s log-based change data capture (CDC) connectors capture all data changes and eliminate the processing load time and impact on the source systems.
Fivetran Local Data Processing helped Pitney Bowes move high volumes of data and eliminated its infrastructure bottlenecks. For the first time ever, they had efficient and real-time data delivery for all of our facilities, vehicles and parcels.
Productized financial data seamlessly from SAP
Many organizations face the challenge of leveraging data housed within SAP. Though SAP has a powerful ecosystem of products and services, not every company wants to build a data ecosystem around the SAP product stack. They have other source data they want to relate to their SAP data which is hard to do within the ecosystem.
Shah’s previous efforts to get SAP data into Snowflake ended in frustration. The more data they extracted, the more costs and delays increased. At best, Shah could only sync the SAP data to Snowflake once every two to three days — far too delayed for any real-time decision-making.
He leveraged Fivetran Local Data Processing to sync SAP data, and it was effortless. Fivetran’s SAP connector performed full syncs of high volume data to Snowflake in under seven hours — a 85 percent increase in performance. Now the team could sync at least four times a day with no performance impact on SAP systems.
Predictive analytics, operational efficiency and revenue growth
With the success of the SAP data integration, EIM is moving to make Fivetran the standard across the enterprise — from cloud-based SaaS apps to enterprise and transactional CRM systems like Oracle, IBM and DB2. Shah and his team quickly built a variety of innovative new products that transformed both Pitney Bowes’ and its customers’ abilities to plan for and predict growth.
One of the most exciting data products was a real-time operational analysis dashboard — a single pane of glass view into volume, labor and efficiency across all Pitney Bowes facilities. Executives could see and understand exactly what was happening across the entire business at one time. Facility managers could drill down to see parcel volume and assess corresponding labor capacity.
When the pandemic increased online shopping by a factor of 10, Pitney Bowes couldn’t keep up with the labor demand, leading to escalated SLA problems. Shah and team responded by determining proactive new metrics around predicted labor efficiency. They then built predictive dashboards for facility volume; network volume; estimated delivery and return dates; harmonized system (HS) product classification and delivery truck scheduling.
These dashboards could:
- Predict seasonality and upcoming volume to help site managers schedule labor in advance
- Determine the most efficient routes based on volume at a per-parcel basis
- Accurately estimate delivery dates to facilities and final destinations
- Mitigate risks of missed delivery dates before SLAs are missed
- Significantly reduce wasted truck capacity
The predictive truck scheduling capabilities have increased Pitney Bowes’ delivery estimate accuracy to 93 percent. They are also tracking health and observation data from their vast network of globally distributed IoT devices, allowing for new analysis and risk mitigation around hardware failures. Building on this data led to real-time tracking of any parcel anywhere across the globe — something that wasn’t possible before their Fivetran usage.
Finally, the updated data architecture provided the foundation for a new revenue-generating program called “Guaranteed Delivery.” Because Pitney Bowes could predict facility volumes and delivery dates, they could provide downstream delivery assurances through their vendors. They could even spot churn behaviors and mitigate that risk proactively.
Fivetran enabled Pitney Bowes to create incredible new business outcomes. Implementing Fivetran modernized Pitney Bowes’ entire data ecosystem, revolutionizing the flow of data across the entire business while eliminating all of their data performance issues. Their data team no longer has to deal with manual and unreliable ETL work, legacy processes, data proliferation or security risks. Instead, they enable innovation at the speed of business with reliable, fresh and trusted data.





