Christian Savelli describes the Dynamic Tiering option available starting with SAP HANA Support Package 9, which enables a more effective multi-temperature data strategy. It offers management of warm data content via the extended table concept, representing a major enhancement from the loading/unloading feature currently available.
Key Concept
The term extended table refers to tables logically defined within one application, but having their contents stored within a secondary application. This setup allows the primary application to save on storage while retaining access to the data as well as control over the metadata of the so-called extended tables. SAP HANA Dynamic Tiering introduces this concept to the SAP HANA application itself, by allowing selected SAP HANA tables to be defined as extended tables. SAP HANA’s main memory storage acts as the primary application while SAP HANA disk storage assumes the role of a secondary application. In other words, SAP HANA extended table contents are solely stored in the SAP HANA disk but are managed and can be accessed like any other regular SAP HANA table, albeit providing slightly slower data retrieval when compared to in-memory content.
Having data loaded into memory for rapid access and then replicated to disk for durability is the pivotal concept of the SAP HANA in-memory database. However, having all data loaded into memory all the time is not a feasible, cost-effective, or, in many cases, even a desired proposition.
A major contribution to this reality is that the rapid decrease of cost per gigabyte of memory observed in the last decade has been counterbalanced by an even larger, exponential growth of the data to be stored. In other words, more dollars are spent today on memory not because of its unit cost but because many more units of memory are required to store the massive amount of data being generated. However, even within this data avalanche it is important to address the simple fact that not all the data is to be deemed critical and required to be kept in-memory for super-fast access and analysis.
A multi-temperature data strategy is therefore crucial for managing data according to its relevance. It can help at the same time to promote a more effective allocation of SAP HANA memory resources, both RAM and disk based. As described in previous SAP Expert articles such as “
Understanding SAP NetWeaver BW Near-Line Storage (NLS) Based on Sybase IQ,” not all data stored within a data warehouse can be considered business critical.
Within the data-temperature spectrum (
Figure 1) there is data of a more static nature that is not frequently required by business users. This is typically associated with historical data for which criticality to current business processes has decreased in time. Examples include expired contracts, completed shipments, or financial transactions cleared several years prior to the current date. Data under these conditions is categorized as cold data. This is usually the data targeted for migration into Near Line Storage (NLS) solutions, such as SAP Sybase IQ, with the objective of freeing up the SAP HANA database for more business-critical data.
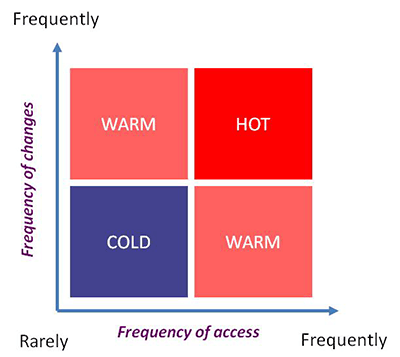
Figure 1
Multi-temperature data spectrum
Cold data apart, the remaining data residing within a SAP HANA database may also not be considered hot in its entirety. By definition, hot data means highly accessed data and, in several cases, data that is still undergoing frequent updates such as status changes. There are, however, cases in which data may be already static and only required on queries from time to time. This is a regular occurrence around historical data stored in dedicated yearly-partitioned providers. Other examples of not-so-hot data can include Persistent Staging Area (PSA) tables and write-optimized DataStore objects (DSOs).
PSA table contents are commonly used once, during data-intensive loading procedures, but frequently are required to be retained in the database for a certain period of time as a type of post-loading warranty. Another classic example of not-so-hot data is data stored within write-optimized DSOs that plays the critical role of a corporate memory layer.
Commonly used by large data volume companies that have adopted Layered Scalable Architecture (LSA) within their data warehouses, a corporate memory layer is comprised of a massive amount of write-optimized DSOs persisting data received from PSA tables based on a 1:1 field relationship with no data manipulation. The sole purpose of this layer is to allow re-loading of existent providers or initialization of new ones without impacting the source system delta pointers.
In all the examples mentioned above the data can be categorized as warm data content and may not be required to be retained in main memory.
Managing Warm Data Content
Next I explain how warm data content is currently managed in SAP HANA and how it is complemented with Dynamic Tiering.
Least Recently Used algorithms are currently used to manage in-memory SAP HANA content. This entails a procedure triggered by SAP HANA itself when approaching full main memory capacity. The most recently accessed tables or partitions are considered active content and are granted higher priority to remain in SAP HANA’s main memory. Tables not recently accessed are deemed non-active and therefore are primary candidates for displacement from main memory.
When a table is displaced from SAP HANA’s main memory its contents then pass to reside solely in SAP HANA disk storage. When a request is made to a table residing on disk, SAP HANA brings back to memory the specific content needed. In other words, not the entire table content is brought back to memory but rather the specific columns corresponding to the request being made. These columns, however, remain in memory even after the request has ceased and until space constraints trigger a round of automated unloading from main memory based on the Least Recently Used statistics.
It is possible to proactively prevent SAP HANA from approaching full main memory capacity and triggering Least Recently Used-based unloading procedures. This can be done via proactive monitoring of SAP HANA in-memory consumption via procedures, and by choosing to manually unload specific tables from main memory well in advance of any memory constraints. SAP HANA issues alerts of high memory consumption as part of its typical monitoring processes. Under the SAP HANA studio catalog, right-click an SAP HANA table and a context menu opens with several options (
Figure 2). In this case, select the Unload from Memory… option.

Figure 2
Manually unload tables from main memory in SAP HANA studio
To demonstrate the unloading procedure let’s consider a test table named Table_Test_1. Right-click this table within the catalog, and, in the context menu that opens, choose Open Definition, and then select the Runtime Information tab. In the screen that opens (
Figure 3) you can verify that currently this table consumes 306 KB of main memory and its replicated content in disk occupies 344 KB of SAP HANA disk space.
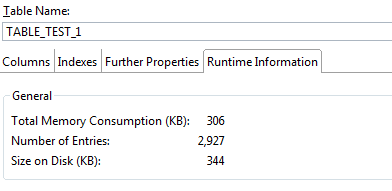
Figure 3
Run-time information for table TABLE_TEST_1 in SAP HANA studio
The next step is to unload table TABLE_TEST_1 from the main memory by right-clicking table TABLE_TEST_1 within the SAP HANA studio catalog and choosing the Unload from Memory… option. A message box opens (
Figure 4) informing you that the contents of table TABLE_TEST_1 will be unloaded from memory and alerting you to the fact that it will take longer to access this table as its contents need to be reloaded to memory during run time.

Figure 4
Warning message prior to unloading a table from SAP HANA's main memory
Click the OK button to unload the content of table TABLE_TEST_1 from main memory. After the unload is complete, refresh the run-time information by clicking the Refresh button at the top-right corner of the table definition (
Figure 5). You can then verify that table TABLE_TEST_1 is no longer consuming main memory space, but solely disk storage—it contains only 344 KBs of disk storage.
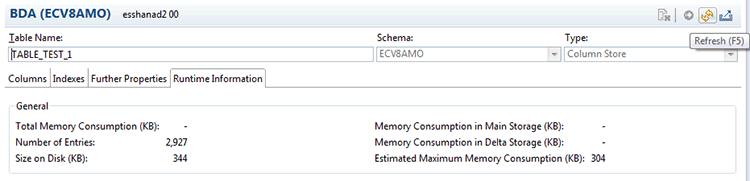
Figure 5
TABLE_TEST_1 no longer consumes main memory
The reverse is also possible. It is possible to load a specific table back to main memory by choosing the SAP HANA studio catalog Load into Memory… context-menu option (
Figure 2). By right-clicking table TABLE_TEST_1 within the catalog and selecting the Load into Memory… option, the contents in the disk are loaded into main memory in their entirety. The table contents now exist both in main memory as well as on disk.
SAP HANA Dynamic Tiering
Starting with SAP HANA Support Package 9, SAP provides a new option called Dynamic Tiering. The purpose of Dynamic Tiering is to provide improved management of the warm data content. This option introduces the extended table concept to SAP HANA as a self-contained solution that, in conjunction with an NLS solution such as Sybase IQ, complements the spectrum of data-temperature management.
In simplistic terms, Dynamic Tiering allows SAP HANA tables to be defined under a new category of tables named extended tables. These tables are available within the catalog, and can be modified, used for further modeling, or applied in SQL procedures. For all intents and purposes extended tables are like any other SAP HANA table. The difference resides in the fact that while SAP HANA tables are stored within main memory and replicated to the SAP HANA disk for durability, extended tables are solely stored in the SAP HANA disk.
Data writing to SAP HANA extended tables is performed directly to disk, not to main memory. When data is read from extended tables, optimized algorithms for data retrieval against SAP HANA disk storage are used, minimizing the impact to support-level agreements and latency requirements. Extended table contents therefore act as unloaded tables and only come to memory for caching and processing. In contrast, SAP HANA tables have read and write procedures performed directly to their main memory contents and then replicated to SAP HANA disk for durability. The comparison between the behaviors of SAP HANA tables versus SAP HANA extended tables is depicted in
Figure 6.

Figure 6
A comparison of SAP HANA in-memory table and SAP HANA extended storage tables
Operationally, the use of extended tables allows for more effective control over warm content by avoiding the undesirable permanence of having this data in main memory. With the former loading and unloading from memory feature, unloaded tables have certain columns loaded to memory when a request is made against it. These columns would remain in main memory occupying space until memory resource constraints trigger the next round of automated Least Recently Used displacement. On the other hand, the columns of extended tables are brought to memory only during run time and do not remain in main memory after use.
In terms of performance, comparative tests indicated that for a certain query selection made against SAP HANA in-memory content an average degradation of 40 percent on performance is expected for the same data selection if retrieved from NLS. Extended tables provide faster data retrieval than NLS and slower data retrieval than in-memory for the same query selection. A recommended rule of thumb is to consider the average of both, in memory and NLS, to estimate the performance against extended tables for your query scenarios.
How to Define Tables as Extended Tables within SAP BW on SAP HANA
In SAP BW 7.4, the option for defining a table as an extended table is available directly under the settings for PSA tables as well as write-optimized DSOs.
A write-optimized DSO can be set as an extended table by flagging the extended table setting during its definition within the SAP BW administrator workbench (transaction code RSA1). Only write-optimized DSOs without data can be set as extended tables. When defining the write-optimized DSO, expand the Settings sub-folder and flag the Extended Table – Table should be generated as extended table check box as shown in
Figure 7.
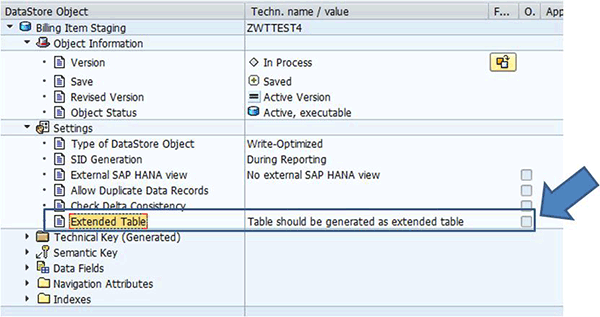
Figure 7
Define a write-optimized DSO as an extended table in SAP BW
For PSA tables, a similar configuration option is available. The PSA as extended table check box is available under the General Info. tab of a DataSource (
Figure 8).
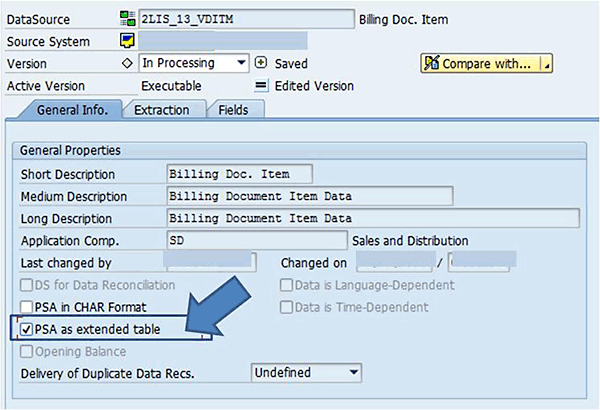
Figure 8
Define PSA tables as extended tables in transaction code RSA1
You can access the General Info. tab of a DataSource by right-clicking a particular DataSource within the SAP BW administrator workbench (transaction code RSA1) and choosing Display within the context menu, followed by clicking the change icon (
Figure 9).
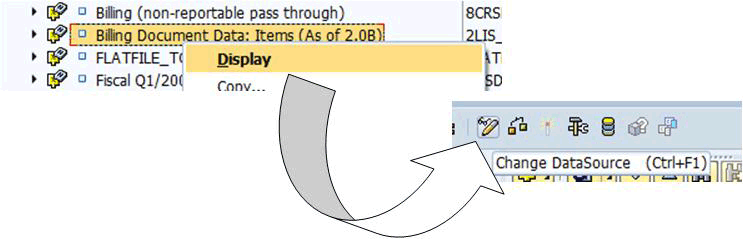
Figure 9
Access the General Info. tab of a DataSource in change mode
After the option PSA as extended table is selected and the DataSource is re-activated via the activate icon

, any new PSA volume is written directly to disk, bypassing SAP HANA main memory. In other words, new PSA volumes do not impact SAP HANA main memory during loading procedures. The benefit of this is that main memory is kept available for business-critical reporting and at same time protected against reaching peaks of use and triggering unnecessary displacement activities.
How to Define Tables as Extended Tables within SAP HANA Studio
SAP HANA tables can be created as extended storage tables by adding the clause using extended storage to the Create COLUMN Table statement, as shown in
Figure 10. After executing this SQL statement, Table1 is created as an extended table with the purpose of storing warm data.

Figure 10
Define a table as an extended table in SAP HANA studio
Existing SAP HANA tables can also be converted to extended tables by using Alter table SQL, by adding the using extended table storage clause as shown in
Figure 11. In this case, Table2 was originally created as an in-memory SAP HANA table. After executing this SQL statement, Table2 is converted into an extended table and no longer holds contents in main memory.

Figure 11
Convert an SAP HANA table into an extended table in SAP HANA studio
The same can be done in reverse—converting an SAP HANA extended table into an SAP HANA table as shown in
Figure 12. After executing this SQL statement, Table1 is converted into an SAP HANA in-memory table.

Figure 12
Convert an SAP HANA extended table into an SAP HANA table within SAP HANA studio
Final Considerations
Christian Savelli
Chris Savelli, senior manager at COMERIT, has been dedicated to SAP BI and Analytics projects since 1998. He holds multiple SAP certifications covering HANA, BW and ECC applications and has expertise in managing all aspects of the information creation process, utilizing SAP BI technologies to satisfy strategic, analytical and reporting needs. Chris Savelli started his career at SAP and subsequently held senior level positions at consulting companies Deloitte and Accenture. His education background includes a bachelor of science degree in robotics and a master of science degree in engineering both from the University of Sao Paulo, as well as a post-graduate diploma in business administration from the University of California at Berkeley.
You may contact the author at
csavelli@comerit.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.





